








方案详情
文
食品掺假和标签虚假行为可能会给消费者带来潜在健康风险并造成信任危机,对于高档葡萄酒产品而言尤其如此。目前的分析方法和防伪标签技术不足以确定这类产品的身份信息和原产地。本应用简报介绍了一种基于 Liang 等人的研究开发的追踪葡萄酒产品原产地的代谢组学分析方法。参比赤霞珠葡萄酒来自五家酒庄(两家为美国酒庄,三家为中国酒庄),并使用安捷伦 UHPLC-Q-TOF/MS 平台在准确的 TOF/MS 扫描模式下进行了初步分析。所得原始数据通过分子特征查找提取方法进行了数据挖掘。将结果导入 Agilent Mass Profiler Professional (MPP) 化学计量学软件,以在各组之间查找特征化合物。所得差异化合物的主成分分析和聚类分析显示了该系统区分两组美国葡萄酒与中国产葡萄酒的能力。基于这些数据的偏最小二乘差异分析 (PLSDA) 模型能够高度准确地预测葡萄酒组别。通过使用针对葡萄酒的自定义多酚类化合物数据库和谱库以及其他可用的安捷伦 PCDL,我们对 23 种化合物进行了初步鉴定,其中大多数为葡萄中的内源性代谢物,表明在不同原产地的葡萄酒中,葡萄代谢物是区别葡萄酒主要特征的决定因素。本研究证明采用 UHPLC-Q-TOF/MS 结合化学计量学分析的代谢物组学分析方法是追踪葡萄酒原产地的有用方法。
方案详情

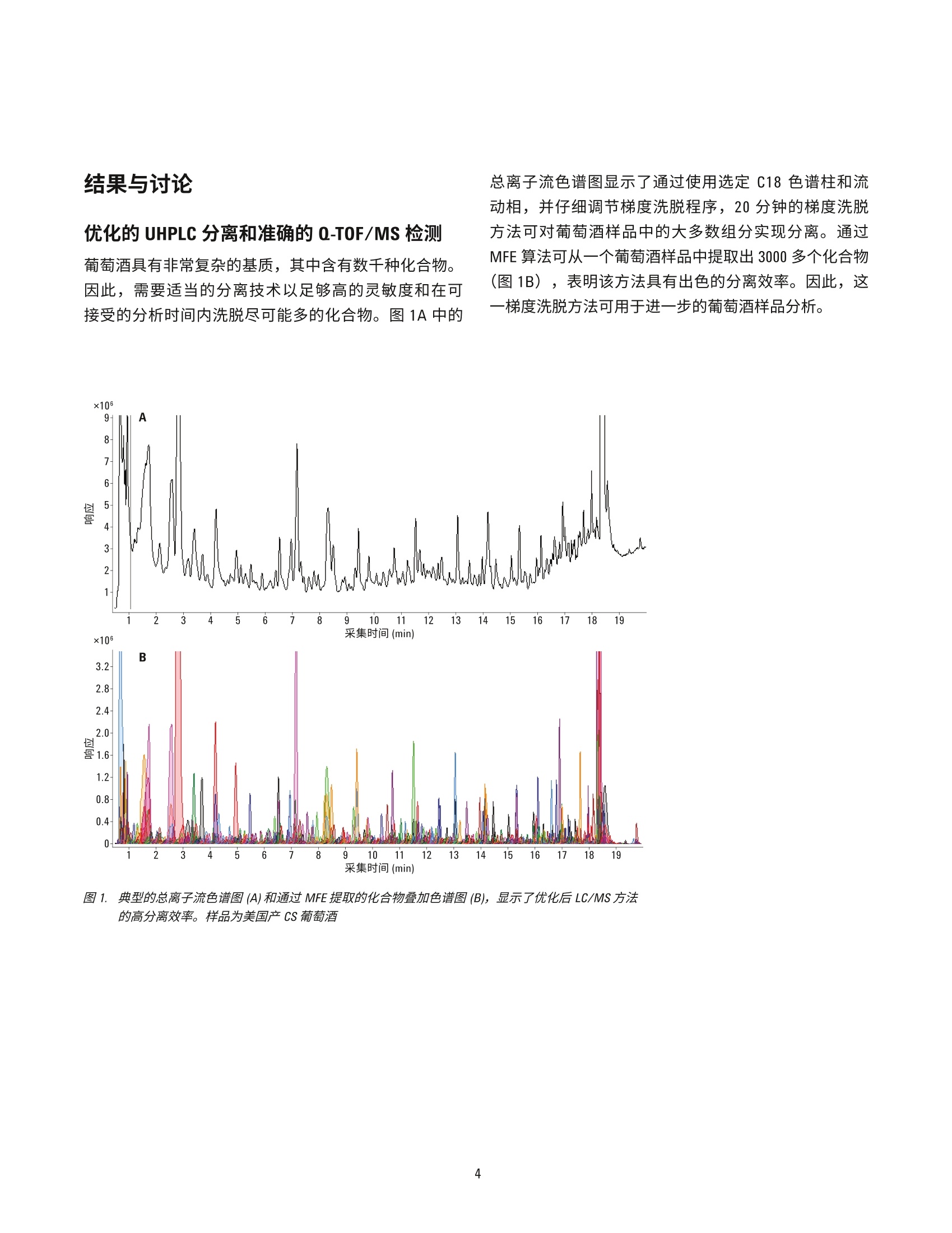
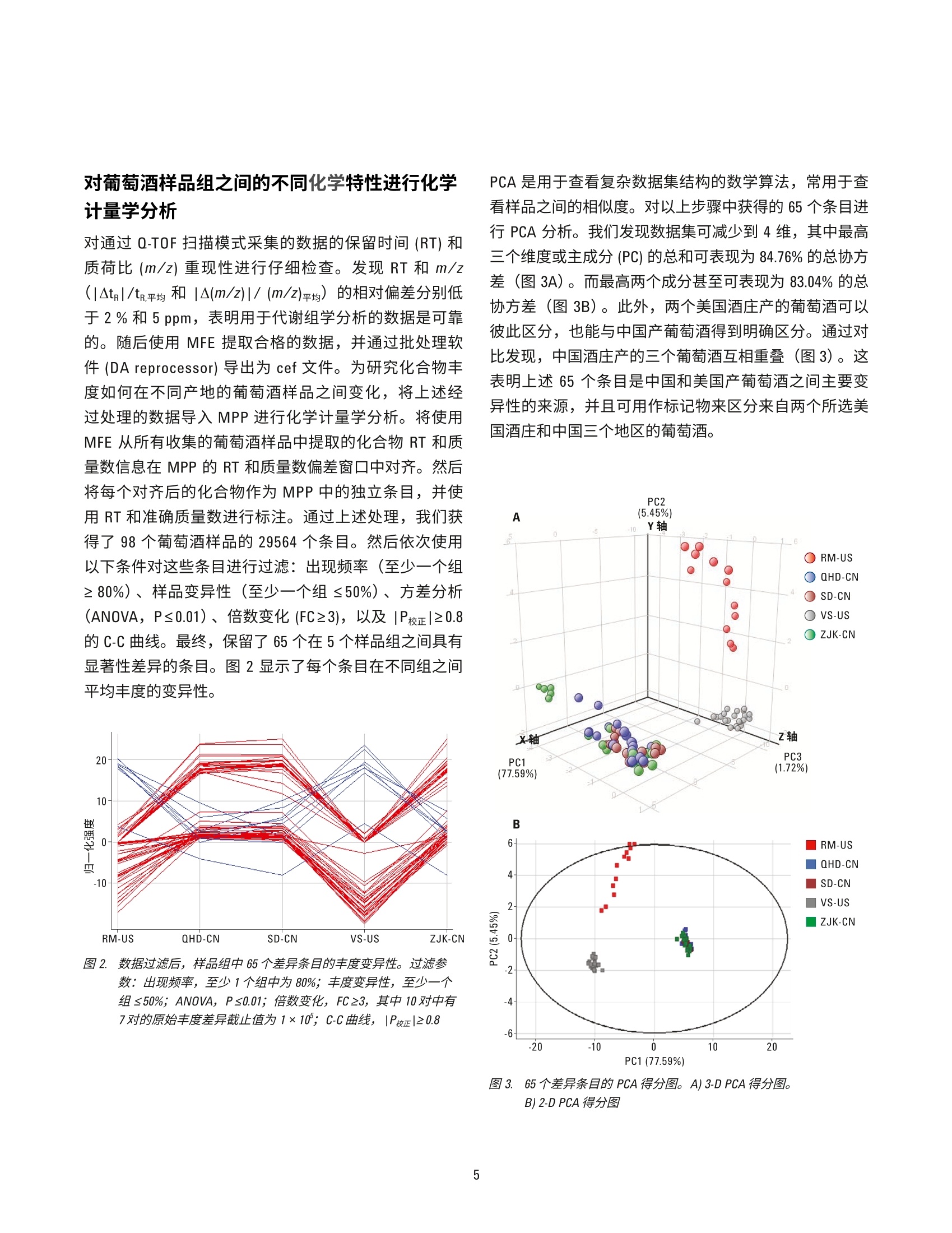
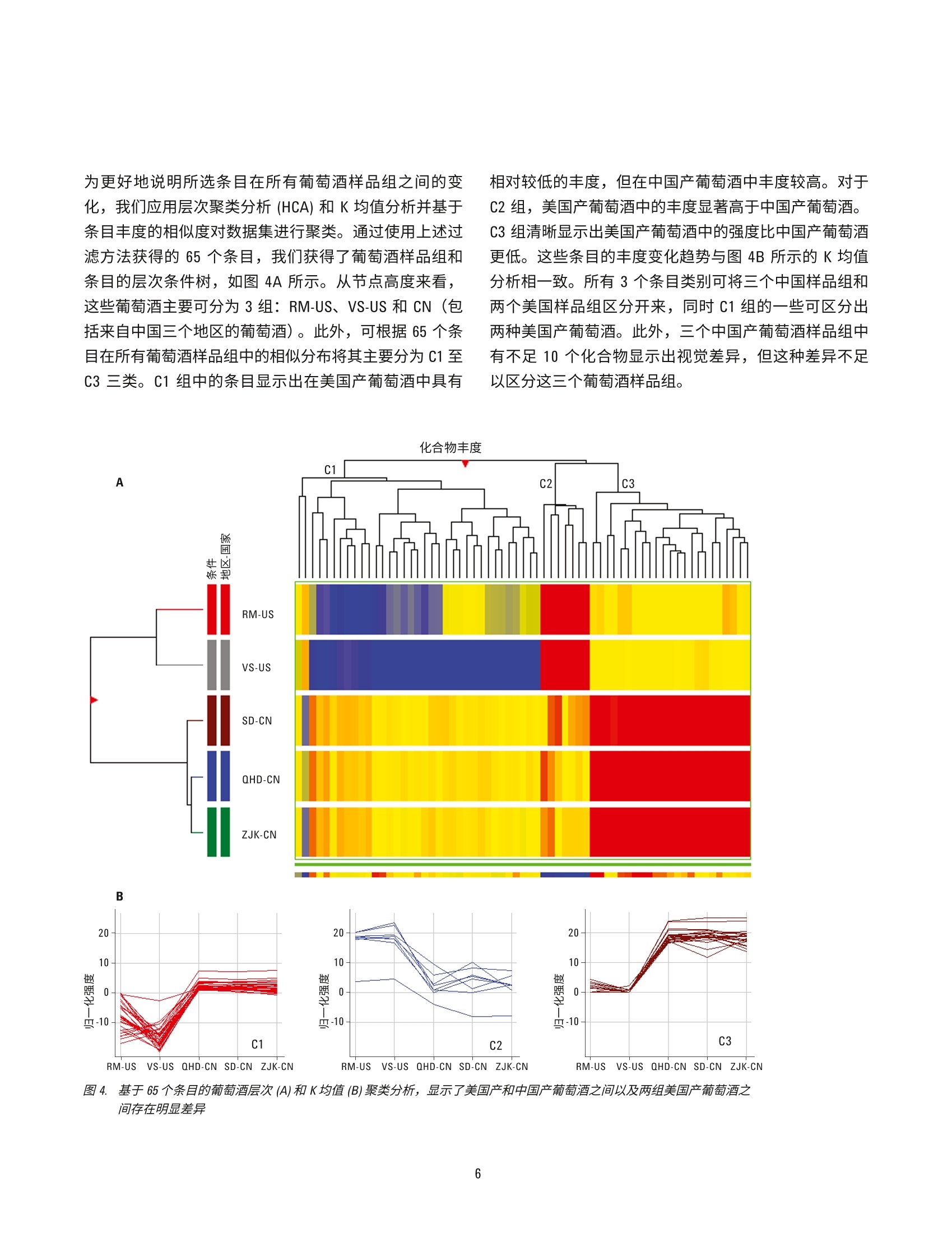
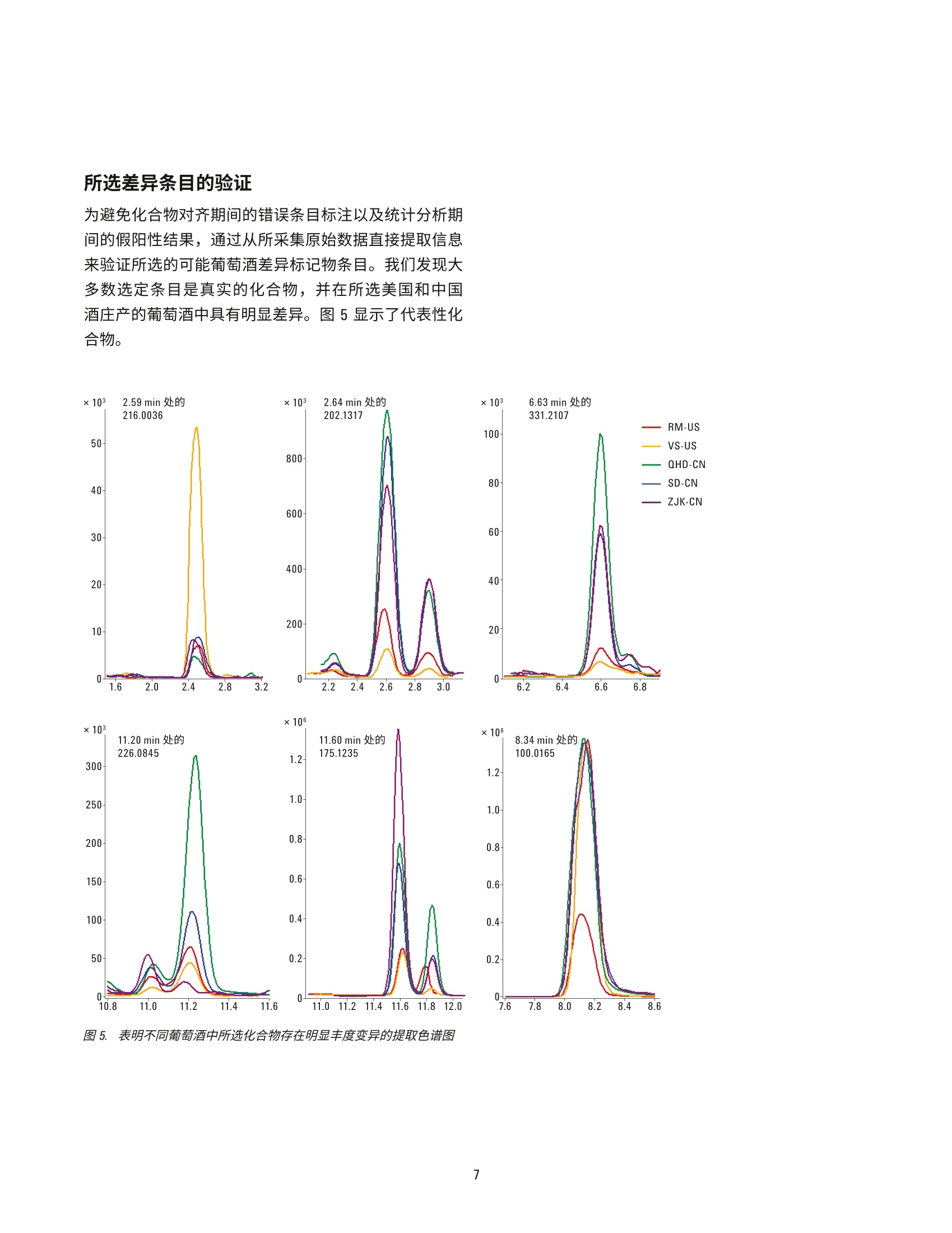
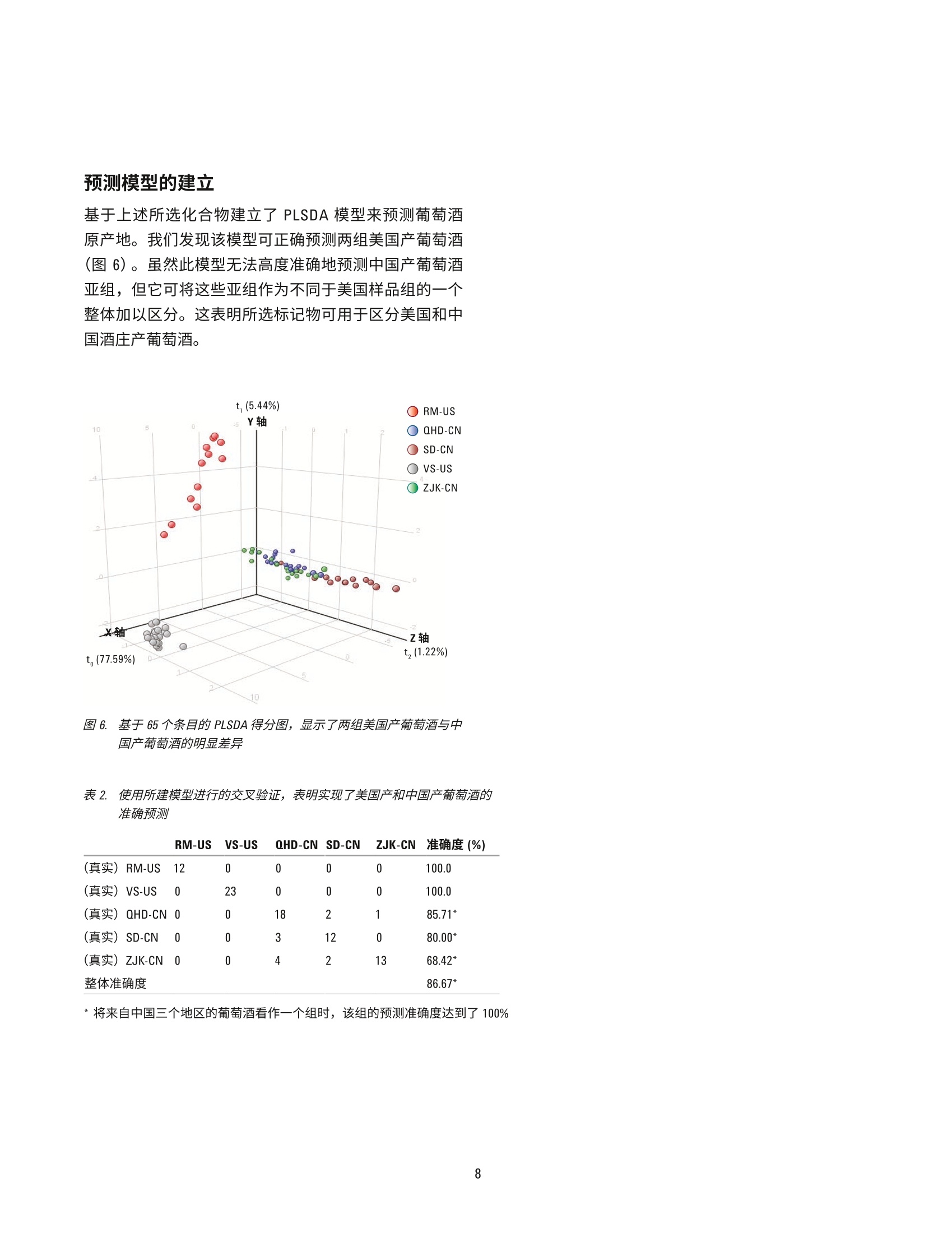
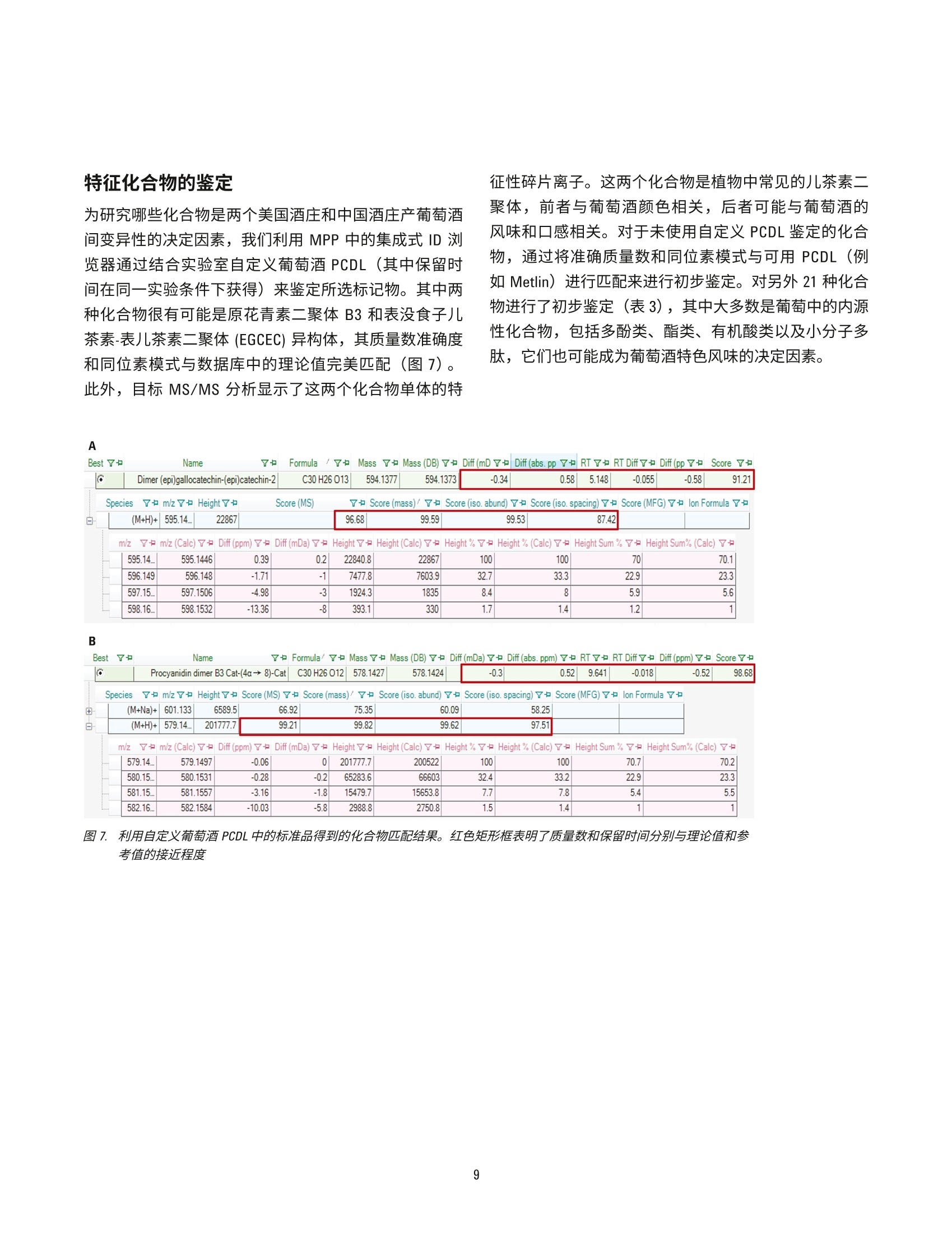
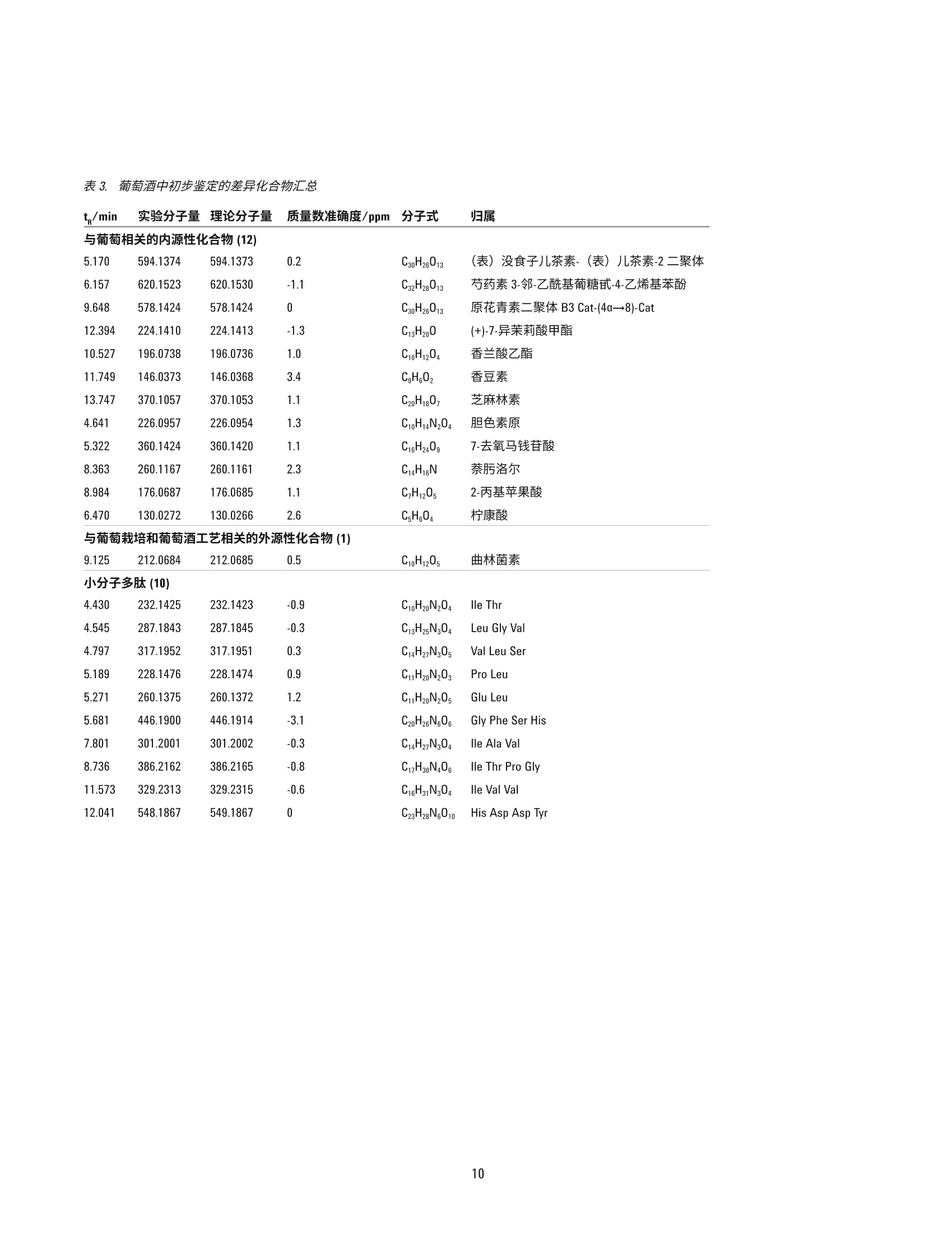
赤霞珠葡萄酒的原产地区分 使用UHPLC-Q-TOF/MS 的非靶向代谢组学研究 应用简报 食品检测 作者 摘要 ( Nana Liang、Y i ng Liu、L i nliWang、Peiyue Wang、J i nhua Wang 以及 Shen Han ) 北京出入境检验检疫局,中国北京 Meiling Lu 和 Shan Zhou 安捷伦科技(中国)有限公司 食品掺假和标签虚假行为可能会给消费者带来潜在健康风险并造成信任危机,对于高档葡萄酒产品而言尤其如此。目前的分析方法和防伪标签技术不足以确定这类产品的身份信息和原产地。本应用简报介绍了一种基于 Liang等人的研究[1]开发的追踪葡萄酒产品原产地的代谢组学分析方法。参比赤霞珠葡萄酒来自五家酒庄(两家为美国酒庄,三家为中国酒庄),并使用安捷伦 UHPLC-Q-TOF/MS 平台在准确的 TOF/MS 扫描模式下行行了初步分析。所得原始数据通过分子特征查找提取方法进行了数据挖掘。将结果导入Agilent Mass Profiler Professional (MPP)化学计量学软件,以在各组之间查找特征化合物。所得差异化合物的主成分分析和聚类分析显示了该系统区分两组美国葡萄酒与中国产葡萄酒的能力。基于这些数据的偏最小二乘差异分析(PLSDA)模型能够高度准确地预测葡萄酒组别。通过使用针对葡萄酒的自定义多酚类化合物数据库和谱库以及其他可用的安捷伦 PCDL, 我们对23种化合物进行了初步鉴定,其中大多数为葡萄中的内源性代谢物,表明在不同原产地的葡萄酒中,葡萄代谢物是区别葡萄酒主要特征的决定因素。本研究证明采用 UHPLC-Q-TOF/MS 结合化学计量学分析的代谢物组学分析方法是追踪葡萄酒原产地的有用方法。 葡萄酒在中国有广泛的受众。然而,市场上经常发现葡萄酒掺假和标签虚假问题,这些行为可对消费者带来潜在健康风险并降低消费者信任度[1]。为改善并确保葡萄酒的质量和安全性,开发葡萄酒质量和真伪监测方法以及保护特殊原产地的产品非常重要。 葡萄酒的风味主要由葡萄中的特定次级代谢产物通过酿造工艺转移到成品酒中来获得。因此,来自某个特定酒庄的葡萄酒可具有一些由葡萄带来的特殊特性,这些特性归因于土壤、气候条件等环境变异性和不同的酿造工艺。即使同一基因型的葡萄,在不同地理区域之间的一些特定次级代谢产物水平也可能存在巨大差异,由此赋予了葡萄酒产品独特的风味。因此,可以通过特征代谢物分布来区分不同原产地的葡萄酒。传统分析方法不足以寻找这类特征分布并确定原产地。基于小分子特征分布的代谢组学分析方法是研究葡萄酒真伪和追踪来源的首选方法[2-6]。 UHPLC 与高分辨率 Q-TOF/MS 的联用是主要的代谢组学分析平台之一,可对样品中挥发性较弱的热不稳定小分子进行全面分析。此外,化学计量学分析通过数据挖掘来查找可作为潜在分类标准的具体特征分布。本文中,我们旨在联用 UHPLC-Q-TOF/MS 技术和化学计量学分析,通过发现特征性分布来测定美国产和中国产赤霞珠葡萄酒的原产地。 材料和试剂 甲醇、甲酸和乙酸铵均为 LC/MS 级,分别购自 Merck、Tedia 与 Thermo Fisher 公司。实验用水来自 Milli-Q水纯化系统新鲜制备的去离子水。 参比样品收集与前处理 参比赤霞珠(CS)葡萄酒样品(共113个)直接从酒庄收集,酒庄包括美国纳帕谷的V Sattui (VS) 和 Robert Mondav(RM)酒庄,以及分别位于中国张家口(ZJK)、秦皇岛(QHD) 和山东省 (SD) 的三个酒庄。每个窑萄酒样品取2mL并置于2mL玻璃样品瓶中,通过离心去除所有颗粒物,然后用 UHPLC-Q-TOF/MS 进行分析。 葡萄酒代谢组学分析工作流程 利用UHPLC-Q-TOF/MS 在 TOF 扫描模式下根据表1列出的条件采集原始数据。首先在 Agilent MassHunter 定性软件(6.0版)中使用分子特征查找算法(MFE) 对采集到的数据进行提取,然后将结果导出为 cef 文件。或者,将整个数据集加载到 Agilent MassHunter Profinder (7.0版)软件中进行递归MFE 提取,并导出为 cef 文件。然后将cef 文件和提取到的化合物信息导入 Agilent Mass ProfilerProfessional(13.1.1版)中进行保留时间/质量数校准、峰对齐、数据过滤、多变量和单变量统计分析、主成分分析(PCA)以及聚类分析,以查找5个样品组中具有显著变化的化合物。应用模型分析,尤其是偏最小二乘差异分析 (PLSDA)创建模型以预测葡萄酒样品的原产地。应用实验室自定义的葡萄酒中多酚类化合物数据库和谱库(葡萄酒PCDL) 以及 METLIN PCDL 鉴定差异化合物。 详细LC/MS测定条件 表1.:仪器条件 液相色谱条件 结果与讨论 优化的 UHPLC分离和准确的Q-TOF/MS检测 葡萄酒具有非常复杂的基质,其中含有数千种化合物。因此,需要适当的分离技术以足够高的灵敏度和在可接受的分析时间内洗脱尽可能多的化合物。图1A中的 总离子流色谱图显示了通过使用选定 C18 色谱柱和流动相,并仔细调节梯度洗脱程序,20分钟的梯度洗脱方法可对葡萄酒样品中的大多数组分实现分离。通过MFE 算法可从一个葡萄酒样品中提取出3000多个化合物(图1B),表明该方法具有出色的分离效率。因此,这一梯度洗脱方法可用于进一步的葡萄酒样品分析。 图1.1.:典型的总离子流色谱图 (A) 和通过 MFE 提取的化合物叠加色谱图(B),显示了优化后 LC/MS方法的高分离效率。样品为美国产 CS葡萄酒 对葡萄酒样品组之间的不同化学特性进行化学计量学分析 对通过 Q-TOF 扫描模式采集的数据的保留时间 (RT) 和质荷比(m/z)重现性进行仔细检查。发现 RT 和 m/z(|Atg|/tR平均和|A(m/z)|/(m/z)平均)的相对偏差分别低于2%和5ppm, 表明用于代谢组学分析的数据是可靠的。随后使用 MFE 提取合格的数据,并通过批处理软件(DA reprocessor) 导出为 cef 文件。为研究化合物丰度如何在不同产地的葡萄酒样品之间变化,将上述经过处理的数据导入 MPP 进行化学计量学分析。将使用MFE 从所有收集的葡萄酒样品中提取的化合物 RT 和质量数信息在 MPP 的RT质质量数偏差窗口中对齐。然后将每个对齐后的化合物作为 MPP 中的独立条目,并使用RT和准确质量数进行标注。通过上述处理,我们获得了98个葡萄酒样品的29564个条目。然后依次使用以下条件对这些条目进行过滤:出现频率(至少一个组≥80%)、样品变异性(至少一个组≤50%)、方差分析(ANOVA, P≤0.01)、倍数变化(FC≥3),以及|P校正|≥0.8的C-C曲线。最终,保留了65个在5个样品组之间具有显著性差异的条目。图2显示了每个条目在不同组之间平均丰度的变异性。 图2.数据过滤后,样品组中65个差异条目的丰度变异性。过滤参数:出现频率,至少1个组中为80%;丰度变异性,至少一个组≤50%; ANOVA, Ps0.01;倍数变化, FC23, 其中 10对中有7对的原始丰度差异截止值为1×10; C-C曲线,|P校正|≥0.8 PCA 是用于查看复杂数据集结构的数学算法,常用于查看样品之间的相似度。对以上步骤中获得的65个条目进行 PCA分析。我们发现数据集可减少到4维,其中最高三个维度或主成分 (PC)的总和可表现为 84.76%的总协方差(图3A)。而最高两个成分甚至可表现为 83.04%的总协方差(图3B)。此外,两个美国酒庄产的葡萄酒可以彼此区分,也能与中国产葡萄酒得到明确区分。通过对比发现,中国酒庄产的三个葡萄酒互相重叠(图3)。这表明上述65个条目是中国和美国产葡萄酒之间主要变异性的来源,并且可用作标记物来区分来自两个所选美国酒庄和中国三个地区的葡萄酒。 识寸a 图3. 65个差异条目的 PCA 得分图。A) 3-D PCA得分图。 B) 2-D PCA得分图 为更好地说明所选条目在所有葡萄酒样品组之间的变化,我们应用层次聚类分析(HCA)和K均值分析并基于条目丰度的相似度对数据集进行聚类。通过使用上述过滤方法获得的65个条目,我们获得了葡萄酒样品组和条目的层次条件树,如图4A 所示。从节点高度来看,这些葡萄酒主要可分为3组: RM-US、VS-US 和 CN(包括来自中国三个地区的葡萄酒)。此外,可根据65个条目在所有葡萄酒样品组中的相似分布将其主要分为C1至C3三类。C1组中的条目显示出在美国产葡萄酒中具有 相对较低的丰度,但在中国产葡萄酒中丰度较高。对于C2组,美国产葡萄酒中的丰度显著高于中国产葡萄酒。C3 组清晰显示出美国产葡萄酒中的强度比中国产葡萄酒更低。这些条目的丰度变化趋势与图4B 所示的K均值分析相一致。所有3个条目类别可将三个中国样品组和两个美国样品组区分开来,同时C1组的一些可区分出两种美国产葡萄酒。此外,三个中国产葡萄酒样品组中有不足10个化合物显示出视觉差异,但这种差异不足以区分这三个葡萄酒样品组。 图4.基于65个条目的葡萄酒层次(A)和K均值(B)聚类分析,显示了美国产和中国产葡萄酒之间以及两组美国产葡萄酒之间存在明显差异 所选差异条目的验证 为避免化合物对齐期间的错误条目标注以及统计分析期间的假阳性结果,通过从所采集原始数据直接提取信息来验证所选的可能葡萄酒差异标记物条目。我们发现大多数选定条目是真实的化合物,并在所选美国和中国酒庄产的葡萄酒中具有明显差异。图5显示了代表性化合物。 RM-US VS-US QHD-CN SD-CN ZJK-CN 图5. 表明不同葡萄酒中所选化合物存在明显丰度变异的提取色谱图 预测模型的建立 基于上述所选化合物建立了 PLSDA 模型来预测葡萄酒原产地。我们发现该模型可正确预测两组美国产葡萄酒(图6)。虽然此模型无法高度准确地预测中国产葡萄酒亚组,但它可将这些亚组作为不同于美国样品组的一个整体加以区分。这表明所选标记物可用于区分美国和中国酒庄产葡萄酒。 10 图6..:基于65个条目的 PLSDA得分图,显示了两组美国产葡萄酒与中国产葡萄酒的明显差异 表2.使用所建模型进行的交叉验证,表明实现了美国产和中国产葡萄酒的准确预测 (真实) FRM-US 12 0 0 0 0 100.0 (真实) VS-US 0 23 0 0 0 100.0 (真实)QHD-CN 0 0 18 2 1 85.71* (真实) SD-CN 0 0 3 12 0 80.00* (真实) ZJK-CN 0 0 4 2 13 68.42* 整体准确度 86.67* *将来自中国三个地区的葡萄酒看作一个组时,该组的预测准确度达到了100% 特征化合物的鉴定 为研究哪些化合物是两个美国酒庄和中国酒庄产葡萄酒间变异性的决定因素,我们利用 MPP 中的集成式ID浏览器通过结合实验室自定义葡萄酒 PCDL (其中保留时间在同一实验条件下获得)来鉴定所选标记物。其中两种化合物很有可能是原花青素二聚体B3和表没食子儿茶素-表儿茶素二聚体 (EGCEC)异体体,其质量数准确度和同位素模式与数据库中的理论值完美美配(图7)。此外,目标 MS/MS分析显示了这两个化合物单体的特 征性碎片离子。这两个化合物是植物中常见的儿茶素二聚体,前者与葡萄酒颜色相关,后者可能与葡萄酒的风味和口感相关。对于未使用自定义 PCDL 鉴定的化合物,通过将准确质量数和同位素模式与可用 PCDL(例如 Metlin) 进行匹配来进行初步鉴定。对另外21种化合物进行了初步鉴定(表3),其中大多数是葡萄中的内源性化合物,包括多酚类、酯类、有机酸类以及小分子多肽,它们也可能成为葡萄酒特色风味的决定因素。 田 (M+Na)+ 601.133 6589.5 66.92 75.35 60.09 58.25 100 70 70.1 -0.055 -0.58 91.21 白 579.14. 580.15 580.1531 -0.28 0 -0.2 201777.7 65283.6 66603 100324 10033.2 70.722.9 70.223.3 581.15. 581.1557 -3.16 -1.8 15479.7 15653.8 7.7 7.8 5.4 5.5 582.16.. 582.1584 -10.03 -5.8 2988.8 2750.8 1.5 1.4 1 1 图 7.7..利用自定义葡萄酒 PCDL 中的标准品得到的化合物匹配结果。红色矩形框表明了质量数和保留时间分别与理论值和参考值的接近程度 表3. 葡萄酒中初步鉴定的差异化合物汇总 t/min 实验分子量理论分子量 质量数准确度/ppm 分子式 归属 与葡萄相关的内源性化合物(12) 5.170 594.1374 594.1373 0.2 C30H26013 (表)没食子儿茶素-(表)儿茶素-2二聚体 6.157 620.1523 620.1530 -1.1 C32H28013 芍药素3-邻-乙酰基葡糖甙-4-乙烯基苯酚 9.648 578.1424 578.1424 0 C30H26013 原花青素二聚体 B3 Cat-(4a→8)-Cat 12.394 224.1410 224.1413 -1.3 C13H200 (+)-7-异茉莉酸甲酯 10.527 196.0738 196.0736 1.0 C10H1204 香兰酸乙酯 11.749 146.0373 146.0368 3.4 C,H,0z 香豆素 13.747 370.1057 370.1053 1.1 C20H180, 芝麻林素 4.641 226.0957 226.0954 1.3 C0H14N204 胆色素原 5.322 360.1424 360.1420 1.1 C16H240g 7-去氧马钱苷酸 8.363 260.1167 260.1161 2.3 C14H16N 萘肟洛尔 8.984 176.0687 176.0685 1.1 C,H1205 2-丙基苹果酸 6.470 130.0272 130.0266 2.6 C,H,04 柠康酸 与葡萄栽培和葡萄酒工艺相关的外源性化合物(1) 9.125 212.0684 212.0685 0.5 C10H1205 曲林菌素 小分子多多(10) 4.430 232.1425 232.1423 -0.9 C10H20N204 lle Thr 4.545 287.1843 287.1845 -0.3 C13H25N:04 Leu Gly Val 4.797 317.1952 317.1951 0.3 C14H27N0g Val Leu Ser 5.189 228.1476 228.1474 0.9 CH20N20: Pro Leu 5.271 260.1375 260.1372 1.2 CH20N20s Glu Leu 5.681 446.1900 446.1914 -3.1 C20H26N06 Gly Phe Ser His 7.801 301.2001 301.2002 -0.3 C4H27N0 lle Ala Val 8.736 386.2162 386.2165 -0.8 C7H30N20; lle Thr Pro Gly 11.573 329.2313 329.2315 -0.6 C16H31N04 lle Val Val 12.041 548.1867 549.1867 C23H28N010 His Asp Asp Tyr 结论 UHPLC-Q-TOF/MS是对多种来源的葡萄酒进行代谢组学分析的强大技术。Agilent MPP 软件可帮助用户快速有效地对数据进行对齐、过滤和聚类。通过使用推荐的代谢组学分析方法,我们对美国和中国产葡萄酒中的65种差异葡萄酒标记物进行了测定。它们在所选葡萄酒样品组中的相对丰度可用于预测葡萄酒样品是来自美国 RM或 VS酒庄,还是来自所选的三个中国地区。在这些化合物中,有23种化合物得到了初步鉴定,其中一些可能与葡萄酒的颜色或风味/口感相关,表明地域差异对葡萄酒特性的影响。目前正在持续对这些标记物进行进一步确认。 ( 参考文献 ) 1. N. N. Liang, Y. Liu, B. L. Wang, et al.“Differentiation ofgrape wines from US and China using modeling building"China Fermentation 33(12), 23-28(2014) 2.D. Serrano-Lourido, J.Saurina, S. Hernandez-Cassou,et al.“Classification and characterization of Spanish redwines according to their appellation of origin based onchromatographic profiles and chemometric data analysis"Food Chem. 135(3),1425-31 (2012) 3. SS. A. Bellomarino, X. A. Conlan, R. M. Parker, et al."Geographical classification of some Australian winesby discriminant analysis using HPLC with UV andchemiluminescence detection" Talanta 80(2),833-838(2009) 4.SS. Kallithraka, I. S.Arvanitoyannis, P. Kefalas, et al."Instrumental and sensory analysis of Greek wines;implementation of principal component analysis (PCA)for classification according to geographical origin"Food Chem.73(4),501-504(2001) 查找当地的安捷伦客户中心: www.agilent.com/chem/contactus-cn 5.LL. Vaclavik, 0. Lacina, J. Hajslova, J. Zeigenbaum. The useof high performance liquid chromatography-quadrupoletime-of-flight mass spectrometry coupled to advanceddata mining and chemometric tools for discrimination andclassification of red wines according to their variety. Anal.Chim. Acta. 45, 685 (2011) 免费专线: 800-820-3278,400-820-3278(手机用户) 联系我们: 6. A. Cuadros-Inostroza, P. Giavalisco, J. Hummel,et al.Discrimination of wine attributes by metabolome analysis.Anal. Chem. 82, 3573-3580 (2010) LSCA-China_800@agilent.com 在线询价:www.agilent.com/chem/erfq-cn 更多信息 这些数据仅代表典型的结果。有关我们的产品与服务的详细信息,请访问我们的网站 www.agilent.com。 www.agilent.com 安捷伦对本资料可能存在的错误或由于提供、展示或使用本资料所造成的间接损失不承担任何责任。 本文中的信息、说明和技术指标如有变更,恕不另行通知。 ◎安捷伦科技(中国)有限公司, 2016 2016年8月22日,中国出版 5991-7238CHCN Agilent Technologies Agilent Technologies 摘要食品掺假和标签虚假行为可能会给消费者带来潜在健康风险并造成信任危机,对于高档葡萄酒产品而言尤其如此。目前的分析方法和防伪标签技术不足以确定这类产品的身份信息和原产地。本应用简报介绍了一种基于 Liang 等人的研究开发的追踪葡萄酒产品原产地的代谢组学分析方法。参比赤霞珠葡萄酒来自五家酒庄(两家为美国酒庄,三家为中国酒庄),并使用安捷伦 UHPLC-Q-TOF/MS 平台在准确的 TOF/MS 扫描模式下进行了初步分析。所得原始数据通过分子特征查找提取方法进行了数据挖掘。将结果导入 Agilent Mass Profiler Professional (MPP) 化学计量学软件,以在各组之间查找特征化合物。所得差异化合物的主成分分析和聚类分析显示了该系统区分两组美国葡萄酒与中国产葡萄酒的能力。基于这些数据的偏最小二乘差异分析 (PLSDA) 模型能够高度准确地预测葡萄酒组别。通过使用针对葡萄酒的自定义多酚类化合物数据库和谱库以及其他可用的安捷伦 PCDL,我们对 23 种化合物进行了初步鉴定,其中大多数为葡萄中的内源性代谢物,表明在不同原产地的葡萄酒中,葡萄代谢物是区别葡萄酒主要特征的决定因素。本研究证明采用 UHPLC-Q-TOF/MS 结合化学计量学分析的代谢物组学分析方法是追踪葡萄酒原产地的有用方法。前言葡萄酒在中国有广泛的受众。然而,市场上经常发现葡萄酒掺假和标签虚假问题,这些行为可对消费者带来潜在健康风险并降低消费者信任度。为改善并确保葡萄酒的质量和安全性,开发葡萄酒质量和真伪监测方法以及保护特殊原产地的产品非常重要。葡萄酒的风味主要由葡萄中的特定次级代谢产物通过酿造工艺转移到成品酒中来获得。因此,来自某个特定酒庄的葡萄酒可具有一些由葡萄带来的特殊特性,这些特性归因于土壤、气候条件等环境变异性和不同的酿造工艺。即使同一基因型的葡萄,在不同地理区域之间的一些特定次级代谢产物水平也可能存在巨大差异,由此赋予了葡萄酒产品独特的风味。因此,可以通过特征代谢物分布来区分不同原产地的葡萄酒。传统分析方法不足以寻找这类特征分布并确定原产地。基于小分子特征分布的代谢组学分析方法是研究葡萄酒真伪和追踪来源的首选方法。UHPLC 与高分辨率 Q-TOF/MS 的联用是主要的代谢组学分析平台之一,可对样品中挥发性较弱的热不稳定小分子进行全面分析。此外,化学计量学分析通过数据挖掘来查找可作为潜在分类标准的具体特征分布。本文中,我们旨在联用 UHPLC-Q-TOF/MS 技术和化学计量学分析,通过发现特征性分布来测定美国产和中国产赤霞珠葡萄酒的原产地。结论UHPLC-Q-TOF/MS 是对多种来源的葡萄酒进行代谢组学分析的强大技术。Agilent MPP 软件可帮助用户快速有效地对数据进行对齐、过滤和聚类。通过使用推荐的代谢组学分析方法,我们对美国和中国产葡萄酒中的 65 种差异葡萄酒标记物进行了测定。它们在所选葡萄酒样品组中的相对丰度可用于预测葡萄酒样品是来自美国 RM 或 VS 酒庄,还是来自所选的三个中国地区。在这些化合物中,有 23 种化合物得到了初步鉴定,其中一些可能与葡萄酒的颜色或风味/口感相关,表明地域差异对葡萄酒特性的影响。目前正在持续对这些标记物进行进一步确认。
确定





还剩10页未读,是否继续阅读?

产品配置单



安捷伦科技(中国)有限公司为您提供《葡萄酒中原厂地区分检测方案(液相色谱仪)》,该方案主要用于葡萄酒及果酒中理化分析检测,参考标准--,《葡萄酒中原厂地区分检测方案(液相色谱仪)》用到的仪器有Agilent 1290 Infinity II 液相色谱系统、Agilent 6545 Q-TOF 液质联用系统、Agilent 1290 Infinity II Multisampler
推荐专场












相关方案
更多
该厂商其他方案
更多