推荐厂家
暂无
暂无
 留言咨询
留言咨询
留言咨询
留言咨询
留言咨询
留言咨询

 400-883-7896
留言咨询
400-883-7896
留言咨询
 400-883-7896
留言咨询
400-883-7896
留言咨询
 400-883-7896
留言咨询
400-883-7896
留言咨询






不知道有没有哪位使用过德国仪力信生产的318型漆膜硬度试验棒?可否告知这样的试验棒如何进行校准和检定么?目前我国是否有相关的校准规程呢?谢谢!
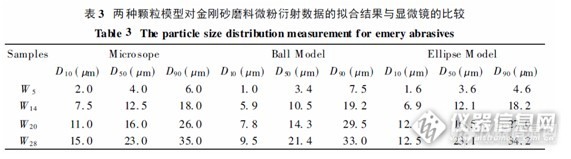
用于激光颗粒测试技术的非球形颗粒的椭圆衍射模型任中京 王少清( 山东建材学院科研处 济南250022)提要:激光颗粒大小测试的结果与颗粒形状密切相关。通过对椭圆衍射谱的研究, 提出在激光粒度分析中以椭圆谱代替球形颗粒谱。计算机模拟计算与对金刚砂实测的结果表明椭圆衍射模型可以有效地抑制粒度反演结果的展宽, 更准确地获得非球形颗粒群的粒度分布。关键词 激光衍射, 椭圆模型, 颗粒大小分析, 颗粒形状, 反演1 引言 由于颗粒大小对粉末材料的重要影响, 颗粒粒度测试在建材、化工、石油等许多领域已经成为一种不可缺少的检测技术。由于颗粒形状的多样性, 无论何种测量方法, 均需要颗粒模型。通常假定颗粒为球体, 与被测颗粒等体积的球体直径称为粒径, 或称等效粒径 。然而球体模型在激光衍射(散射) 粒度分析技术中却遇到严重困难—对非球形颗粒测试常常产生较大误差, 表现为所测得的粒度分布较真实分布有展宽且偏小。来自日本和美国的颗粒测试报告也有相同的倾向 。从光学原理上看,激光粒度分析技术是通过检测颗粒群的衍射谱来反演颗粒群的尺寸分布的。非球形颗粒的衍射谱与球体有很大不同: 前者是非圆对称的, 而后者是圆对称的。欲使二者具有可比性需要新的物理模型, 新的模型应满足: 1) 更加逼近真实颗粒;2)对一系列颗粒有普遍的适用性;3)可给出衍射谱解析式;4)在激光测粒技术中能校正颗粒形状引起的测量误差;5)能函盖球体模型。本文将证明椭圆衍射模型是满足以上条件的最佳选择。2 非球形颗粒衍射模型的椭圆屏逼近颗粒虽然是三维物体, 但是在激光测粒技术中其横截面是使光波发生衍射的主要几何因素, 因此只需研究与入射光垂直的颗粒横截面。球体衍射模型即是取颗粒的体积等效球的投影圆作为该颗粒的衍射模型。如图1 所示, 将形状任意颗粒的横截面视为一衍射屏。可分别做出其轮廓的最大内接圆和最小外接圆。设外圆直径为2b, 内圆直径为2a。分别以2a, 2b 为长短轴做椭圆。下面将证明该椭圆屏即为与图1 所示的颗粒横截面等效的非圆屏的最佳解析逼近。2. 1非圆屏与椭圆屏的几何关系由图1 可见,与非球颗粒相对应的椭圆屏的面积S e 恰好为其横截面外接圆与内接圆面积的几何中值,而与该椭圆屏面积相等的圆( 面积等效圆) 的直径Do 恰好为其长短轴2a 与2b 的几何中值。http://ng1.17img.cn/bbsfiles/images/2013/05/201305281105_441929_388_3.jpg此颗粒对球体的偏离可用形状系数K 表示, K 定义为:K=b/a[fon
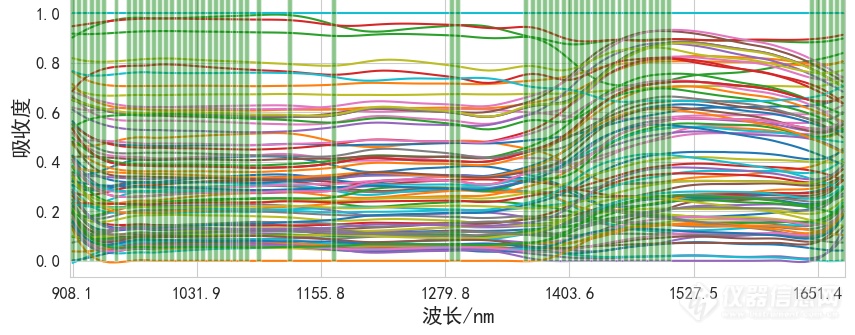
[font='times new roman'][size=16px][b]颗粒水分近红外模型建立及验证[/b][/size][/font][font='times new roman'][size=16px][b]偏最小二乘法[/b][/size][/font][font='times new roman'][size=16px][b] [/b][/size][/font][font='times new roman'][size=16px][b]PLS[/b][/size][/font][font='times new roman'][size=16px][b]算法原理[/b][/size][/font][size=14px]PLS[/size][size=14px]方法在对数据进行标准化后需要用主成分分析([/size][size=14px]Principal[/size][size=14px] [/size][size=14px]Component[/size][size=14px] [/size][size=14px]Analysis[/size][size=14px],[/size][size=14px]PCA[/size][size=14px])法来去除数据噪声。[/size][size=14px]PCA[/size][size=14px]通过计算数据矩阵的协方差矩阵得到特征向量,选择特征值(方差)最大的[/size][size=14px][i]k[/i][/size][size=14px]个[/size][size=14px]特征向量组成矩阵,从而将[/size][size=14px][i]n[/i][/size][size=14px]维数据降低到[/size][size=14px][i]k[/i][/size][size=14px]维,即有[/size][size=14px][i]k[/i][/size][size=14px]个[/size][size=14px]主成分。以二维矩阵为例,每个观测值由两个维度表示,理论认为,方差较大的方向是有效信息,方差较小的方向是噪声数据。选取方差较大的方向[/size][size=14px][i]u[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]作为主成分方向,与[/size][size=14px][i]u[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]呈正交方向[/size][size=14px]的方差较小的[/size][size=14px][i]u[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]作为副主成分方向。[/size][size=14px][i]u[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]方向上的投影具有大部分的有效信息,[/size][size=14px][i]u[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]方向上的投影可以认为是噪声数据,这样就可以把二维数据转换成一维数据。其示意图如图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]PCA[/size][/font][font='times new roman'][size=16px]二维数据分布图[/size][/font][/align][size=14px]在建模过程中,光谱数据[/size][size=14px][i]X[/i][/size][size=14px]是[/size][size=14px]90[/size][size=14px]×[/size][size=14px]125[/size][size=14px],水分数据[/size][size=14px][i]Y[/i][/size][size=14px]只有一维,即[/size][size=14px]90[/size][size=14px]×[/size][size=14px]1[/size][size=14px]。将[/size][size=14px][i]X[/i][/size][size=14px]和[/size][size=14px][i]Y[/i][/size][size=14px]分解成特征向量的形式使它们的主成分相关程度最大,其模型可以表示为:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]式中,[/size][size=14px][i]W[/i][/size][font='times new roman'][size=14px][i]x[/i][/size][/font][size=14px]和[/size][size=14px][i]W[/i][/size][font='times new roman'][size=14px][i]y[/i][/size][/font][size=14px]分别对应于[/size][size=14px][i]X[/i][/size][size=14px]和[/size][size=14px][i]Y[/i][/size][size=14px]的得分矩阵;[/size][size=14px][i]P[/i][/size][size=14px]和[/size][size=14px][i]Q[/i][/size][size=14px]分别对应于[/size][size=14px][i]X[/i][/size][size=14px]和[/size][size=14px][i]Y[/i][/size][size=14px]的载荷矩阵;[/size][size=14px][i]E[/i][/size][font='times new roman'][size=14px][i]x[/i][/size][/font][size=14px]和[/size][size=14px][i]E[/i][/size][font='times new roman'][size=14px][i]y[/i][/size][/font][size=14px]分别对应于[/size][size=14px][i]X[/i][/size][size=14px]和[/size][size=14px][i]Y[/i][/size][size=14px]的拟合残差矩阵。[/size][size=14px]通过式([/size][size=14px]3-13[/size][size=14px])和式([/size][size=14px]3-14[/size][size=14px]),可以求得[/size][size=14px][i]W[/i][/size][font='times new roman'][size=14px][i]x[/i][/size][/font][size=14px]和[/size][size=14px][i]W[/i][/size][font='times new roman'][size=14px][i]y[/i][/size][/font][size=14px],建立两者的回归模型:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]式中,[/size][size=14px][i]B[/i][/size][size=14px]为回归系数矩阵,[/size][size=14px],[/size][size=14px][i]E[/i][/size][font='times new roman'][size=14px][i]r[/i][/size][/font][size=14px]为随机误差矩阵。因此,[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px][i]x[/i][/size][size=14px]为[/size][size=14px]待预测[/size][size=14px]样本的光谱数据,[/size][size=14px][i]y[/i][/size][font='times new roman'][size=14px][i]pre[/i][/size][/font][size=14px]为预测的水分含量。[/size][font='times new roman'][size=16px][b] [/b][/size][/font][font='times new roman'][size=16px][b]PLS[/b][/size][/font][font='times new roman'][size=16px][b]模型训练及预测结果[/b][/size][/font][align=center][size=14px]首先将数据[/size][size=14px]集按照[/size][size=14px]7[/size][size=14px]:[/size][size=14px]3[/size][size=14px]的比例分成训练集和预测集,再将训练集数据随机取出[/size][size=14px]3[/size][size=14px]0%[/size][size=14px]的数据作为验证集。根据[/size][size=14px]3.1[/size][size=14px]和[/size][size=14px]3.2[/size][size=14px]预处理和波段选择的结果,选择[/size][size=14px]Normalization+SG[/size][size=14px]作为光谱的预处理方法,用随机森林以特征重要性[/size][size=14px]0.0060[/size][size=14px]作为最低界限进行波段选择,整个[/size][size=14px]PLS[/size][size=14px]建模阶段的流程示意图如下图所示。[/size][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]PLS[/size][/font][font='times new roman'][size=16px]建模过程示意图[/size][/font][/align][size=14px]对原始光谱进行[/size][size=14px]Normalization[/size][size=14px]和[/size][size=14px]SG[/size][size=14px]平滑处理并通过随机森林对处理过后的光谱进行波段选择,得到的光谱图像如下图所示,绿色方格表示选择的用来建模的波段。[/size][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031754503657_2355_3890113_3.png[/img][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]Normalization+SG+RF[/size][/font][font='times new roman'][size=16px]处理后的光谱[/size][/font][/align][size=14px]PLS[/size][size=14px]需要确定最佳主成分数目,主成分数目过少,光谱中一些有用的数据不能充分发挥作用,使得模型准确率下降,模型会处于欠拟合状态。主成分数目过多,光谱中一些无用甚至起相反作用的噪声数据不能被有效的过滤掉,容易使模型过拟合,在实际生产过程中应用此模型不能得到较准确的预测结果。为确定[/size][size=14px]PLS[/size][size=14px]的主成分数目,可以通过交叉验证的方式。[/size][size=14px]预处理过后的光谱的维度一共[/size][size=14px]60[/size][size=14px]个,则主成分数目的范围应该在[/size][size=14px]1~60[/size][size=14px]之间,用[/size][size=14px]PLS[/size][size=14px]遍历选择主成分数目,通过交叉验证得到模型的预测结果。[/size][size=14px]PLS[/size][size=14px]通过选择不同主成分建立的模型交叉验证结果如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]不同主成分数[/size][/font][font='times new roman'][size=16px]PLS[/size][/font][font='times new roman'][size=16px]建模交叉验证结果[/size][/font][/align][size=14px]由图可知,选择主成分数为[/size][size=14px]13[/size][size=14px]的时候,[/size][size=14px]PLS[/size][size=14px]模型交叉验证结果最好,而且达到了[/size][size=14px]最好的结果为[/size][size=14px]0.209[/size][size=14px],这说明经过[/size][size=14px]降维之后[/size][size=14px]的数据信噪比得到了提升。对建立好的模型进行存档,用来对预测集数据进行预测,得出预测值和预测集的真实值的均方根误差[/size][size=14px]RMSE[/size][size=14px]为[/size][size=14px]0.210[/size][size=14px]和[/size][size=14px]R[/size][font='times new roman'][size=14px]2[/size][/font][size=14px]为[/size][size=14px]0.974[/size][size=14px]。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] PLS[/size][/font][font='times new roman'][size=16px]预测值和真实值[/size][/font][/align][font='times new roman'][size=16px][b]NIRS[/b][/size][/font][font='times new roman'][size=16px][b]模型在线验证[/b][/size][/font][size=14px]通过建立三种不同的算法模型对得到的光谱数据来预测颗粒中水分的含量,得到的各个模型的结果如下表所示。[/size][align=center][size=13px]表[/size][size=13px] [/size][size=13px]各个模型的[/size][size=13px]RMSE[/size][size=13px]和[/size][size=13px]R[/size][font='times new roman'][size=13px]2[/size][/font][/align][table][tr][td][align=center][size=14px]模型[/size][/align][/td][td][align=center][size=14px]RMSE[/size][/align][/td][td][align=center][size=14px]R[/size][font='times new roman'][size=14px]2[/size][/font][/align][/td][/tr][tr][td][align=center][size=14px]PLS[/size][/align][/td][td][align=center][size=14px]0.[/size][size=14px]210[/size][/align][/td][td][align=center][size=14px]0.[/size][size=14px]974[/size][/align][/td][/tr][tr][td][align=center][size=14px]PSO[/size][size=14px]-KRR[/size][/align][/td][td][align=center][size=14px]0.221[/size][/align][/td][td][align=center][size=14px]0.981[/size][/align][/td][/tr][tr][td][align=center][size=14px]PSO-SVR[/size][/align][/td][td][align=center][size=14px]0.207[/size][/align][/td][td][align=center][size=14px]0.972[/size][/align][/td][/tr][/table][size=14px]然而,三个模型得到的结果只是对离线数据进行的预测,模型可不可靠,能不能使用是需要在线上验证的,只有在线上可靠的模型才能用在生产过程中。在每个批次制[/size][size=14px]粒过程[/size][size=14px]中的每个阶段中随机取出少量样品,用近红外探头进行采谱,得到经过处理后的光谱数据,分别用以上三个已经保存好的模型进行预测颗粒的水分含量,然后通过干燥失重法测量样品中的水分含量,得到颗粒的真实水分含量。计算不同模型中预测值与真实值的均方根误差作为模型线上结果的评价标准,均方根误差小的即为较好的模型。[/size][size=14px]采用[/size][size=14px]2[/size][size=14px].[/size][size=14px]2[/size][size=14px].[/size][size=14px]1[/size][size=14px]中的实验方案进行六个批次实验,每个批次[/size][size=14px]4[/size][size=14px]分钟采集一次样品,共获得[/size][size=14px]90[/size][size=14px]个样品数据,对每个样本在相同的条件下进行采谱,并计算得到每个样本的实际含水量。为分别用[/size][size=14px]PLS[/size][size=14px]、[/size][size=14px]KRR[/size][size=14px]和[/size][size=14px]SVR[/size][size=14px]对光谱进行预测的结果。[/size][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031754514605_4947_3890113_3.png[/img][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px]3-[/size][/font][font='times new roman'][size=16px]22 [/size][/font][font='times new roman'][size=16px]PLS[/size][/font][font='times new roman'][size=16px]模型预测值与真实值[/size][/font][/align][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031754515806_9275_3890113_3.png[/img][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px]3-[/size][/font][font='times new roman'][size=16px]23 [/size][/font][font='times new roman'][size=16px]KRR[/size][/font][font='times new roman'][size=16px]模型预测值与真实值[/size][/font][/align][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031754516958_7615_3890113_3.png[/img][/align][align=center][size=13px]图[/size][size=13px]3-[/size][size=13px]24 [/size][size=13px]SVR[/size][size=13px]模型预测值与真实值[/size][/align][size=14px]从图中可以看出,[/size][size=14px]KRR[/size][size=14px]模型的预测结果与真实结果的误差值变化比较平稳,距离误差零点远的点较少,[/size][size=14px]SVR[/size][size=14px]次之,[/size][size=14px]PLS[/size][size=14px]效果在三者中比较差,表[/size][size=14px]3-[/size][size=14px]8[/size][size=14px]表示了这三个模型[/size][size=14px]预测值与真实值的均方[/size][align=center][size=13px]表三个模型的均方根误差[/size][size=13px]RMSE[/size][/align][table][tr][td][align=center][size=13px]模型[/size][/align][/td][td][align=center][size=13px]RMSE[/size][/align][/td][/tr][tr][td][align=center][size=13px]PLS[/size][/align][/td][td][align=center][size=13px]0.[/size][size=13px]232[/size][/align][/td][/tr][tr][td][align=center][size=13px]KRR[/size][/align][/td][td][align=center][size=13px]0.[/size][size=13px]208[/size][/align][/td][/tr][tr][td][align=center][size=13px]SVR[/size][/align][/td][td][align=center][size=13px]0.[/size][size=13px]210[/size][/align][/td][/tr][/table][size=14px]从图和表中都可以表明,模型的线上预测结果都挺不错。其中,用[/size][size=14px]KRR[/size][size=14px]模型取得的效果最好,因此,选择[/size][size=14px]KRR[/size][size=14px]模型作为光谱水分预测的最优模型。[/size][font='times new roman'][size=16px][b]小结[/b][/size][/font][size=14px]通过[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]对颗粒中水分含量的预测进行了研究,主要结论如下:[/size][size=14px]对光谱数据进行了预处理研究,用[/size][size=14px]PLS[/size][size=14px]进行了建模,其中归一化和[/size][size=14px]SG[/size][size=14px]卷积平滑结合的方法效果最好。利用原始光谱验证集的[/size][size=14px]RMSE[/size][size=14px]和[/size][size=14px]R[/size][size=14px]分别为[/size][size=14px]0.[/size][size=14px]242[/size][size=14px]和[/size][size=14px]0.[/size][size=14px]958[/size][size=14px],预处理后的结果为[/size][size=14px]0.[/size][size=14px]214[/size][size=14px]和[/size][size=14px]0.[/size][size=14px]967[/size][size=14px];在预测集中使用原始光谱得到的[/size][size=14px]RMSE[/size][size=14px]和[/size][size=14px]R[/size][size=14px]分别为[/size][size=14px]0.[/size][size=14px]221[/size][size=14px]和[/size][size=14px]0.[/size][size=14px]960[/size][size=14px],预处理后的结果为[/size][size=14px]0.[/size][size=14px]212[/size][size=14px]和[/size][size=14px]0.[/size][size=14px]973[/size][size=14px]。说明经过归一化和[/size][size=14px]SG[/size][size=14px]卷积平滑后的预处理后光谱的信噪比得到了提升。[/size]









 我要推广仪器
我要推广仪器
 下载APP
下载APP