
 关注
关注
已关注
![]() 已认证
已认证
粉丝量 0

LarcomSE量伙半导体&SEMICON CHINA 2023展会回顾
被疫情耽误的时间,这次展会全部补了回来。7+3的展馆明显不够用,再加上W和N的其他展会,整个新国博犹如一场盛大的嘉年华,人太多了。 长话短说,还是用现场的图片回顾一下2023年SEMICON CHINA的盛况。,时长00:14
企业动态
2023.07.18

国产服务器芯片要燃了
近年来,随着中国加快建设新基建,云计算、边缘计算等新兴技术渗透率逐渐提高,推动服务器市场出货量稳步增长。01中国强势领涨据中国互联网数据中心(IDC)统计:2019年全球服务器出货量达1174万台,同比轻微下降0.9%,全球服务器出货金额为873亿美元,同比下滑1.7%。中国服务器市场出货量达到318.6万台 同比下滑3.7%,市场规模达到182.0亿美元,同比增长2.9%。中国服务器市场规模在全球占比20.8%。2020年全球服务器出货量达1220万台,同比增长3.92%,全球服务器出货金额为910.1亿美元,同比增长4.26%;中国服务器市场出货量为350万台,同比增长9.8%,市场规模达到216.49亿美元,同比增长19.0%。中国服务器市场规模在全球占比23.8%。2021年全球服务器市场出货量1353.9万台,同比增长6.9%,全球服务器出货金额为992.2 亿美元,同比增长 6.4%,中国服务器市场出货量为391.1万台,同比增长8.4%,市场规模达到250.9亿美元,同比增长12.7%。中国服务器市场规模在全球占比25.3%。根据 Counterpoint 的全球服务器销售跟踪报告,2022年全球服务器出货量达1380万台,同比增长6%,出货金额为1117 亿美元,同比增长 17%。此外,根据IDC 发布的《2022 年中国服务器市场跟踪报告》,2022 年中国服务器市场规模为 273.4 亿美元,同比增长 9.1%。中国服务器市场规模在全球占比24.5%。从以上数据可以看到,中国正成为全球最主要的服务器增长市场,市场规模由2019年的182亿美元增长至2022年的273.4亿美元,复合年均增长率达14.5%。根据IDC、中商产业研究院数据显示,预计2023年中国服务器市场规模将增至308亿美元。未来中国服务器市场还会迎来新一轮的井喷式发展。面对如此广阔的市场空间,中国芯片公司如何把握?02抓住这一好时机!一方面,服务器的独立自主性可以确保其在运行过程中的安全性,尤其对于一些高新科技企业,核心的技术数据等同于生命。过于依赖进口就等同于将自己生命的主动权全权托出。比如:今年伊始,戴尔目标2024年全面停止使用中国产芯片的消息一传出就引起了轩然大波,要知道就在两年前,戴尔大中华区董事长还说要扎根中国,“不要把自己当外人”。可见,服务器国产化的重要性不言而喻。另一方面,从上游服务器核心的芯片领域来看,X86依然是服务器CPU的主流架构,市场长期被英特尔和AMD为代表的厂商垄断。按照2021年统计数据,X86架构市场占比高达97%。ARM架构市场占比2.07%,剩下的其他架构仅剩0.93%。根据 IDC 在2018年服务器成本结构数据显示,芯片成本在基础型服务器中约占总成本的 32%,而在高性能或更强性能的服务器中,芯片成本占比高达 50%~83%。随着ChatGPT 爆火,致使全球高性能服务器竞赛升温,服务器芯片市场将会很快迎来爆发式增长。那么市场增长产生的直接价值是什么?是红彤彤的钞票!中国作为最主要的服务器增长市场,对应的服务器芯片公司必然不会放过这样一个好时机。如今,国产服务器CPU正处于奋力追赶的关键时期,主流的厂商包括海光、兆芯、飞腾、华为鲲鹏、龙芯、申威六家领军企业。03国产服务器芯片实力如何?就各家发展特点来看:海光、兆芯都采用x86架构IP内核授权模式,可基于公版CPU核进行优化或修改,优点是性能起点高、生态壁垒低,但由于依赖海外企业授权,自主可控风险偏高。相较x86,走Arm路线自主化程度更高。华为鲲鹏、飞腾都获得了Armv8永久授权,可自行研发设计CPU内核和芯片,也可以扩充指令集。不过现在Arm将不再向这些国产CPU厂商提供Armv9的永久授权,因此采用Arm架构仍存长期隐患。龙芯中科、申威分别走的是MIPS、Alpha路线,自主可控程度相对更高,但偏小众。就各家产品及应用来看:华为鲲鹏:垂直生态的领导者,也被称为国产服务器CPU的黑马。在通用计算处理器领域,华为鲲鹏在2014 年发布鲲鹏 912 处理器, 2016 年发布鲲鹏 916处理器。2019 年 1 月,华为正式发布鲲鹏 920 芯片。鲲鹏 920 处理器是业内首款 7nm 数据中心 ARM 处理器,非 X86 架构芯片中鲲鹏 920 芯片在算力维度方面优势领先。在SPEC (标准性能评估机构)测试中,48 核的鲲鹏 920 与 IntelXEON8180 的性能相当,而 64 核的测试性能要优于 XEON8180。按理说,性能强悍的鲲鹏 920 本可以拿下一大块Intel服务器芯片的市场,但是在鲲鹏 920 推出之际,正值华为开始持续遭遇美国打压。受限于其工艺,这款处理器处于被动消耗状态。自2020年中国电信开始招标华为鲲鹏服务器以来,受制于鲲鹏芯片短缺的影响,整体供应处于偏紧状态。同样受到限制的还有飞腾和申威。2021年4月,美国商务部宣布,将国产CPU厂商飞腾、申威等7家中国机构纳入“实体清单”,对其进行出口管控。两者的共性是都在算法和模型训练上颇具实力。不过,此次纳入实体清单并不意味着完全无法使用代工服务,之前华为无法获得台积电供货是因为美国出台专门针对生产的精准打击措施。飞腾是PKS(飞腾P、麒麟K、安全S)生态体系主导者,其党政市场占有率高。飞腾生态发展迅速,为行业自主创新作出了重要贡献。在生态建设方面,飞腾与 1600余家国内软硬件厂商打造完整生态体系,与 6 大类 1000 余种整机产品,2600 余种软件和外设完成了适配;基于飞腾桌面 CPU 的终端已形成了较为完整的生态图谱,可覆盖从整机硬件、基础软件到上层的应用。基于飞腾桌面 CPU 的终端产品已能够实现海量 Android 应用的运行,基于飞腾 CPU 的软件生态也在不断丰富和完善。从产品迭代上,飞腾主要包括 FT-1500 系列产品、FT-2000 系列产品以及基于 FTC663 内核的 D/S 系列产品。申威是特种领域的领导者,为“国之重器”中国超算供应大脑。申威采用自研的申威 64 位指令集,重点应用于特种领域,努力实现在国防和网络安全领域芯片的自主可控。随着其产品技术的日益成熟,其生态也不断趋于完善。申威的主要代表产品是SW1600、SW1610、SW26010。海光信息:国产高端CPU领军者。海光最新一代 CPU 已接近国际同类高端产品水平,并兼容x86 指令集,具备较高的应用兼容性和较低的迁移成本,在电信、金融、互联网等领域优势显著,其与第一大股东中科曙光的高效协同为公司产品放量打下了深厚基础。海光CPU包括海光3000、5000以及7000系列,三个系列产品技术设计同源,处理器核心等具有相似的技术特征。其中,海光3000系列主要应用于工作站与边缘计算服务器,海光5000系列主要应用于中低端服务器,海光7000系列主要应用于高端服务器。目前在售的海光CPU产品主要为海光7200、海光5200和海光3200系列产品。兆芯:合资CPU的探路者。兆芯于2013年由中国台湾威盛与隶属于上海市国资委的上海联和投资公司所合资成立,威盛持股20%,上海国资委持股80%。兆芯同时掌握中央处理器、图形处理器、芯片组三大核心技术,具备相关IP自主设计研发的能力。其兆芯开先KX-6000系列处理器,是业内第一款完整集成CPU、GPU、芯片组的SoC单芯片国产通用处理器,这为整机系统的开发提供了较大的便利条件,同时也更利于控制成本。与英特尔处理器横向对比,8核心的KX-U6780A产品性能与第七代的4核心英特尔i5整体水平仍存在差距,尤其是单核性能不足7代i5一半,但整数性能方面对英特尔i5实现了反超。龙芯中科:自主可控程度高,其主力CPU产品进入快速增长阶段。龙芯中科是中国科学院计算所自主研发的通用CPU,采用自主LoongISA指令系统,兼容MIPS指令,所有IP模块皆为自主设计,拥有片内安全机制、可信性高。今年4月,龙芯推出2023款HPC CPU:3D5000,拥有32核高达2 GHz和300W TDP,据称比典型Arm芯片快4倍。龙芯3D5000 CPU通过以小芯片的方式将两个现有的3C5000芯片融合在一起进行封装,面向国内服务器细分市场和HPC客户。龙芯 3D5000 的推出,进一步满足了数据中心对性能的需求,也标志着龙芯中科在服务器 CPU 芯片领域进入国内领先行列。不过,由于支持龙芯的整机厂商仅有5家左右,且其芯片虚拟化能力尚存不足,因此支持的云平台厂家同样不多。除了以上提到的指令集架构之外,与Arm、MIPS同源的RISC-V也正在兴起。因其相对精简的指令集架构(ISA)以及开源宽松的BSD协议近年来发展较快,国内阿里平头哥、国芯科技等企业推出了基于RISC-V架构的相关嵌入式CPU产品。不过发展至今,国产化之路依旧走得非常艰难!04国产化依旧走得很难!自浪潮在1993年研发出国内首台小型服务器开始,国产服务器已经走过了整整30年。如今,这个成熟市场的特点非常明显:不怎么赚钱但又非常关键。一方面在英特尔X86架构的技术壁垒和成熟生态面前,ARM这条路径本身就没那么容易。TrendForce也曾预测,至2023年前,以ARM架构为代表的服务器芯片仍难与X86抗衡。另一方面,开发ARM架构的服务器芯片难关重重,不止设计复杂,对性能、功耗要求极高,无疑是一场重投入、长周期的战役。而且,开发之后能否批量销售、客户用起来不出问题等更是无形的挑战。中国服务器能取得今天的成绩除了国产厂商的砥砺前行之外,还得益于国家的大力扶持。05三大运营商已做表率,中国市场快燃了自2007年以来,中国政府部门开始重视网络信息安全保护,鼓励国有企业和政府机构等使用本土厂商的IT设备,包括网络交换机、服务器、存储等,叠加信创市场的推动,国产服务器采购比例不断提高。最近几年中国电信、中国移动服务器招标的大部分名额就给了国产服务器厂商。中国移动2021—2022年PC服务器集中采购第一批次及补采共采购204696台服务器,国产芯片服务器占比41.65%,其中海光占比19.74%,华为鲲鹏占比21.90%。中国移动2021—2022年PC服务器集中采购第二批次(标包1-6)采购47845台服务器,国产芯片服务器占比26.41%,其中海光占比11.36%,华为鲲鹏占比15.05%。中国移动2021—2022年PC服务器集中采购第二批次(标包7-9)采购34400台服务器,其中标包7为采用海光芯片的PC服务器,合计14133台,占比41.08%;标包9为采用鲲鹏芯片的PC服务器,合计6864台,占比19.95%,本次集中采购整体国产化率为61.04%。综合来看,中国移动PC服务器在2021—2022年集中采购中,采用海光芯片的服务器达59982台,占比20.90%,采用鲲鹏芯片的服务器达58901台,占比20.53%,整体国产服务器占比高达41.43%。值得注意的是,根据中国移动发布的2020年PC服务器集中采购项目结果显示,采购规模共计13.8万台,订单大头被英特尔芯片拿走,占比高达77%,鲲鹏芯片占比只有14%,海光芯片占比7%,AMD芯片占比2%。中国移动大规模采购国产芯片的服务器也并非孤例。中国电信2020年服务器集中采购56314台服务器,国产服务器预估采购数量达11185台,占总数的19.9%;英特尔服务器占79.4%,AMD服务器占0.7%。中国电信2021—2022年服务器集中采购20万台,国产处理器芯片的采购规模为53401台,整体国产服务器(包括华为鲲鹏、海光、飞腾)占比26.7%。英特尔处理器占70.9%,AMD服务器占2.4%。在2022年中国联通人工智能服务器集中采购项目中,标包二全部采用华为昇腾系列,台数占比为33.3%,预算占比为30.7%。前不久,中国建行进行的6亿元的服务器招标,国产CPU得到全胜。根据建行的招标结果显示,这次中标的服务器,均采用的是飞腾芯片、鲲鹏芯片、海光芯片架构。从具体的份额来看,鲲鹏芯片的服务器高达3.64亿元,占所有金额的61%,接近三分之二。而海光芯片的服务器拿下了1.58亿元,占所有金额的26%。飞腾芯片的服务器拿下7411万元,占所有金额的12%。06服务器国产化不能只靠信创整体来看,伴随着云计算时代的到来,中国专业的服务器厂商加速技术创新,逐渐实现了向高端市场的渗透,不断挤压海外服务器厂商在服务器市场的份额及发展空间。但是,我们应该注意到,中国服务器市场依旧在绝大部分环节受制于国外尤其是美资厂商。中国纵然有政府的鼓励与支持,但是就整个市场而言,企业级依旧占据着更多的市场份额,在此基础上,希望市场愿意多给国产服务器一些机会。最起码不应该是“一只手掐住你脖子,另一只手伸进你钱包”的现状。
企业动态
2023.05.11

全自动双腔6-8英寸兼容快速退火炉RTP
双腔全自动兼容6-8寸快速退火炉RTP产地:中国型号:S803特点:室温到1250℃,应用于SiC,GaN等第三代半导体领域简介(Description):S803系列自动快速退火炉,内置Robot可以自动取放片,适用于最大8英寸(单片200mm*200mm)及6英寸(单片150mm*150mm)硅片、第二代、第三代化合物材料等(包括但不限于,砷化镓,碳化硅,氮化镓等各类衬底和外延片),拥有出色的热源和结构设计,独有专利的温度控制系统,能更为精准进行温控操作,可视化软件平台,也实时对温度进行监控并矫正,保证工艺的稳定性和重复性。双面加热方式与单面加热相比,可以大幅减小图案加载效应,晶片上的热的均匀性将更好。多路气体配置(可定制更多),配置真空腔体,整机通过Semi认证。设备国产化率达到90%,配件渠道丰富。 定义(Definition):快速热处理(RTP)设备是一种单片热处理设备,可以将晶圆的温度快速升至工艺所需温度(200-1300℃),并且能够快速降温,升/降温度速率约20-250℃。RTP设备还具有其他优良的工艺性能,如极佳的热预算和更好的表面均匀性,尤其对大尺寸的晶圆片。多用于修复离子注入后的损伤,多腔体规格可以同时运行不同的工艺过程。名词解释RTA:Rapid Thermal Annealing 快速热退火。名词解释RTO:Rapid Thermal Oxidation 快速热氧化,主要用于生长薄绝缘层。名词解释RTN:Rapid Thermal Nitridation 快速热氮化。推荐适用场景:碳化硅氮化镓等化合物外延制造,IGBT、MOSFET功率器件研发制造,MEMS研发制造。 设备规格(Specifications):1、全自动操作模式(腔体内配置进口主流Robot,与一线顶级自动化设备同规格产品,高效,稳定,故障率低);2、Robot取放片(全程在腔内Robot传递wafer进行热处理,避免污染,自动化程度高,节省人工);3、冷却方式包括水冷和氮气吹扫;4、MFC控制,3-5路制程气体;5、SEMI认证(整体通过Semi认证,符合半导体行业国际要求)。 设备主要工艺应用(Application):●快速热处理(RTP),快速退火(RTA),快速热氧化(RTO),快速热氮化(RTN);●离子注入/接触退火;●高温退火;●高温扩散;●金属合金;●热氧化处理。 设备主要应用领域(Field):●化合物半导体(磷化铟、砷化镓、氮化物、碳化硅等);●MEMS等传感器;●二极管、MOSFET及IGBT等功率器件;
新品
2023.04.07
Micro LED全球专利超4万件,国产厂商准备充分,喜迎市场提前爆发
据报道,由于苹果公司突然被传出将转向Micro LED自研和规模化部署,产业预计将于2023年下半年陆续传出规模量产的消息。该文发布数日后,在日前发布的《2023 Micro LED产业技术洞察白皮书》(以下简称:白皮书)也提到,Micro LED四大关键技术突破在即,产业或进入快速爆发期。全球专利超4万件白皮书由国家第三代半导体技术创新中心(苏州)、江苏第三代半导体研究院与智慧芽联合发布,其中有很多内容得到行业的广泛关注。白皮书指出,Micro LED产业呈现出市场潜力大、技术储备丰富、创新研发热度高涨的特征,全球该领域的专利申请已超过4万件,正处于爆发式增长期。图源:《2023 Micro LED产业技术洞察白皮书》通过图表能够看到,自2017年开始,Micro LED相关的专利申请数量出现了爆发性的增长,尤其是在2019年-2021年这三年,专利申请明显处于高位。并且,图片上也明确提到了,在超过4万件的专利里,审中和有效专利占比接近80%,其中有效专利为1.3万件。从这个层面来看,目前Micro LED在基础研究方面已经有了较为充分的准备,后续还会有更多的创新,预计主要集中在提升良率、稳定性和光效等方面。另外,白皮书也提到,目前国产厂商在Micro LED发展中扮演着重要的角色。通过下图能够看到,在全球Micro LED专利申请的TOP15中,国内厂商的占比约一半,其中京东方更是仅次于三星的存在,排在全球的第二位。图源:《2023 Micro LED产业技术洞察白皮书》对于京东方而言,该公司将MLED(Mini / Micro LED)视为下一代显示技术,是该公司“1+4+N + 生态链”业务构架里面的重要一环。目前,除了技术创新以外,京东方也在着手整合MLED相关的产业链。统计数据显示,截止到2021年京东方在全球范围内的供应商共 5200 家左右,供应链本地化率达 72%,这其中LED芯片厂商和驱动芯片厂商将会是该公司布局MLED的重要环节。2022年11月,京东方发布公告,拟不超过21亿元的自筹资金认购华灿光电向特定对象发行的A股股票,认购完成后将以23.08%持股比例成为华灿光电第一大股东。京东方指出,此举将加快Mini / Micro LED 前沿技术研发及产品落地。除了京东方,华星光电也是Micro LED专利申请世界前五的厂商。我们都知道华星光电的背后是TCL,该公司是国内最早布局Mini LED技术的公司。实际上,在2021年之前TCL曾一度引领全球Micro LED的创新。根据TCL电子研发中心总经理陈乃军在2021年初分享的数据,截止到2020年TCL华星拥有的Micro LED领域专利已高达140件,居全球首位。不过,发明专利的申请一般批准超过两年,实用新型专利的审批也在一年左右的时间,因此当时2019年和2020年大量申请的专利还没有释放出来。目前,TCL虽然不是市场TOP 1,不过也是头部阵营的企业。白皮书指出,目前Micro LED专利布局战主要在中韩美三国之间打响,彼此之间的优势也不大相同。国内胜在参与者重,尤其是面板显示环节;韩国的优势头部企业技术和体量壁垒高,高端产品更有市场地位;美国的重点在应用端,是市场引领的重要力量。Micro LED关键技术突破在望在之前的文章里,我们曾特别指出,目前Micro LED在量产方面还有一些难题需要解决,比如巨量转移、全彩显示、微缩LED、基板制造、集成封装和产品检测。白皮书指出,在一些关键问题上,比如巨量转移领域,全球专利布局总量超过3300件。巨量转移技术是Micro LED量产的关键环节,能够让Micro LED实现大幅度的成本降低。不过,在此前巨量转移的效率和良率都表现不佳,完全不够量产的级别。白皮书中提到,当前,该领域主要有五大技术流派:分子作用力、静电、磁力转移、激光转印、自组装,其中分子作用力方向的专利布局数量较高。此外,在全彩显示方面,目前厂商专利数量超过2000件,在RGB三色加紫外光或者蓝光驱动方面,已经取得了积极的进展。从市场消息来看,预计在2023年包括友达、三星和京东方等面板厂商都将在2023年小批量量产Micro LED。巨头之间的商用竞速由于Micro LED进展快于此前的市场预期,因此目前苹果、三星、华为和Meta等终端厂商都在争分夺秒,希望拿到Micro LED第一块商用蛋糕。这其中苹果的表现最值得关注,要知道目前IT显示和PC领域对Mini LED的大量需求就是苹果带动的。根据最新的报道,苹果目前已经在多家公司下了数笔订单,用于AR眼镜的概念验证(POC),每笔订单规模在50套-100套左右。当然,作为全球头部的VR设备厂商,Meta也在做同样的事情。根据Omdia研究报告中的观点,苹果预计将在2024年推出第一款Micro LED的智能手表,然后将其导入到AR/VR设备中。需要特别指出的是,苹果和Meta都非常重视国内Micro LED的产业链,尤其是前者,希望借助Micro LED摆脱对三星的屏幕依赖。不过,有一点需要指出的是,在商用落地的方向上,国内厂商更倾向于将Micro LED落地在大屏拼接和可穿戴设备市场,而外媒援引业内人士的观点称,苹果是想在包括iPhone在内的全系产品上使用Micro LED,这也是苹果公司内部屏幕自研的主要方向。小结从专利时间上看,预计近两年还会有大量的Micro LED相关的专利审批通过。同时,在巨量转移和全彩显示等环节,也会有更多新的专利提交。虽然现在的Micro LED还没有兑现高性能、低成本、低功耗的潜能,但是市场节奏在加快,将会吸引更多的资源进入这个赛道,一些关键问题将会更快地找到解决方案。对于Micro LED的商用,相较而言,国产厂商准备的很充分。
企业动态
2023.03.10

GaN,迎来新突破!
如今,以碳化硅(SiC)、氮化镓(GaN)等“WBG(Wide Band Gap,宽禁带,以下简称为:WBG)”新型材料为基础的功率半导体的研发技术颇受关注。基于日本环境省的“为进一步实现碳中和,加速推进应用和普及材料(氮化镓)、CNF(碳纳米纤维)”的方针,日本大阪大学森勇介教授一直致力于以高质量晶圆为基础的半导体研发工作,此次,针对氮化镓研发情况、研发成果对未来功率半导体应用场景的影响等,我们对森教授进行了采访。如今采用了宽禁带材料的功率半导体已经开始实用化。据悉,美国特斯拉(Tesla)的电机(Motor)驱动逆变器(Inverter)采用了碳化硅半导体。此外,应该也有不少读者在家电销售中心等处见过一些采用了氮化镓半导体的极小型交流转换器(AC Converter)。在高电压工作情况下,以宽禁带材料制成的功率半导体的内部线路的电气性能和有效性远远高于硅材质的传统半导体。对已经实现实用化的碳化硅半导体和氮化镓半导体而言,应用终端对其耐电压(Rated Voltage,比额定电压高,是为维持信赖性的基本电压)的要求不同,分别如下,碳化硅耐电压1000V以上,氮化镓耐电压1000V以下。基于上述区分,功率半导体厂家和研发企业之间形成了“无言的默契”。然而,上述情况很有可能发生变化。由于氮化镓材料可大幅度降低晶圆的缺陷(错位)密度,因此可以提高应用终端的性能、效率,且远优于碳化硅材料,所以,氮化镓有望实现大范围量产。如今,研发人员正在努力积累相关数据,以证实上述结论。日本大阪大学的森勇介教授位于上述研发活动的最前沿。氮化镓功率半导体虽然适用性极高,但依然面临三项社会问题仅从物理特性来看,氮化镓比碳化硅更适合做功率半导体的材料。研发人员还比较了碳化硅和氮化镓的“Baliga性能指数(半导体材料相对于硅的性能数值,即硅为1)”,4H-SiC为500,氮化镓为900、效率极高。此外,碳化硅的绝缘破坏电场强度(表示材料的耐电压特性)为2.8MV/cm,氮化镓更高,为3.3MV/cm。一般情况下,低频工作时的功耗损失是绝缘破坏电场的三次方,高频工作时的功耗损失是绝缘破坏电场的2次方,成反比例关系,所以,氮化镓的功率损耗更低(工作效率更高)。那么,为什么在耐高电压应用领域,碳化硅的实用化早于氮化镓呢?理由如下,在制作MOS FET时,碳化硅更易于形成二氧化硅(SiO2)、“氮化镓晶圆面临三大问题点”(森教授)。(下图1)图1:日本大阪大学森勇介列举的氮化镓晶圆面临的问题点。(图片出自:日本大阪大学)第一个问题,由于 Bulk Wafer(氮化镓体块)的尺寸较小,因此之前仅能生产出低成本的晶圆产品,某些产品甚至无法满足测试要求。一直以来,都仅能生产出2英寸晶圆,如今终于可以生产出4英寸晶圆。业界普遍认为只有6英寸以上的大尺寸晶圆才可以满足功率半导体的批量生产需求,所以如今还没有达到可以量产的要求。另外,上文中提到的小型交流转换器(AC Converter)所采用的氮化镓功率半导体采用的晶圆如下,在最大尺寸为6英寸的硅(Si)衬底上形成氮化镓层。但是,由于硅和氮化镓的结晶常数(Lattice Constant)不同,因此氮化镓层的缺陷密度较高、无法形成可以满足耐高电压、大电流的纵型FET,也无法制作高性能的横型HEMT。第二个问题,作为结体块式(Bulk)的氮化镓晶圆本身质量不高。如今的结晶块晶圆的最大错位密度高达106/平方厘米,这种水平的密度水平是不适合功率半导体生产的。但是,2英寸晶圆的倾斜角(Off)的分布(是反映晶圆翘曲度的指标)为0.2度,很难实现大尺寸化和低成本化。但是,上述低质量的晶圆适合用于光学半导体的生产。不过,对于功率半导体而言,电流需要在晶圆的大部分区域流通,所以,错位缺陷成为了耐高电压、电流量、生产良率低的主要原因。要适用于功率半导体,需要满足以下错位密度要求:耐高电压范围需要为0.65~3.3kV,单个芯片(Chip)的电流量为100A以上,生产良率要达到90%(必须实现较低的错位缺陷、较低的翘曲度)。第三个问题,晶圆价格高昂。如今,2英寸晶圆的价格为10万日元一一20万日元(约人民币5220元一一10440元)。之所以价格如此高昂,理由如下:还没有确立一项技术,可以以较高的良率生产出大尺寸晶圆。尺寸为6英寸、价格在10万日元(约人民币5220元)以下的晶圆才适用于功率半导体的量产。成功获得适用于量产功率半导体的、高质量、大尺寸氮化镓晶圆氮化镓晶圆之所以面临上述问题的根本原因在于氮化镓结晶的生长方法。如今量产的体块式(Bulk)氮化镓晶圆的制作方法如下,在蓝宝石衬底(Sapphire)上用一种名为HEPV(Hydride Vapor Phase Epitaxial,氢化物气相外延法,以下简称为:“HVPE”)的气相外延法生成氮化镓结晶。如果把蓝宝石等用作结晶生长的基础材料,由于氮蓝宝石材料与氮化镓的结晶常数(Lattice Constant)不同,因此会发生大批量的错位缺陷。此外,利用“HVPE”,由于是在1000度的高温下生成结晶的,所以在生长后常温冷却时,整个晶圆会出现翘曲,出现倾斜角(Off)。此外,有一种名为“氨热法(Ammono-thermal)”的结晶方法,该方法可生成高质量的结晶,不同于体块式(Bulk)氮化镓晶圆量产工艺中使用的“HVPE”法。“氨热法”作为一种生成人工水晶结晶的方法,采用的是水热合成法(已实现工业化应用)。提高压力容器内氨的温度和压力,使其处于超临界状态,溶解氮化镓多结晶,再在氮化镓种晶(Seed Crystal)上沉淀出单晶。以氮化镓晶种为基础材料、并采用液相生长法,可制作出高质量的单结晶。“但是,利用氨热法,在结晶生长过程中,一旦出现稳定的表面,就会停止生长。基于上述现象的存在,虽然可以制作4英寸晶圆,要想制作出更大尺寸的晶圆,还需要时间的积累。”(森教授)然而,以往无法制作出高质量体块式(Bulk)氮化镓晶圆,近年来情况有了显著改善。已经确立了可以制造出高质量、低成本体块式(Bulk)氮化镓晶圆的技术。日本大阪大学、丰田合成株式会社合作研发了一项可解决上述课题的新技术(下图2),该技术融合了“Na Flux法(钠助溶剂法,利用该方法生长氮化镓结晶)”和“Point Seed 法(点籽晶法,利用该方法实现大尺寸晶圆)”。图2:融合“Na Flux(钠助溶)法”和“Point Seed(点籽晶)法”,使大尺寸体块式(Bulk)氮化镓晶圆的制作成为可能。(图片出自:日本大阪大学)“Na Flux(钠助溶)法”指的是将钠/镓溶液暴露于气压为30一一40的氮气中,将氮溶解于溶液,并使其成为饱和状态,从而使氮化镓结晶析出。这是日本东北大学山根久典教授于1996年研发出的技术。“Na Flux(钠助溶)法”的特点是,即使晶种质量较低,也可以在其表面形成高质量的结晶。但是,仅靠该方法,虽然可以依靠一个小点形成完美的结晶,却无法形成大尺寸结晶。于是,利用“Point Seed(点籽晶)法”,形成大尺寸的晶圆。即在大块基材上大面积分布晶种,在结晶生长过程中,分别合体,形成单结晶。据森教授表示,利用上述方法,可以获得适用于功率半导体量产的理想结晶,其错位密度为104/cm²以下,6英寸晶圆倾斜角分布为0.2度。此外,也已经成功制成了6英寸体块式(Bulk)氮化镓衬底(该尺寸为全球最大)。而且,如果使用尺寸更大的基材、更多的晶种的话,还可以制作出10英寸晶圆,且生产量不会降低。此外,还有另一种方法,即以体块式(Bulk)氮化镓衬底为晶种,使用“氨热法”,可制作出高质量、大尺寸的体块式(Bulk)衬底(如下图3)。针对上述方法,森教授指出:“成本堪比现有的碳化硅衬底,且可以实现较大尺寸。”日本大阪大学和丰田合成株式会社等企业已经参加日本环境省提出的“令和四年度 为进一步实现碳中和,加速推进应用和普及零部件和材料”项目,近期,三菱化学株式会社(拥有“氨热法”技术)也加入了该项目,诸多企业的加入将更有助于项目的实施和验证。图3:融合“Na Flux(钠助溶)法”和“氨热法”。“Na Flux(钠助溶)法”的优势是可使晶圆实现较大的尺寸、较高的质量;“氨热法”的优势是可提高晶圆质量。二者融合后,可以获得比碳化硅成本更低的的氮化镓晶圆。(图片出自:日本大阪大学)可成功提高元件的性能、良率据森教授表示,使用由“Na Flux(钠助溶)法”和“Point Seed(点籽晶)法”制成的氮化镓衬底后发现,氮化镓元件的性能、良率普遍得到提高。日本大阪大学和松下集团合作,利用Na Flux(钠助溶)法,以体块(Bulk)衬底为基础制作了纵型氮化镓FET,并从芯片OFF性能的角度考察了成品率(下图4)。以市场上销售的氮化镓衬底制成芯片的成品率仅为33%,而利用上述方法,则可使成品率大幅度提升至72%。此外,上述成果是基于实验室基础获得的,未来还有很大提升余地。图4:利用“Na Flux(钠助溶)法”和“Point Seed(点籽晶)法”可制作出高质量、大尺寸的氮化硅衬底。(图片出自:日本大阪大学)此外,研究人员已经开始利用“OVPE法(Oxide Vapor Phase Epitaxy,氧化物气相外延法,简称为:OVPE,可用于制作超低电阻的晶圆,由日本大阪大学研发、松下集团推进其实用化)”,在由“Na Flux(钠助溶)法”和“Point Seed(点籽晶)法”制成的晶种上生长氮化镓结晶,以研发更高性能的纵型氮化镓FET。制成的晶圆的电阻约为10-4Ωcm²,远低于碳化硅晶圆(10-3Ωcm²左右)、错位密度为104/cm²、氮化镓膜厚超过1毫米。研究人员获得了一块晶圆,该晶圆有望实现纵型FET。与碳化硅基的纵型MOS FET相比,在性能方面,纵型FET具有更高的潜力(下图5)。与利用传统的体块式氮化镓晶圆制成的芯片相比,实验制作的二极管的ON电阻值降低了50%,纵型FET的OFF电阻值降低了15%(甚至更高)。图5:功率半导体的性能和晶圆特性的关系。利用“OVPE法”,可降低晶圆的电阻。(图片出自:日本大阪大学)在日本环境省的项目中,为实现在电动汽车驱动逆变器中的应用,日本大阪大学着力研发具有超低电阻、高质量、大尺寸的体块氮化镓衬底以及相关其他产品、模组。(下图6)图6:超低电阻、高质量、大尺寸的体块氮化镓晶圆、以及相关应用、模组的开发计划。(图片出自:日本大阪大学)快速退火炉,RTP
应用实例
2023.02.08

中标喜讯---清华大学签手量伙半导体
量伙半导体在2022年12月招标的“清华大学快速热退火系统购置项目”,喜获甲方一致好评,中标该项目。预祝合作顺利!清华大学(Tsinghua University)是中国排名最高的学府之一,位于北京市海淀区,是中华人民共和国教育部直属的全国重点大学,位列国家“双一流”、 “985工程”、“211工程”,入选“2011计划”、“珠峰计划”、“强基计划”、“111计划”,为九校联盟 、松联盟、中国大学校长联谊会、亚洲大学联盟、环太平洋大学联盟、中俄综合性大学联盟 、清华—剑桥—MIT低碳大学联盟成员、中国高层次人才培养和科学技术研究的基地,被誉为“红色工程师的摇篮”。 8寸快速退火炉RTP产地:中国型号: LH-RTA-D,LH-RTA-D-H,LH-RTA-D-R--------------------------------------------------------------------------------------简介(Description):适用于单片最大8寸(200mm*200mm)晶体化合物等半导体材料进行快速热处理、退火等工艺。使用基于Windows 10系统的Larcomse专用控制软件,可快速上手操作,亦方便读写存数据,全中文软件界面(可定制语言和模块),能实时显示工艺曲线、气体流量、冷却水等各种数据;具有多种自动保护功能。可配置多种气氛通路,能抽真空,根据实验方向进行多样化定制。独有专利的温控系统,可以多温区实时同步闭环PID控制,能进行精度±0.5℃的温控操作,以及保障更可靠的重复性操作。采用的双面加热方式与单面加热相比,可以大幅减小图案加载效应,使晶片的热均匀性更好。可选配高温计,机械手Robot。--------------------------------------------------------------------------------------定义(Definition):快速热处理(RTP)设备是一种单片热处理设备,可以将晶圆的温度快速升至工艺所需温度(200-1300℃),并且能够快速降温,升/降温度速率约20-250℃。RTP设备还具有其他优良的工艺性能,如极佳的热预算和更好的表面均匀性,尤其对大尺寸的晶圆片。多用于修复离子注入后的损伤,多腔体规格可以大幅提高产能产量,也可以实现不同工艺同时加工。--------------------------------------------------------------------------------------设备主要工艺应用(Application):●快速热处理(RTP),快速退火(RTA),快速热氧化(RTO),快速热氮化(RTN);●离子注入/接触退火;●高温退火;●高温扩散;●金属合金;●热氧化处理。--------------------------------------------------------------------------------------设备主要应用领域(Field):●化合物半导体(磷化铟、砷化镓、氮化镓、碳化硅等);●多晶硅;●太阳能电池片;●MEMS等传感器;●二极管、MOSFET及IGBT等功率器件;●MiniLED、MicroLED、CMOS等光电器件;●IC晶圆。
企业动态
2023.01.17

深入解读DALI和Zhaga:两种LED照明标准及其连接器选型
发光二极管 (LED) 彻底改变了室内外照明。这种固态照明 (SSL) 技术拥有出色的效率、可控性、色谱、热性能以及独特的外形,正将古老的爱迪生白炽灯泡(以及荧光灯、金属卤化物灯或钠蒸汽灯)淘汰出局。现在,大多数室内外新设计以及现有设计的升级改造,都会首先考虑LED。不过,在这个过程中,设计人员仍要小心,因为在快速创新的同时,也会出现一些隐患,比如非标连接和终端用户解决方案错配,这些都会造成负面的客户体验。这是因为,LED照明彻底改变的不仅仅是光源本身。例如,LED照明也在改变连接器的设计和外形及其固定装置(称为灯具),这些连接器是任何照明系统的必要组成部分,它们不接受交流线路电压,而是接受较低的直流电压,典型电流通常在3安培 (A) 至7A之间。此外, LED照明系统通常是支持数字可寻址照明接口 (DALI) 和Zhaga行业标准的控制网络的一部分,并作为智能家居或办公的关键一环提供智能、节能、高性能的照明。因此,在进行LED照明系统设计之前,工程师需要熟悉这些标准及其对现实世界连接器的影响,因为新的设计正在迅速兴起。本文简要回顾了为什么LED会如此普及,然后介绍并描述了这两种连接标准,以确保智能LED设计的互操作性、快速开发和轻松部署。最后介绍了Amphenol Communications Solutions (ACS)的连接器,并通过这些连接器的实际用例,帮助大家了解相关标准及其应用。为什么LED如此普及LED发展成为照明光源有很多促进因素:成本降低推动产量提高,进而进一步推动成本降低、产量提高LED作为光源的基本可靠性和寿命的增强电路改进,主要是驱动这些LED的电源改进智能控制装置甚至网络I/O的使用提高了对LED的控制便利性以色温(开尔文)和显色指数 (CRI) 为特征的光学输出质量的改善政府为提高照明效率以节约能源而采取的激励、标准化和强制措施(据估计,照明占总能耗的15%至20%)行业和政府标准的制定,这些标准确保了LED光源之间的互操作性以及与智能控制器的兼容性。最后一点尤为重要。传统白炽灯泡有一个重要的尺寸种类就是“E26”,即26毫米 (mm) 直径的爱迪生螺口灯泡,这在美国和许多其他国家的住宅环境中几乎普遍使用(图1),正被LED 和荧光灯泡所取代,但程度还较小。当然还有其他尺寸,如E12底座,但E26是目前使用最广泛的。图1:26mm E26爱迪生底座是目前使用最广泛的灯泡底座,不过也有一些更小和更大的底座,可满足不同的应用需求(图片来源:LOHAS LED Ltd.)当然,标准化为单一底座和插口可以降低成本。这种技术还催生出多种灯泡形状、功率水平以及围绕这种基础打造的其他属性,同时减少了对长期更换烧坏灯泡的担忧。早期几代LED灯泡采用E26底座,以兼容现有插口,让用户习惯于LED照明。这些E26 LED灯泡仍在广泛销售,因为目前有无数个这样的插口在使用,所以替代过程时间将会很长。 然而,与白炽灯相比,LED在电流、电压(直流)和功耗方面有很大的不同,白炽灯泡通常使用120/240伏交流电供电。另外,E26插口的导线往往有比较大的螺纹端子,这对于LED光源供电来说并不理想(图2)。因此,为了让LED从系统层面到物理连接层面都能充分发挥其潜力,需要新的标准和连接器类型。图2:E26插口接线所需的大螺纹端子影响了对LED光源的最佳利用(图片来源:Family Handyman via Pinterest)认识到现代照明接口标准的需求后,数字照明接口联盟 (DiiA) 开发了DALI标准。 DALI标准重新定义了照明连接 DALI是一个数字照明控制的专用协议,能够轻松实现牢固、可扩展和灵活的照明网络安装(图3)。第一个版本DALI-1更适合用于荧光灯镇流器的数字控制、配置和查询,考虑LED的因素较少。它取代了现有0/1至10伏模拟控制方式的简单、单向、广播式操作。 图3:DALI标准的第一个版本定义了一个控制基础,将所有由并联市电交流电源线供电的设备联系起来。(图片来源:Omnialed)该标准还包括一个广播选项,通过简单的重新配置,每个DALI设备可以被分配一个单独的地址,允许对单个设备进行数字控制。此外,DALI设备还可以通过编程进行分组操作,这样就可以通过软件对照明系统进行重新配置,从而避免改变布线。随着用户期望的增长以及LED技术的改进,促进了现在DALI-2标准的发展。DALI-2不仅仅是一个行业标准,现在也是国际电工委员会的标准 (IEC 62386)。DALI-2增加了许多新的命令和功能。DALI-1只包括控制模式,而DALI-2则涵盖了控制设备,如应用控制器和输入设备(如传感器),以及总线电源。其重点放在不同厂商产品的互操作性上,并有DALI-2认证计划提供支持,以确认产品与规范的兼容性(图4)。图4:与DALI-1相比,DALI-2标准更多地考虑了LED的需求,同时也增加了新的命令和更新。(图片来源:DALI 联盟)与所有的综合标准一样,DALI-2也很复杂。简而言之,用单线对作为总线,DALI网络上的每个设备都可以单独寻址。总线同时用于提供信号和电源,支持的电源能在16伏直流电压(典型值)下提供最高250毫安 (mA) 的电流。该标准支持由交流线路或直流电源轨供电的设备。虽然有各种标准对超低电压 (ELV) 进行了定义,但IEC对ELV设备或电路的定义是:电导体与接地间的电势差不超过交流50伏或直流120伏。DALI控制电缆被归类为ELV设备,因此只需要与交流市电保持基本绝缘;它可以跟市电线路或包括市电线路的多芯电缆一起走线。超越DALI-2:Zhaga规范瞄准了灯具 DALI-2等标准固然重要,但也只能到此为止。界定如何将标准与具体应用(如LED照明和灯具)联系起来不在其定义范围内。为解决这一问题,国际Zhaga联盟制定了LED灯具所用元器件的接口行业规范。该联盟是IEEE行业标准与技术组织的成员项目,截至2019年,已有120多家成员。要搞清照明设备和灯具的区别,现在正是时候。照明工程协会(IES) 照明手册、ANSI/NEMA标准和IEC都使用了“灯具”一词。它于2002年被添加到《美国国家电气规范》(NEC) 手册中,其正式定义为“一个完整的照明单元,由一盏或多盏灯以及设计用于分配光线、定位和保护灯管以及将灯管连接到电源的零部件组成”。灯具包括灯和所有直接与照明装置的分布、定位和保护有关的零部件,具体不包括支撑部件,如臂、筋或杆;用于固定灯具的紧固件;控制或安全装置;或电源导线。灯具的形式多种多样,适用于各种场合,从功能严格的户外街道照明到室内办公照明,甚至是“时尚”的零售或家居照明。“照明设备”在NEC中没有定义,一般是指用户心目中的任何东西,可能包括以下一些或全部要素:灯管(灯泡),或许带灯罩、灯球、透镜或漫射器、支架、灯杆或灯具配件,以及其他要素。Zhaga规范正式名称为Books(规格书),针对电气、机械、光学、热学和通信接口,并允许组件的互操作性。通过遵守Zhaga规范,设计人员可以确保用户拥有可互操作、可更换或维修的组件,并确保LED灯具在安装后可在新技术出现时进行升级。Zhaga规范正式名称为Books(规格书),针对电气、机械、光学、热学和通信接口,并允许组件的互操作性。通过遵守Zhaga规范,设计人员可以确保用户拥有可互操作、可更换或维修的组件,并确保LED灯具在安装后可在新技术出现时进行升级。Zhaga Book 18和Book 20对使用LED灯具的设计人员来说特别有用;前者侧重于户外设计,而后者则是针对室内应用。Zhaga Book 18:“户外灯具与传感/通信模块之间的智能接口”规定了电源和通信方面的内容,此外还规定了1.0版定义的连接系统的机械配合和电气引脚。它简化了应用模块的添加,如添加传感器和通信节点到LED灯具,并确保了即插即用的互操作性。Zhaga Book 20:“室内灯具与传感/通信模块的智能接口”定义了室内LED灯具与传感/通信节点的智能接口。该节点连接到LED驱动器和控制系统,通常可以提供传感器输入或实现网络组件之间的通信。节点可以在现场安装和更换。连接器完成电路当然,标准是至关重要的,而兼容性和互操作性是从物理接口及其连接器开始的(图5)。DALI规范和Zhaga标准的使用得到了广泛的连接器支持,这些连接器满足(甚至超过)其要求,同时为用户在不同场景下的操作提供了灵活性。图5:DALI规范和Zhaga标准提供了一个完整的电缆和连接器连接路径,用于各种配置的电源到照明LED的电源和数据连接。(图片来源:ACS)针对室内使用,Zhaga Book 20定义了智能建筑网络中传感器的可分离配接接口。ACS FLM系列符合DALI标准,可实现室内LED灯具和传感器或通信模块的“即插即用”操作性。事实上,Zhaga联盟选择了Amphenol FLM系列作为Zhaga Book 20的标准。ACS FLM系列的两个互补成员展示了Book 20的实际操作标准:FLM-P21-00 SSL双触头连接器插座外壳用于插针触头电缆/电线到电缆/电线的连接,而FLM-S21-00 双触点SSL插头外壳用于插口触头电缆/电线到电缆/电线的连接。其他表面贴装技术 (SMT) 型号具有直角和垂直配置,可实现设计灵活性(图6)。图6:FLM-P21-00插座外壳和与之配套的FLM-S21-00插头外壳是基本型两线SSL连接器。(图片来源:ACS)该系列的特性包括:可分离接口采用“防呆”几何形状(意为“傻瓜式”或“防错式”),可确保正确对接带有免工具插入式端子的可用插头一体化扁平凹陷锁扣功能,提供5牛顿的最小固位力,以确保安全配接,同时又能轻松拆除。插头可用卷轴提供,带有压接插座触头或插入式导线端子选件,允许大批量装配或易于现场装配/维修。当然,很多目标LED应用并不像普通的室内环境那样容易搞定。FLH系列线对线IP67级(密封和防水)连接器可以满足此类应用的要求,包括FLH-P31-00(间距为2.50mm的三位矩形外壳插座)和配套的FLH-S31-00矩形外壳插头(图7);同时还提供多至六个触头的版本。图7:对于需要IP67防护等级的LED和其他连接器应用,FLH系列提供了三线FLH-P31-00矩形外壳插座(左上角)和配套的FLH-S31-00矩形外壳插头(右上角),以及2、3、4和6针位版本。(图片来源:ACS)该系列连接器的密封和防水性能使其特别适合恶劣环境,可用于照明以及HVAC、工业和智能家居等场合,同时其紧凑的设计也具有节省空间的优势。这些连接器中的触头规格可用于不同的线径和相应的电流:18号美规 (AWG) 线,8A;20号AWG线,5 A;低至22号AWG线,3A。安装不仅仅事关电源连接器。为了完成设计项目,Amphenol提供了其他关键组件,包括FLA-2141-30,这是一种符合ANSI C136-41标准的插座,用于将道路、街道和停车场应用中的户外灯具连接到光电池,以实现调光功能(图8)。除了这种两触头版本,还有无触头和四触头版本。图8:符合ANSI标准的FLA-2141-30调光插座用于在用户提供的调光器和灯具之间提供连接。该产品适用于由可用环境光控制的智能照明(所示为四触头变型)。(图片来源:ACS)为了实现更高级的传感器集成,可以添加一个FLB-P底座来代替光电池。这样一来,就可以在印刷电路板上加装传感器,实现其他各种功能,如运动检测、空气质量、声音检测等。然后可以通过添加FLB-C圆罩来保护整个组件。注意:这些产品不适合在室内使用。Amphenol还提供了FLB-C70-501-001圆罩,这是一种NEMA ANSI C136.41半透明罩,直径76mm,高130mm,设计用于FLB-P底座。FLA系列调光插座可与符合ANSI C136.10标准的光电池或盖帽(开路或短路)一起使用。如需实现额外传感器集成,设计人员需要:FLA插座FLB-P底座带传感器的电路板FLB-C保护罩最后,FLS-SB80-02灯具扩展模块 (80mm) 允许将调光组件提升到FLA系列插座上方,以连接调光和传感器模块。 本文小结LED照明已经极大地改变了工业、商业和住宅的室内外照明。它将能效、长寿命和灯具配置的灵活性近乎完美地结合在一起。为了简化和加速LED设计导入,ACS推出了各种系列的连接器,在满足室内外和IP67级要求的同时,也满足了Zhaga行业标准,从而提高了系统的兼容性和互操作性。
应用实例
2023.01.12

MCU的一段往事!
在德州仪器 (TI) MOS 部门工作的加里·布恩 (Gary Boone) 设计了第一款可以称为微控制器的芯片,因为他对自己的工作感到厌烦,而且他的家庭也遇到了麻烦。他于 1969 年加入 TI,当时计算器芯片正成为一项大生意。在20世纪60年代,电子计算器取代了占据市场数十年之久的Marchant和Frieden机电计算器。半导体使机电计算器中数百个复杂的金属和塑料部件得以取代,首先是数百个晶体管和二极管,然后是越来越少的集成电路。北美的罗克韦尔微电子,Mostek,通用仪器和德州仪器是多芯片计算器市场的早期参与者。起初,需要几十个集成电路来取代数百个晶体管和二极管。随着集成电路中包含的元件越来越多,制造一个可用的计算器所需的集成电路也越来越少。到1968年,基于IC的计算器设计在很大程度上取代了基于晶体管的设计。终点是明显的。最终,半导体制造商将把计算器的电子内核简化为单个芯片。日本计算器供应商夏普、佳能和Busicom与各种美国半导体供应商合作,为他们的计算器开发定制芯片。夏普与罗克韦尔合作,佳能与TI合作,Busicom与Mostek和英特尔合作开发不同型号的计算器。Busicom要求Mostek开发单芯片计算器,并与英特尔签订合同,为更复杂的可编程计算器开发定制芯片组。1970年底,Mostek首次实现了这一目标,推出了MK6010,这是一款取代了 22 块集成电路的定制芯片。Busicom将这种芯片集成到它的小型四功能台式计算器Busicom Junior中。与英特尔的合同最终促成了英特尔4004微处理器的开发。然而,这个故事是关于微控制器的,它走了一条相关但不同的进化道路。TI公司的MOS部门深陷计算器芯片组的事务之中。包括佳能、Olivetti和Olympia 在内的计算器公司要求TI为他们的计算器开发4、5和6芯片组。执行这些定制芯片项目落在了包括Gary Boone在内的几个TI工程师的肩上。这份工作需要飞往世界各地,去日本、意大利和德国。布恩花了很多时间在路上,他的家人对他的缺席感到不满。Boone很快就厌倦了紧张的旅行,只是为了开发一个看起来和之前的很像的新芯片组。在那个年代,许多潜在客户想要计算器芯片,但每个客户想要的东西都有点不同。这就是定制芯片业务的本质。这是一个客户密集型的行业。Boone的沮丧和家庭事务促使他找到了TI的MOS市场经理Daniel Baudouin。他们一起编制了一个客户需求矩阵,这些需求来自与不同计算器制造商的需求。然后,他们添加了一组功能块,可以满足这些需求。Boone和Baudouin也注意到目前TI MOS工艺技术可以完成什么,以及它可以做得最好的是什么。他们的思路很快转向了大量使用内存(RAM和ROM)的架构,因为这些结构效率极高,更容易在IC上布线,内存有望提高硅的利用率,达到40或50倍。一旦Boone和Baudouin开始考虑使用内存,他们就开始考虑一个计算器芯片需要多少数据和程序存储空间。那时,TI团队开始与潜在客户讨论ROM可编程的单芯片计算器的前景。他们遭到了很多反对。习惯了为自己的计算器芯片提供资金的客户对只通过片上ROM中的某些位进行区分的计算器芯片的想法犹豫不决。TI内部也有反对意见,因为基于ROM的可编程部件与公司习惯制造的部件相反。读到这里,您可能会发现所有关于计算器芯片的讨论都与标题不一致。本系列文章显然是关于微控制器的历史。我向你保证,我们没有偏离轨道。最早的微控制器是由Boone和TI的工程师Michael Cochran设计的,包括处理器、内存(RAM和ROM)和I/O都在一块硅上,是计算器芯片,它们是最早的微控制器。请看下图,摘自美国专利4074,351:图片来源:美国专利商标局此图显示了TI第一台单片机计算器TMS1802NC的框图。它显示了微控制器的所有关键组件。它有一个CPU,由程序计数器(PC)、指令寄存器(IR)、指令解码器(Control Decoders)和一个4位ALU组成。它有一个RAM来存储数值数据和一个ROM来存储定义芯片操作的程序。最后,在底部,您可以看到专门的I/O电路,用于扫描矩阵键盘、驱动显示数字和驱动每个显示数字中的七个段。这个设计中的I/O可能是专门的,但是这个图清楚地描述了一个微控制器。1971年9月17日,TI公司发布了TMS1802NC单片机计算器集成电路。两个月后,英特尔发布了4004微处理器。德州仪器给这款设备定价不到20美元。ROM包含320个11位指令字(3520位),而串行访问的182位RAM包含3个13位BCD(二进制编码的十进制)数字和13个二进制标志位。该芯片总共需要大约5000个晶体管。(注:在研究这篇文章时,我发现不止一个网站把TI的TMS1802NC 4位计算器芯片和1974年发布的8位RCA CDP1802 COSMAC CMOS微处理器搞混了。TI和RCA芯片不是同一个零件,尽管零件号相似。)TI从1971年9月17日发布的新闻稿进一步证实了TMS1802NC作为微控制器的地位:“TI使用相同基础或主机设计的单级掩码编程技术,可以轻松实现任何数量的特殊操作特征。唯一的限制是程序ROM、RAM存储和控制、定时和输出解码器的大小。例如,通过重新编程输出解码器,TMS1802可以用于驱动十进制显示,如Nixie型管。”最早使用TI TMS1802计算器芯片的计算器之一是Sinclair Executive。Sinclair Executive是一个非常早期的袖珍计算器,包含了TMS1802单片机计算器。图片来源:MaltaGC, Wikimedia CommonsTI在1972年9月20日发布了TMS0100单片机计算器系列,几乎正好是在TMS1802C发布一年后。该公司将TMS1802NC重新命名为TMS0100家族的第一个成员,TMS0102。最终,这个家族将有超过15个不同的成员,由TI的10微米PMOS工艺技术制成。一年后,Mostek发布了改进的、引脚兼容的TMS0102副本MK5020。就像本文开头列出的所有半导体制造商一样,TI和Mostek很快就会发布微控制器,部分是利用从这些早期计算器芯片的创造中获得的知识开发的。与此同时,Boone已经跳出了这个计算器的框框。计算器芯片专利4,074,351描述了其他目标应用,包括出租车计价器、数字电压表、事件计数器、汽车里程表和测量秤。当然,微控制器已经在所有这些应用程序中被使用过,而且还远远不止这些。与许多首创设备一样,德州仪器的TMS0100计算器芯片家族是一种狭义的微控制器,主要用于制作计算器。然而,TMS0100家族的第一个芯片最初被称为TM1802NC,后来改名为TMS0102,它包含了微控制器所需的一切:CPU、RAM、ROM和I/O。当然,这是一个专门的微控制器。它的I/O是特定于应用程序的,被设计为连接到一个矩阵键盘和一个七段显示器。然而,TMS1802NC是一个微控制器。最初由德州仪器的Gary Boone和Daniel Baudouin构想,然后由Boone和Michael Cochran实现,德州仪器在1972年9月20日推出了TMS0100系列,这些芯片迅速占领了计算器市场。TI突然有了全新的世界要征服。该公司很快意识到,如果可以将同样的可编程硅设计得足够通用,它就可以为多个市场服务。TI将其从最初的可编程计算器芯片中获得的经验应用于生产第一批通用微控制器TMS1000系列,并于1974年发布。TMS1000微控制器系列与TMS0100可编程计算器系列有一些相似之处,但也有很多不同点。这两种设备都有4位CPU和哈佛架构,哈佛架构为RAM和ROM提供了独立的地址空间。哈佛架构在早期微控制器设计中很常见,因为它们简化了微控制器的RAM、ROM、地址解码器和数据总线的设计。然而,在我看来,哈佛架构使程序员的生活变得复杂,他们必须跟踪两个不同的地址空间,并且必须经常设计将数据从ROM转移到RAM的方法。(幸运的是,将数据从RAM转移到ROM是没有意义的,数据不会完成这个过程。你不能成功地写入一个掩码ROM。)与TMS0102的3250位ROM(组织为320个11位字)不同,第一个TMS1000微控制器有一个1千字节的ROM,组织为1024个8位字。因此,TMS0100和TMS1000系列分别从不兼容的11位和8位指令集开始。类似地,TMS0102的182位串行RAM包含三个以BCD(二进制编码十进制)格式的13位数字和13个二进制标志,而 TMS1000 微控制器具有组织为 64 个 4 位字的 256 位 RAM。根据TMS1000文档,存储在RAM中的64个4位单词“被方便地分组为4个16位的文件,由一个2位寄存器寻址”。根据我的经验,在编写类似的微控制器架构时(本系列后面将讨论),将小的RAM地址空间进一步分割成16个字的块并没有什么方便之处,除非您正在编写16个条目的循环缓冲区。就像许多设计妥协一样,微控制器设计团队将整个CPU连同RAM、ROM和I/O电路一起塞到早期的半导体模具上,我敢打赌,这个特定的设计选择使TMS1000微控制器的硬件设计更简单、更小,以通常牺牲程序员的方便来换取硬件设计的便利。与TMS0100计算器芯片系列的专用I/O设计不同,TMS1000微控制器具有通用I/O引脚,至少在名义上是这样。四个输入引脚(K1, K2, K4和K8)可以用一条指令作为一组读取。输出引脚更加复杂。最初的TMS1000微控制器有11个“R”输出(R0到R10)和8个“O”输出(O0到O7)。“R”输出分别设置和清除。“O”输出由掩模编程PLA控制,并由5位锁存器驱动。锁存器中的四个位可以通过一个指令来设置,该指令将数据直接从TMS1000的累加器移动到锁存器。第五个输出位来自ALU的状态锁存器。使用PLA将5位输出锁存扩展到8个输出引脚,让人想起TMS1000作为计算器芯片的后代的传统,它被设计用于驱动7段显示器。在Adam Osborne 的众多成就中,他在1978年出版的《微型计算机导论》一书中记录了早期的微处理器和微控制器。在他对TMS1000的描述中,奥斯本似乎更关注微控制器的局限性:“TMS1000系列微型计算机是单芯片设备的事实有一些次要的,不明显的影响。最重要的是,没有支持设备这种东西。1024或2048字节的ROM [TMS1200微控制器有2Kbytes的ROM]代表将出现的程序内存的确切数量;不能多也不能少。类似地,RAM的64或128个字节(一个字节是一个4位的单词)不能扩展。直接内存访问逻辑不存在——而且它的存在无论如何都没有什么意义;由于可用的RAM和ROM总量很小,因此根本没有机会在足够长的时间内传输数据块,以保证绕过CPU。同样地,在TMS1000微型计算机中,中断的作用是微不足道的。考虑到可用的程序内存储量很小,而且程序包的成本很低,很难证明仅仅为了让微机执行多个任务而中断逻辑的复杂性是合理的。”在我看来,Osborne 的话表明,许多人(可能包括Osborne )在1978年他出版那本书时,也就是TI首次宣布TMS1000系列四年后,并没有清楚地了解微控制器和微处理器之间的区别。然而,许多人确实理解其中的区别,因为据报道,到1979年,TI每年生产数千万个TMS1000部件,他们以2美元或3美元的价格大批量出售TMS1000。TMS1000的低单位成本是可能的,部分原因是TI将该设备封装在一个便宜的28引脚塑料DIP中。TI提供了廉价的28引脚塑料DIP的低成本TMS1000微控制器。图片来源:Antonio Martí Campoy, Wikimedia CommonsTI通过在自己的一些消费品中使用TMS1000微控制器家族成员来吃自己的狗粮,包括传奇的TI Speak & Spell游戏和SR-16“电子计算尺”计算器。TI使用自己的TMS1000微控制器创建了TI Speak & Spell。图片来源:FozzTexx, Wikimedia Commons发明家、游戏设计师、“家用电子游戏机之父”拉尔夫·贝尔意识到他可以用微控制器制作出价格合理的电子游戏,并将TMS1000集成到最成功的手持电子游戏之一—— Milton Bradley 的 Simon 中,该游戏于1978年推出。如今,每个人都在自己的手机上玩手持游戏,但那时,这些游戏需要专用的硬件。Milton Bradley的手持电子游戏《Simon》是一款早期产品,采用了TI的TMS1000微控制器。图片来源:shritword, Wikimedia Commons帕克兄弟公司在1978年发布了基于TMS1000微控制器的手持电子游戏《Merlin 》,一年后,Milton Bradley公司使用TMS1000微控制器作为其Big Trak的可编程大脑,这是一种未来主义的6轮坦克式车辆,可以通过嵌入在玩具背后的薄膜键盘预先编程,沿着特定的路径前进。Big Trak可以执行输入键盘的16个命令序列,这似乎与1967年由Wally feurzeeig、Seymour Papert和Cynthia Solomon在马萨诸塞州剑桥的一家名为Bolt、Beranek和Newman (BBN)的研究公司开发的Logo编程语言的海龟图形密切相关。Milton Bradley在Big Trak玩具车上使用了TMS1000微控制器。图片来源:Martin Ling, Wikimedia Commons1977年,Mattel公司推出了一款非常成功的电子足球游戏。这款游戏基于Rockwell计算器芯片,但世界各地的公司都克隆了这款游戏,香港一家名为Conic的游戏制造商似乎在其克隆产品中使用了TMS1000微控制器,而不是计算器芯片。开源游戏模拟器MAME (multi街机模拟器)仍然可以在模拟中运行《Conic’s Football》的TMS1000 ROM代码。作者Stan Augarten在他的《艺术状态》一书中指出,TMS1000被用于计算器、玩具、游戏、电器、防盗报警器、复印机和自动点唱机。奥加滕在描述TMS1000的结尾写道:“和任何集成电路一样,TMS1000帮助使现代电子的力量为每个人所用。”我怀疑还有无数没有记录的TMS1000家族应用程序存在。对于第二早期的微控制器家族来说,这是一个相当成功的故事和遗产,也证明了基本单芯片微控制器概念的真正普遍性。在1974年TI推出TMS1000之后,其他半导体厂商推出的新的微控制器以飞快的速度出现。现在我们已经进入了21世纪,大多数人很少想到罗克韦尔微电子与微处理器和微控制器的联系。母公司北美罗克韦尔(1973年更名为罗克韦尔国际公司)是一家主要的军事/航空航天承包商。罗克韦尔建造了阿波罗飞船,B1轰炸机和美国航天飞机。在很长一段时间里,美国大部分的太空助推火箭和洲际弹道导弹都使用了罗克韦尔的Rocketdyne发动机。1972年,罗克韦尔推出了世界上第三个商业上成功的微处理器,4位的PPS-4。1976年,罗克韦尔发布了基于PPS-4架构的单芯片微控制器。它被称为PPS-4/1。正如20世纪60年代许多大企业集团的潮流一样,罗克韦尔于1967年在其自主事业部开始了自己的半导体制造业务。Autometics开发了各种军事/航空航天航空电子系统,包括用于美国潜艇和洲际弹道导弹的惯性导航和制导系统,这创造了对先进半导体的需求。北美罗克韦尔微电子公司(NRMEC)为其军事和航空航天项目开发了早期的MOS/LSI工艺技术。当日本的夏普向一家半导体供应商来制造自己设计的计算器芯片组时,NRMEC的MOS/LSI能力符合夏普的需求。合作的结果是一个四芯片组,夏普将其纳入其QT-8D计算器。夏普在1968年8月发布了这款计算器。事实上,有人可能会说,夏普QT-8D计算器中的罗克韦尔芯片组开启了MOS/LSI时代。1970年,罗克韦尔开始出版MOS/LSI芯片目录。正如德州仪器公司(Texas Instruments)在TMS1000微控制器上所发现的,从电子计算器架构到4位微处理器,或者在德州仪器公司(TI)的情况下,到微控制器,只是一个短暂的跳跃。罗克韦尔在1972年8月宣布了4位PPS-4微处理器系列。它是世界上第三个获得商业成功的微处理器,它的推出紧随英特尔发布的4位4004和8位8008微处理器。罗克韦尔的“PPS”名称意为“并行处理系统”。有两点使罗克韦尔的PPS-4微处理器区别于其竞争对手。第一个是罗克韦尔独特的QUIP (Quad Inline Package)设备封装。罗克韦尔的QUIP芯片很容易通过交错的引线来识别。因为它们的样子,这些芯片通常被称为“蜘蛛”。在最小电路板走线和空间大约为 10 密耳左右的时代,QUIP 引线配置使得为这些设备设计印刷电路板变得更加容易。第二个显著特点是罗克韦尔为PPS-4微处理器开发的配套芯片。到1975年,芯片组家族包括CPU、罗克韦尔独特的四相时钟所需的时钟生成器/驱动程序、256×4-bit RAM、1和2千字节ROM、RAM/ROM组合芯片、键盘和显示控制器、打印机控制器、通用I/O芯片和1200 bps模拟调制解调器。(1200 bps模拟调制解调器开启了一长串调制解调器芯片,导致NRMEC成为Conexant Systems,最终被Synaptics收购。)罗克韦尔PPS-4微处理器家族中大量的芯片使得该处理器被广泛应用于终端产品,包括收银机、传真机、家用电器、弹球机、玩具和计算器。然而,多芯片、4位微处理器家族的市场是短暂的。半导体技术发展迅速,器件密度也以惊人的速度增加。1975年10月,罗克韦尔将时钟产生器集成到微处理器中,并将RAM、ROM和I/O外围设备合并为一个名为PPS-4/2的2芯片集,但由于半导体工艺技术的进一步进步,2芯片集也很短时期。1976年初,罗克韦尔发布了PPS-4/1,这是一种基于原始PPS-4微处理器架构的真正的单片微控制器。罗克韦尔 PPS-4/1 微控制器封装在公司独特的 QUIP(四线直插封装)中,由于显而易见的原因也被称为“蜘蛛”芯片。图片来源:Christian Bassow,维基共享资源除了关于基于PPS4的计算器的信息和一个相当不寻常的应用程序:Gottlieb弹球机之外,因特网上很少有关于罗克韦尔PPS-4应用程序的历史。Gottlieb与Rockwell签订合同,开发基于PPS-4/2微处理器的System 1弹球控制器板。Gottlieb在1977年至1980年发行的弹球机中使用了System 1板。第一台使用了System 1板的弹球机被称为“埃及艳后”。其他基于微处理器的弹球游戏也紧随其后,如《Sinbad》,《Dragon》,《Charlie’s Angels》,《Incredible Hulk》,《Buck Rogers》和《Totem》。这个系列共有16场弹球游戏。Gottlieb的图腾弹球机采用了基于Rockwell PPS-4/2微处理器的System 1 CPU板。图片来源:Frédéric BISSON, Wikimedia Commons这是一种很容易被时间遗忘的历史,但是PPS-4作为弹球控制器的历史却没有被遗忘,原因有二。首先,收藏家根据系System 1板奖励Gottlieb弹球机。其次,这些板上的金属门、MOS/LSI PPS-4 rom /外围芯片正在失效,现在它们已经接近半个世纪的历史了。通常情况下,弹球收集器在这些部件失效后会被困在报废的机器上,因为这些部件已经几十年没有生产了,而半导体供应商NRMEC早就不在了。Gottlieb与Rockwell签订合同,设计基于PPS4/2微处理器芯片组的System 1弹球控制器板。图片来源:Stephen Emery, ChipScapes.com法国的AA55咨询公司针对这个问题开发了一种解决方案。该公司开发了基于FPGA的Rockwell PPS-4外围芯片。AA55咨询公司的FPGA代码的目标似乎是由AMD/Xilinx制作的,因为项目文件是为Xilinx的ISE开发软件格式化的。AA55咨询公司还没有对PPS-4/2处理器进行逆向工程,但计划在未来这样做。也许明年吧。由于罗克韦尔组件现在几乎是纯的unobtanium,位于纽约Honeoye Falls的NI-Wumpf公司开发了一种功能上替代了最初的Gottlieb System 1板,并且不使用任何罗克韦尔半导体的板。最初的NI-Wumpf板似乎基于Zilog Z80微处理器。最新版本使用了STMicroelectronics STM32F103微控制器,其中包含了一个72 MHz Arm Cortex-M3处理器。作为比较,PPS-4/2微处理器的工作频率为199kHZ。一家名为Flippp的法国公司!已经采取了类似的方法,开发了被称为PI-1和PI-1×4的系统1板的板级替代品,由Pascal Janin设计和编程。该板似乎也基于更现代的微控制器。阅读一些基于系统1板的Gottlieb弹球机用户的评论是很有趣的。大多数人认为罗克韦尔只是一个严格意义上的国防承包商。一个叫做pinwebsite的网站专门为Gottlieb开了一个论坛,其中有一个主题是“为什么Gottlieb的系统1如此糟糕?”以下是来自这个帖子的一些引用:“当时,罗克韦尔似乎是个不错的选择。毕竟,他们为美国宇航局和国防部设计了计算机设备,还能出什么问题呢?显然,有很多。罗克韦尔公司决定在接地方面做出有问题的决定,使用定制设计的组件和其他奇怪的东西,这真的把戈特利布搞砸了。”“为什么罗克韦尔要花费额外的时间和精力来设计定制蜘蛛芯片,因为它们仍然不如威廉和Bally使用的现成68xx芯片?”采用定制硬件似乎很难为他们节省成本。”Gottlieb并不知情, 过程中做出了一些错误的选择。至于罗克韦尔公司,你可能会想,更大的奇迹是什么:是弹球机成功了,还是他们的NASA产品成功了?”我想罗克韦尔在蜘蛛方面使用的是对他们来说“现成的”部件。部分问题可能在于他们从未为弹球游戏所处的环境设计过硬件。期望开关在打开时出错,而不是砰地一声关闭? 对于国防工业以外的任何人来说,硬件不是“现成的”吗?“我不想太政治化,这只是我的看法,如果我想雇用一家公司为我设计一些电子产品,即使罗克韦尔有一个好名字,我也不想雇用一家习惯于做政府项目的公司。在大多数情况下,它们都是臃肿的、昂贵的、过度设计的。我不确定70年代末的情况是否如此,但仅仅因为太空设备运行良好,并不意味着它没有定价过高和设计过度。”“罗克韦尔将该系统设计为4位系统——这在它发布之前就已经过时了。”毫无疑问,今天以收集弹球机为爱好的人不知道罗克韦尔在20世纪70年代是一家商业芯片供应商,不知道PPS-4有悠久的历史,不知道为什么要开发4位微处理器和微控制器,不知道罗克韦尔为什么要开发“蜘蛛”QUIP,也不知道半个世纪以来维护不善的系统往往会失败。然而,有些藏家消息灵通。例如:“在电子方面- System 1使用的是70年代中期的技术。所有的电子元件都是现成的元件,没有定制元件。事实上,罗克韦尔公司使用的是他们自己的部件——谁能责怪他们呢?我认为它只有两个缺点-糟糕的接地技术和边缘连接器。“至于他们的CPU不受欢迎——它们在相当长一段时间内在销售点终端非常受欢迎。但当MOS科技推出价格实惠的6502系列处理器时,他们的4位处理器就被淘汰了。”罗克韦尔微电子和PPS-4产品线也已经从积极参与电子工业的人们的集体记忆中消失了,而且在网上很难找到PPS-4的历史。你几乎需要求助于旧书。幸运的是,我书房的书架上有一些这样的书。例如,1981年版的Osborne 4 & 8位微处理器手册列出了罗克韦尔PPS-4/1微控制器家族的10个成员。家族成员有640到2048字节的ROM和48到128个4位的RAM。除了一个家族成员之外,所有成员都有三个集成的串行I/O端口,实际上无非是串行的4位移位寄存器。MM76C是一个家族成员,具有高速上行/下行定时器/计数器子系统,可以作为一个16位计数器或两个8位计数器操作。该计数器还可以处理光学编码器使用的正交编码输入。计时器/计数器子系统为罗克韦尔PPS-4/1微控制器开辟了额外的工业应用领域,包括电机控制、频率计数、模数转换和频率合成。如果你不熟悉NRMEC、罗克韦尔微电子或罗克韦尔半导体,那可能是因为该公司在1999年被分拆为Conexant Systems,这是全球范围内将内部持有的半导体公司的价值推向股市的努力的一部分。Conexant在2002年将其晶圆厂(原罗克韦尔的晶圆厂)拆分为Jazz Semiconductor,从此走向无晶圆厂化。Tower Semiconductor于2008年收购了Jazz Semiconductor,并成为了TowerJazz。该公司在2020年恢复了Tower Semiconductor的名称,现在英特尔正在收购该公司。与此同时,罗克韦尔早期的MOS/LSI工艺已经一去不复返,而且大多已被遗忘。
企业动态
2022.12.05
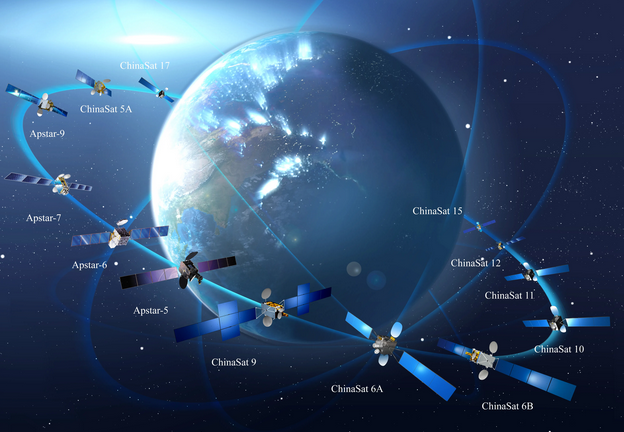
关于卫星互联网的最强入门科普
最近十年以来,整个社会对卫星通信的关注度不断提升,各种新闻报道层出不穷。究其原因,有两个方面。一,来自市场和用户对卫星通信的旺盛需求;二,卫星通信技术发生演进,让以前不可能的事情,变成了可能。今天这篇文章,我们就详细了解一下,卫星互联网的那些事儿。█ 卫星通信的技术演进上世纪70-80年代,卫星通信刚刚诞生的时候,主要用于电视和广播信号转播,还有一些电话、电报和传真需求。那时候,国际互联网(Internet)都还没有成型,所以,也没有什么卫星上网的概念。80年代末90年代初,美国摩托罗拉开始搞铱星计划,就是卫星电话为主,业务速率仅有2.4Kbps(铱星一代)。这种速率,根本谈不上什么用户体验,能听清楚对方说话就不错了。铱星一代和二代的速率参数对比我们国家卫星通信起步较晚。如前篇文章所说,1984年,我们才发射了第一颗有实用价值的通信卫星(东方红2号)。1986年,我们建成了第一张卫星公用传输网(主要基于国外购买的设备)。最早的时候,卫星通信所使用的技术,以SCPC(单路单载波)、FDM/FM(频分复用/频率调制)为主,都是模拟通信技术。随着80年代国内程控电话业务大爆发,加上90年代初国内开始接触互联网,行业专家们发现:当时卫星通信采用的模拟技术,没办法适应地面公共通信网络的数字通信技术升级,落伍了。于是,卫星通信,开始转向了IDR(中速数据速率)技术。IDR业务是由Intelsat在1980年代中期提供的一种新型数据通信业务。相对于传统的FDM/FM,IDR是一种数字制式升级,属于TDM/FDMA(时分复用/频分多址)体制。IDR有1.544、2.048、6.312和8.448Mbps四种信息速率。它与DCME(数字电路倍增设备)组合使用,可将卫星专线传输能力提高到原来的5倍。例如,8.448Mbps电路可传600路话音。1993年5月,原邮电部引进加拿大Spar公司的IDR设备,对国内各地的卫星地面站进行升级和新建。尽管IDR实现了数字信号升级,也提升了带宽,但对于日益增长的用户需求来说,还是杯水车薪。于是,一种新型技术开始崛起并迅速普及,那就是大名鼎鼎的VSAT。VSAT,全名叫做Very Small Aperture Terminal,甚小孔径终端。请注意,VSAT通常是指系统,并不仅仅是一个终端。一套完整的VSAT系统,由通信卫星上的转发器、地面大口径主站(中枢站)以及众多小口径的小站共同构成。VSAT的基本架构VSAT解决的是卫星通信“平民化”的问题。首先是地面站的小型化。所谓的“甚小孔径”,到底有多小?0.3-2.4米。这就很轻便了,一个人都能背着到处走。稍微大一点的,也可以车载,开着车到处走。除了轻便之外,VSAT还有组网灵活、成本低、应用多、安装操作简单等特点,非常有利于卫星通信的普及。1984年,Intelsat首次开设了VSAT业务。我国很快跟进,1988年,原中国通信广播卫星公司引进国外通信设备,建成我国第一个VSAT通信网。它包括1个主站和35个端站,为我国铁道部、能源部、地震局、海洋局、民航局、海关总署、经济信息中心和农业bank等8个行业部门提供通信服务。后来,我们国家建设无线寻呼网、证券信息广播、村村通/户户通工程,都大量采用了VSAT。还有很多远洋船用通信、飞机通信、企业和政府专网,也采用了VSAT。2008年汶川地震之后,电信运营商为了应对自然灾害,引进了大量的VSAT设备,作为地面光纤网络的备份,以及应急通信的工具。█ 高通量通信卫星进入21世纪后,Internet互联网继续蓬勃发展。无处不在的网络连接需求,刺激了卫星互联网的能力演进。卫星通信星想要发展,就必须像地面蜂窝移动通信网络一样,进行带宽容量升级。很多读者听说过三种轨道:GEO(地球同步轨道)、MEO(中地球轨道)、LEO(低地球轨道)。通信卫星主要在前三个轨道以前,发射卫星的成本极高。所以,就希望一颗卫星能覆盖很大的范围。想要覆盖范围大,就必须把卫星放得更高,也就是GEO高地球轨道。如下图所示,三颗就能覆盖整个地球:高轨道卫星,虽然覆盖面积大,但距离远,通信就更困难。那个时候,通信技术也不是很成熟,所以,无线信道的带宽比较低,通信速率比较慢。后来,卫星通信技术开始逐渐升级,终于开始出现了新一代通信卫星,那就是——高通量通信卫星(HTS,High Throughput Satellite)。所谓“高通量”,是指这种卫星的带宽能力比传统卫星(低通量,1-2Gbps以内)多了几倍甚至几十倍。它是如何做到的呢?首先,使用了更高的频段。传统卫星普遍使用4-8GHz的C波段,频率较低且太过拥挤。而高通量通信卫星,广泛使用Ku波段(12-18GHz)和Ka波段(27-40GHz)。频率资源丰富,带宽也就跟着上去了。其次,卫星平台的升级。就像我们前篇介绍的东3、东4、东5,卫星平台体积越来越大,负载能力越来越强,而且升级了供电技术(电推动加化学推动,混合动力),使得电能上可以保证大带宽所需要的大功耗。第三,转发器数量的增加。这个也是平台负载能力升级带来的好处。信号转发器的数量直线上升,意味着车道增加,带宽也跟着增加。第四,天线波束技术的升级。天线技术提升,尤其是采用点波束,也可以增强信号能力。这相当于把光“聚焦”,不覆盖大面积,集中覆盖小面积,有利于速率提升。2005年8月11日发射的泰国Thaicom 4(又名IPSTAR)通信卫星,号称是世界上第一颗高通量卫星。这颗卫星由美国劳拉公司研制,重约6.5吨,功率14千瓦,是当时世界上最大的商业通信卫星,大到必须要由一枚法国阿丽亚娜5型火箭才能将它送入轨道。Thaicom 4 卫星的总带宽高达45Gbps,可为用户提供上行链接速度4Mbps,下行速度2Mbps的数据服务。我们国家的第一颗高通量卫星,是2017年4月12日发射的中星16(一开始叫实践十三,后来改名中星16)。这颗卫星采用Ka频段多波束宽带通信系统,总容量达20Gbps。中星162019年,我们发射了中星18号,不过失败了。2020年7月9日,我们成功发射了“亚太6D”,这是中国首颗Ku频段高通量宽带卫星,通信总容量达到50Gbps,单波束容量可达1Gbps以上。据悉,我国首颗超百Gbps容量的高通量卫星——中星26号,将于2023年初发射。目前,世界最强的高通量卫星,应该是美国Viasat公司的Viasat-3,据说通量达到Tbps级别,不过发射时间好像一直在延期。█ 低轨通信卫星的崛起除了提升卫星通量之外,行业发现,随着卫星发射成本的逐步下降,我们还有另外一种提升卫星数据传输能力的途径——那就是向中轨和低轨发展。道理很简单:轨道低了,虽然覆盖范围小了,但是我们可以用数量来弥补覆盖。就像蜂窝小区一样,用大量的卫星,密集覆盖。对于卫星互联网,行业一般将其发展分为三个阶段。第一个阶段,是80-90年代,以铱星为代表。当时,卫星通信的自我定位存在问题。他们试图用卫星替代基站,步子迈得太大,很快就纷纷破产失败了。2000年以后,是第二个阶段。这次,他们的想法比较务实,就是打算“吃剩饭”。他们把自己定位为地面通信系统的补充,专门为海上、偏远地区等地方的用户,提供网络服务。虽然看上去比较边缘,但实际上蛋糕也很大。其中最具代表性的企业,是O3b。2007年,格雷格·怀勒(Greg Wyler)创立了O3b Networks卫星公司。他们通过与电信运营商合作,为岛屿或船舶提供宽带卫星通信服务。格雷格·怀勒为了平衡成本和服务体验,O3b Networks选择了中轨道(MEO)来部署卫星。他们运营的卫星星群在赤道上空,距地球约8000公里。这个距离,使得O3b的地面站拥有更高的传输速率,更低的时延。2009年,O3b获得了SES(欧洲卫星公司)、谷歌、汇丰的投资。2013年,O3b经过多年努力,终于拥有了12颗卫星,正式启动服务。很快,他们就实现了盈利目标。后来,2016年8月,SES整体收购了O3b。格雷格·怀勒并没有停止折腾,早在2012年的时候,他就成立了另外一家英国公司,名字叫WorldVU Satellite。后来,这家公司的名字改成OneWeb。除了格雷格·怀勒之外,另一位大佬也看中了互联互联网的潜力,决定入局,那就是大家都熟知的当代“钢铁侠”——埃隆·马斯克(Elon Musk)2014年初,马斯克和格雷格·怀勒曾经共同规划过WorldVu的星座计划。结果,几个月后,他就退出了,决定单干。2015年,他基于自己的太空探索技术公司 (SpaceX),正式提出了星链(Starlink)项目。星链项目最初计划发射4425颗卫星,2018年11月增加7518颗,合计1.2万颗。2019年10月,SpaceX又增加3万颗,总数达4.2万颗。按照马斯克的规划,这些卫星将为全球范围内的客户,提供高速宽带互联网服务。星链的出现,标志着卫星互联网进入了第三个阶段,也就是低轨宽带卫星互联网时代。2020年3月30日,OneWeb申请破产保护。而马斯克的星链这边,目前进展还算顺利。截至2022年9月,SpaceX已经拥有超过2300颗星链卫星在轨运行,激活用户超过50万。OneWeb之所以玩砸了,是因为无法在资本市场募集到足够多的钱。而星链之所以成功,是因为SpaceX拥有可以回收的猎鹰火箭,同时借助一箭多星技术,能够大幅降低了发射成本。(OneWeb不具备卫星发射能力,之前让某国帮忙发射,就出现了对方拒绝发射的问题。马斯克的个人光环,也帮助星链搞到了更多的钱,可以放心烧。)除了星链和OneWeb之外,其实国外还有很多公司在搞低轨星座项目,例如韩国三星的太空互联网项目,亚马逊的Kuiper项目,Telesat的Telesat LEO项目等。█ 国内的卫星互联网项目进展国外低轨卫星互联网项目搞得风生水起,我们自然也不能缺席。众所周知,我们国家通信基础设施非常强大,光纤、移动通信覆盖广泛,速率和带宽全球领先,能够满足绝大部分用户的需求。但是,我们仍然需要发展卫星通信。因为它非常、非常、非常重要。首先,我们国家幅员辽阔,很多偏远地区还是存在覆盖盲区。运营商所说的网络覆盖率达到99%,指的是“人口覆盖率”。而“国土覆盖率”,仅有30%左右。也就是说,大量的深山、沙漠、戈壁无人区等地区,是没有手机信号的。对于资源勘探、森林防火、抢险救灾、探险旅游、野生动物保护等用途,卫星是重要的通信手段,也是救命手段。这几年很火的物联网,也开始有卫星方面的需求,主要用于资产管理、地质灾害监测等。除了陆地之外,卫星通信的两个重要应用领域,就是船用通信和机载通信(飞机通信)。这些需求数量是极为庞大的,而且,都是高价值客户,愿意掏钱。如果没有自己的卫星互联网,我们不仅要把市场份额拱手让人,还可能在特殊情况下,受制于人。2008年汶川地震,我们使用的就是国外的卫星电话。结果,莫名其妙还中断服务了十多个小时。自那之后,国内就开始发力搞自己的卫星互联网系统。除了上述原因之外,我们要搞卫星互联网,尤其是低轨LEO卫星,还有资源抢占的因素。根据赛迪顾问研究报告数据,地球近地轨道可容纳约6万颗卫星。据预测,到2029年,地球近地轨道将部署总计5.7万颗低轨卫星。所以,再不抢,空间轨道资源就没了。除了空间轨道资源,我们还要抢频段资源。空间通信频段这个东西,国际原则是“要打先申请、先申请先用”。低轨卫星的主要通信频段(Ku 和 Ka)逐渐趋于饱和,这也是要赶紧下手的。接下来,我们看看,国内在低轨卫星互联网方面的进展。首先看国家队。2020年4月20日,国家发改委首次将卫星互联网和5G、工业互联网等一起,列入信息基础设施,明确了建设卫星互联网的重大战略意义。2021年4月26日,中国卫星网络集团有限公司(星网集团)在雄安新区注册成立。行业普遍认为,这个新成立的大型央企,将会重新整合资源,致力于建设一个更加庞大的低轨卫星移动通信与空间互联网系统。国内民营企业这边,也有所行动。2020年1月16日11时02分,民营公司银河航天成功发射了首颗低轨宽带通信卫星。执行本次发射任务的火箭,是快舟一号甲运载火箭。该卫星是全球首颗Q/V频段的低轨宽带卫星。卫星升空运行后,可提供10Gbps带宽通讯能力,覆盖30万平方公里,相当于大约50个上海市的面积。除了低轨,我们也没有放弃高轨和中轨。前几篇里提到了中国卫通。2018年3月,工信部向中国卫通颁发了基础电信业务经营许可,批准中国卫通在全国范围内经营卫星移动通信业务和卫星固定通信业务。这意味着,中国卫通成了“第五大运营商”。这一变化,和国内外卫星互联网的蓬勃发展趋势密不可分。除了前面提到的高通量卫星中星16和26之外,中国卫通在卫星互联网上还有很多积极布局。海洋互联网方面,中国卫通的“海星通”,已经为6000艘中国船舶和海上平台提供了服务,覆盖了全球95%以上的航线。海星通航空互联网方面,中国卫通也于2020年成立了星航互联,完成国产Ka宽带飞机商用首飞。目前,中国卫通在沿着国际主要航线,不断扩大自己的覆盖范围。另外一家在高轨和中轨布局的,是中国电信。 2008年,中国电信把中国卫通给了航天科技集团之后,并没有放弃对卫星通信的追求。2009年4月21日,中国电信集团有限公司设立卫星通信有限公司。2017年12月15日,中国电信股份有限公司设立了卫星通信分公司(以下简称中国电信卫星分公司),专门从事卫星通信业务。中国电信自己搞的卫星通信项目,叫做“天通一号”。2016年8月6日,天通一号01星发射升空,是项目的首星。目前,已经发射了3颗,分别是01、02、03星。2018年5月,中国电信的自主卫星电话实现商用放号,号段为1740。天通一号的终端根据规划,天通一号覆盖的范围包括中国全境及领海、中国周边区域、中东、非洲等相关地区,以及太平洋、印度洋大部分海域。天通一号的手机大家在网上都能买到,便宜点的也就5000块一个。 在近几年的重大自然灾害中,天通一号均有不错的表现。最后一个要介绍的是中信卫星。我在前几篇就介绍过,中信集团在1980年代参与组建了亚洲卫星,后来一直是亚洲卫星的股东。为了便于在我国境内合法合规地开展卫星通信业务,根据有关部门的要求,中信集团把亚洲卫星在中国的业务移交给中信网络有限公司,并专门组建了中信卫星(中信网络有限公司北京卫星通信分公司)。中信卫星的卫星数量不多,只有几颗,但也覆盖了亚洲、大洋洲、中东、俄罗斯以及非洲东北部地区,具备较强的卫星通信服务能力。 █ 结语好啦,洋洋洒洒说了那么多,该介绍的都介绍了。正如本文开头所说,全社会对卫星通信的关注度越来越高,手机厂商也开始打卫星通信的主意。也许不久后,我们的手机就能支持直接卫星通信,这也不是完全不可能。未来6G,对卫星通信也有规划布局。不过,主要是集中在空天一体化方面,研究如何让卫星和地面通信系统进行协作,并不是让卫星来取代地面基站。相信随着5G-Advanced的推进,后续会有更多的研究进展公布。总而言之,卫星通信的发展前景广阔。卫星互联网只是一个过程。人类的目标,是建设一个空天一体化的立体全维度网络平台,让通信真正实现无处不在。让我们期待这一天早日到来。快速退火炉,RTA,RTP,合金炉,RTO,快速退火炉RTP,国产快速退火炉,自主研发,快速退火工艺,半导体设备,芯片退火设备,碳化硅退火,氮化镓退火,离子注入退火,晶圆快速退火,硅片快速退火,ast2800,mattson,allwin21,AG退火炉,jetfirst,unitemp,premtek,芯片退火炉,快速退火,台湾退火炉rtp,美国退火炉rtp,快速热处理设备rtp,离子注入后快速退火,mattson ast,ast2700,ast3000,ast2900,sic高温退火设备,屹唐退火炉,ultech rtp,ag8108,ag610,ag4100,amat rtp
企业动态
2022.11.01

芯片指令集架构,真的重要吗?
在过去的十年中,ARM CPU厂商多次尝试打入高性能 CPU 市场,因此我们看到大量关于 ARM 努力的文章、视频和讨论也就不足为奇了,其中许多文章关注的是两种指令集架构(ISA)的差异。在本文中,我们将汇集研究、来自非常熟悉 CPU 的人的评论以及我们的一些内部数据,以说明为什么专注于 ISA 是浪费时间,并让我们开始在我们的小冒险中,让我们参考 Anandtech 对 Jim Keller 的采访,Jim Keller 是一位工程师,他曾参与过多种成功的 CPU 设计,包括 AMD 的 Zen 和 Apple 的 A4/A5。“关于指令集的争论是一个非常悲伤的故事。”Jim keller在接受AnandTech采访时说。完整采访请查看文章《Jim Keller:在指令集上辩论是一件悲哀的事情》+ + + + + ✦ ++CISC vs RISC:过时的辩论x86 历史上被归类为 CISC(复杂指令集计算)ISA,而 ARM 被归类为 RISC(精简指令集计算)。最初,CISC 机器旨在执行更少、更复杂的指令,并为每条指令做更多的工作。RISC 使用更简单的指令,执行起来更容易、更快。今天,这种区别已不复存在。用Jim keller的话来说:“RISC 刚问世时,x86 是半微码(half microcode)。所以如果你看一下die,一半的芯片是 ROM,或者可能是三分之一。从事RISC 人可以说 RISC 芯片上没有 ROM,因此我们获得了更高的性能。但是现在ROM太小了,找不到了。其实加法器这么小,你很难找到吗?今天限制计算机性能的是可预测性,两个大的是指令/分支可预测性和数据局部性。”简而言之,就性能而言,RISC/ARM 和 CISC/x86 之间没有有意义的区别。重要的是保持内核的供给,并提供正确的数据,这些数据专注于缓存设计、分支预测、预取以及各种很酷的技巧,比如预测加载是否可以在存储到未知地址之前执行。在2013 年,Blem 等研究人员发现了一种方法。研究了 ISA 对各种 x86 和 ARM CPU [1]的影响,发现 RISC/ARM 和 CISC/x86 在很大程度上已经收敛。来自威斯康星大学论文的表格,显示了 RISC/ARM 和 CISC/x86 之间的收敛趋势Blem等人得出的结论是,ARM 和 x86 CPU 在功耗和性能方面存在差异,主要是因为它们针对不同的目标进行了优化。指令集在这里并不重要,重要的是实现指令集的 CPU 的设计:他们研究的主要发现是:尽管平均周期计数差距 指令计数和混合与一阶 ISA 无关。性能差异是由独立于 ISA 的微架构差异产生的。能耗再次与 ISA 无关。ISA 差异具有实施意义,但现代微架构技术使它们没有实际意义;一个 ISA 从根本上说并不是更有效。ARM 和 x86 实现只是针对不同性能级别优化的设计点以上观点来自论文《Power Struggles: Revisiting the RISC vs. CISC Debate on Contemporary ARM and x86 Architectures》换句话说,ARM ISA 与低功耗没有任何关系。同样,x86 ISA 与高性能无关。我们今天熟悉的基于 ARM 的 CPU 恰好是低功耗的,因为 ARM CPU 的制造商将他们的设计定位于手机和平板电脑。英特尔和 AMD 的 x86 CPU 以更高的性能为目标,具有更高的功率。为了给 ISA 发挥重要作用的想法泼冷水,英特尔以基于 x86 的 Atom 内核为目标。Federal University of Rio Grande do Sul [6] 进行的一项研究得出结论:“对于所有测试用例,基于 Atom 的集群被证明是在低功耗处理器上使用多级并行性的最佳选择。”正在测试的两种内核设计是 ARM 的 Cortex-A9 和英特尔的 Bonnell 内核。有趣的是,Bonnell 是一种有序设计,而 Cortex-A9 是一种无序设计,应该为 Cortex-A9 带来性能和能源效率的胜利,但在研究中使用的测试中,Bonnell 出现了在这两个类别中都领先。✦ ++解码器差异:杯水车薪另一个经常重复的真理是 x86 有一个显著的“ecode tax”障碍。ARM 使用固定长度的指令,而 x86 的指令长度不同。因为您必须在知道下一条指令从哪里开始之前确定一条指令的长度,所以并行解码 x86 指令更加困难。这对于 x86 来说是一个缺点,但对于高性能 CPU 来说,这并不重要,用 Jim Keller 的话来说:“有一段时间我们认为可变长度指令真的很难解码。但我们一直在想办法做到这一点。.所以当你在建造小型电脑时,固定长度的指令看起来真的很好,但如果你正在建造一台非常大的电脑,预测或找出所有指令的位置,它并没有支配die。所以没那么重要。”我们深入并亲自对此进行了检查。通过未记录的 MSR 禁用 op 缓存后,我们发现 Zen 2 的 fetch 和 decode 路径比 op cache 路径消耗大约 4-10% 的核心功率,或 0.5-6% 的封装功率。在实践中,解码器将消耗更少的核心或封装功率。Zen 2 并非设计为在禁用微操作缓存的情况下运行,并且我们使用的基准 (CPU-Z) 适合 L1 缓存,这意味着它不会对内存层次结构的其他部分造成压力。对于其他工作负载,来自 L2 和 L3 高速缓存以及内存控制器的功耗将使解码器的功耗变得不那么重要。事实上,在禁用 op 缓存的情况下,一些工作负载的功耗降低了。解码器的功耗被其他核心组件的功耗所淹没,特别是如果操作缓存让它们得到更好的馈送。这与Jim Keller的评论一致。研究人员也同意这个观点。2016 年,Helsinki Institute of Physics[2]支持的一项研究着眼于英特尔的 Haswell 微架构。在那里,Hiriki 等人估计,Haswell 的解码器消耗了 3-10% 的封装功率。该研究得出的结论是,“x86-64 指令集并不是生产节能处理器架构的主要障碍。”Hiriki 等人使用综合基准开发模型来估计单个 CPU 组件的功耗,并得出结论认为解码器功耗很小在另一项研究中,Oboril 等人 [5] 在 Intel Ivy Bridge CPU 上测量获取和解码能力。虽然那篇论文专注于为核心组件开发一个准确的功率模型,并没有直接得出关于 x86 的结论,但它的数据再次表明解码器的功率是沧海一粟。Oboril 等人对 Ivy Bridge 功耗的估计。与其他核心组件相比,Fetch+Decode 的能力微不足道但显然解码器功率不是零,这意味着它是一个潜在改进的领域。毕竟,当您受到功率限制时,每一瓦特都很重要。即使在台式机上,多线程性能也常常受到功率的限制。我们已经看到 x86 CPU 架构师使用 op 缓存来提供每瓦性能,所以让我们从 ARM 方面看一下。✦ ++ARM 解码也很贵Hirki 等人还得出结论:“切换到不同的指令集只会节省少量功率,因为在现代处理器中无法消除指令解码器。”ARM Ltd 自己的设计就是证明。高性能 ARM 芯片采用微操作缓存来跳过指令解码,就像 x86 CPU 一样。2019 年,Cortex-A77 引入了 1.5k 条目操作缓存[3]。设计运算缓存并非易事——ARM 的团队在至少六个月的时间里调试了他们的运算缓存设计。显然,ARM 解码的难度足以证明花费大量工程资源尽可能跳过解码是合理的。Cortex-A78、A710、X1 和 X2 还具有运算缓存,表明该方法在蛮力解码方面取得了成功。三星还在其 M5 上引入了运算缓存。在一篇详细介绍三星 Exynos CPU [4]的论文中,解码能力被称为实现操作缓存的动机:“随着设计从 M1 中的每个周期提供 4 条指令/微指令变为 M3 中的每个周期 6 条(未来的目标是增长到每个周期 8 条),获取和解码能力是一个重要的问题。M5 实现添加了一个微操作缓存作为替代 uop 供应路径,主要是为了节省可重复内核的获取和解码能力。”——《Evolution of the Samsung Exynos CPU Microarchitecture》就像 x86 CPU 一样,ARM 内核使用 op 缓存来降低解码成本。ARM 的“解码优势”并不足以让 ARM 避免操作缓存。并且操作缓存将减少解码器的使用,使解码功率变得更不重要。✦ ++ARM指令解码成微操作?Gary Explains 在标题为“ RISC vs CISC– Is it Still a Thing ? “,他在随后的视频中重复了这一说法。Gary 是不正确的,因为现代 ARM CPU 还将 ARM 指令解码为多个微操作。事实上,“减少微操作扩展”使 ThunderX3 的性能比 ThunderX2 提高了 6%(Marvell 的 ThunderX 芯片都是基于 ARM 的),这比故障中的任何其他原因都要多。Marvell 在 Hot Chips 2020 上展示的幻灯片。重点(红色轮廓)由我们添加我们还快速浏览了富士通 A64FX 的架构手册,这是为日本 Fugaku 超级计算机提供动力的基于 ARM 的 CPU。A64FX 还将 ARM 指令解码为多个微操作。A64FX 架构手册中的部分指令表,位于 ARMv8 基本指令部分。我们在解码到多个微操作的指令上添加的重点(红色轮廓)如果我们深入看,一些 ARM SVE 指令会解码为数十个微操作。例如,FADDA(“浮点加法严格有序归约,以标量累加”)解码为 63 个微操作。其中一些微操作单独具有 9 个周期的延迟。对于在单个周期中执行的 ARM/RISC 指令来说,就这么多了……另外需要注意的是,ARM 并不是一个纯粹的加载存储架构。例如,LDADD 指令从内存中加载一个值,添加到它,然后将结果存储回内存。A64FX 将其解码为 4 个微操作。✦ ++x86 和 ARM:都因遗留问题而臃肿这对他们中的任何一个都没有关系。在 Anandtech 的采访中,Jim Keller 指出,随着软件需求的发展,x86 和 ARM 都随着时间的推移增加了功能。当它们进入 64 位时,两者都得到了一些清理,但仍然是经过多年迭代的旧指令集,迭代不可避免地会带来臃肿。Keller 好奇地指出,RISC-V 没有任何历史遗留文呢提,因为它“处于复杂性生命周期的早期”。他继续:“如果我今天想真正快速地构建一台计算机,并且我希望它能够快速运行,那么 RISC-V 是最容易选择的。它是最简单的一个,它具有所有正确的功能,它具有您实际需要优化的正确的前八条指令,而且它没有太多的垃圾。”如果遗留膨胀起重要作用,我们可以期待很快会出现 RISC-V 的猛攻,但我认为这不太可能。旧版支持并不意味着旧版支持必须快速;它可以进行微编码,从而最大限度地减少芯片面积的使用。就像可变长度指令解码一样,这种开销在现代高性能 CPU 中不太重要,因为芯片区域由缓存、宽执行单元、大型乱序调度程序和大型分支预测器主导。✦ ++结论:实施很重要,而不是ISA我很高兴看到来自 ARM 的竞争,因为高端 CPU 空间需要更多玩家,但由于指令集差异,ARM 玩家并没有超越 Intel 和 AMD。要赢得胜利,ARM 制造商将不得不依靠其设计团队的技能。或者,他们可以通过针对特定的功率和性能目标进行优化来超越英特尔和 AMD。AMD 在这里尤其容易受到攻击,因为它们使用单核设计来涵盖从笔记本电脑和台式机到服务器和超级计算机的所有内容。希望这里提供的信息能够避免过去关于指令集的争论,这样我们就可以继续讨论更有趣的话题。
企业动态
2022.10.12

一文看懂TSV
在2000年的第一个月,Santa Clara University的Sergey Savastiou教授在Solid State Technology期刊上发表了一篇名叫《Moore’s Law – the Z dimension》的文章。这篇文章最后一章的标题是Through-Silicon Vias,这是 Through-Silicon Via 这个名词首次在世界上亮相。这篇文章发表的时间点似乎也预示着在新的千禧年里,TSV注定将迎来它不凡的表演。TSV示意图TSV,是英文Through-Silicon Via的缩写,即是穿过硅基板的垂直电互连。如果说Wire bonding(引线键合)和Flip-Chip(倒装焊)的Bumping(凸点)提供了芯片对外部的电互连,RDL(再布线)提供了芯片内部水平方向的电互连,那么TSV则提供了硅片内部垂直方向的电互连。 作为唯一的垂直电互连技术,TSV是半导体先进封装最核心的技术之一。与集成电路一起诞生的垂直互联1958年的秋天,肖特基(William Shockley)坐在办公室思考着如何设计晶体管可以实现高频的应用。早在1947年,他便与巴丁、布拉顿一起研制出了第一个晶体管,并在1956年一起获得了诺贝尔奖。“为什么不能在晶圆上打些孔?” Shockley喃喃自语。不久Shockley申请了一项专利 -(SEMICONDUCTIVE WAFER AND METHOD OF MAKING THE SAME),这是历史上第一项在晶圆上刻蚀通孔的专利。虽然这项专利的初衷是只为了晶体管在在高频率领域的应用,但在这项专利中,肖老也提到了如果需要可以在通孔中填充导电金属。就这样,发明晶体管的人也成了第一个想到在晶圆做导电孔的人。同一年还发生一件大事,将多个晶体管制造在一起的集成电路(芯片)也被发明出来了。肖特基的硅片上制作孔专利此后, IBM开始在集成电路领域发力,并在垂直电互连方面取得了突破。6年之后的1964年,IBM申请了一项专利(METHODS OF MAKING THRU- CONNECTIONS IN SEMICONDUCFOR WAFERS),提出了利用在通孔中做简并掺杂降低电阻的方式实现硅片的垂直互连,即用低阻硅为导电材料。但是这项专利还只是停留在硅片自身上下表面器件的,并没有用于多芯片的堆叠。直到5年后的1969年,IBM才在另一项专利 (HOURGLASS-SHAPED CONDUCTIVE CONNECTIONTHROUGH SEMCONDUCTOR STRUCTURES) 中首次提出了基于垂直互连的多层芯片的堆叠,如下图:第一个芯片堆叠专利似乎只用了11年,甚至在TSV这个名词被正式发明前,垂直互连的概念和工艺都已经发展好了。只是IBM的这项专利并没有得到大规模的应用。原因在于这个专利中导通孔的形状,如其专利名字 “HourGlass” 所示,是沙漏形的,它占用太多的面积。这种形状的通孔涉及到2年前(1967年)Bell Telephone Laboratories的H.A. Waggener的一项发现:KOH对于单晶硅的不同晶面的腐蚀速率有巨大的差异【1】。例如对晶面的腐蚀率要比晶面大几百倍。利用这个特点可以在常用的硅晶圆很方便的刻蚀的通孔,但是孔形是倒金字塔形状的(或者说是沙漏形的)。随着摩尔定律的不断发展,单位面积上晶体管越来越密集,这种占用大量表面积的垂直互连显然失去了其存在的意义。KOH刻蚀示意图但或许是受IBM提出的这个堆叠芯片概念的影响,三维集成芯片这个理念在半导体行业像星星之火燎原一样传播开来。此后共计有40多家研究机构和公司参与了相关技术的研究【2】,而 作为三维堆叠芯片中最核心的垂直电互连技术 自然也倍受关注。在接下来的70到90年代,半导体微加工技术的多项突破将为现代TSV的诞生打下坚实的基础。技术的突破硅作为一种半导体材料,既没有很好的导电性也没有很好的绝缘性。 要在硅片上实现垂直的电互连,一般需要在上面制作微孔 (取决于具体的应用,一般孔径在几个微米到几百微米,头发丝约为50微米,而且单片硅片上需要的孔数量可达数十万);在孔的侧壁沉积绝缘材料;在微孔中填充导电材料等制造步骤。其中最具挑战的是微孔的批量刻蚀和导电化。 首先,在硅晶圆上加工微孔不是件容易的事。硅硬度大且脆,而需要加工的孔径小且量大,用传统的机械加工方式根本不可行。在1958年肖特基的专利中,他提出了用晶料界面的化学腐蚀速率的差异来实现微孔的刻蚀 (因为历史久远加上缺少足够资料,未能完全理解肖老的这种腐蚀方法*_*)。反向溅射(即等离子物理轰击刻蚀)也曾被尝试做刻蚀,但是速率太慢,于是人们不得不又回到化学腐蚀的老路上。上文提到的KOH刻蚀是化学腐蚀的一种,属于各向异性腐蚀,只是无法实现最合适TSV的圆柱孔。80年开始,日本开始在三维集成方面发力,成立了“Three-Dimensional Circuit Element R&D Project”。1983年和1984年Hitachi的两项专利中都提到了用激光打孔的方式来解决硅片上微孔刻蚀的问题【3】。不同于KOH刻蚀的“沙漏孔”,这些专利都使用了圆柱孔。但是激光加工也存在不少问题,一方面孔只能一个个加工比较耗时,另外加工的孔存在表面粗糙以及崩边等问题。 直到90年代,硅刻蚀才迎来了突破,DRIE深硅刻蚀技术横空出世。DRIE,Deep Reactive Ion Etching的首字母缩写。这项技术是1994年德国Robert Bosch公司在此前一项低温离子硅刻蚀技术的基础上发展的一项高深宽比硅刻蚀技术【4】。这项技术用了一种很巧妙的方法实现了 各向同性腐蚀来刻蚀圆柱孔。各向同性腐蚀与上面讲的KOH这种各向异性腐蚀不同,它在腐蚀硅片时各个方向是均匀的,所以正常情况下它只能在硅片上刻蚀出球状的孔。使各向同性腐蚀实现圆柱孔刻蚀的核心思想是将腐蚀分割成无数的小步。它的具体方法是:先在硅片把需要刻蚀微孔的位置的硅裸露出来,用各向同性的腐蚀气体在硅片上刻蚀下去一薄层,然后在刻蚀出来的坑的表面沉积保护层,再用等离子打掉坑底的保护层打掉,再用各向同性的腐蚀气体刻蚀一薄层,通过这样多次微小的各向同性腐蚀循环就可以在硅片上实现批量的高深宽比微孔的刻蚀。事实上这项技术如此重要,后来也成为MEMS的核心制造技术。DRIE的示意图微孔的导电化也同样富有挑战。在1958年肖老的专利中只是提及在孔中填充金属的想法,但并未提供任何具体的实施方法;1964年IBM的专利中是利用简并掺杂来降低硅的电阻从而将硅自身转化导电介质,这种方法无法用于微孔的导电化;而在1969年IBM申请的专利中,金属层是通过溅射的方式实现的。虽然溅射在当时是半导体主流的金属沉积方法,但是溅射一般只能用于厚度在1um以下的薄金属沉积,并且包覆性差,只能用于沙漏形孔的金属化。 1970年,Hitachi公司在一个专利中首次提出将用电镀在半导体晶圆中实现金属沉积【5】,虽然这个专利中电镀只是为了实现金属与硅的欧姆接触,但这项研究开启了电镀用于半导体加工的序幕。电镀技术是19世界上半叶由英国和俄罗斯的科学发明的一种全新的金属成形技术,与以前人类所有的纯物理金属加工方式,例如锻造,铸造,蒸发沉积,溅射沉积,机加工等都不同, 电镀是一种电化学技术。这项技术一开始主要被用于金属艺术品的批量制造。因其沉积速度相对较快并且可以实现批量的沉积这个特点,电镀这项技术在被发明100多年后,终于与半导体走到了一起。5年后的1975年,IBM进一步将X射线光刻与电镀结合,开始探索电镀用于晶圆厚金属的沉积【6】。1982年,这项技术在德国被进一步发展成一项重要的 MEMS技术LIGA。全称叫Lithographie, Galvanoformung, Abformung (英语:Lithography, Electroplating, and Molding) 【7】。这是一项结合光刻和电镀的用于高深宽比金属结构沉积的技术。作为MEMS(微电子机械)的核心技术,LIGA为MEMS早期的发展立下不少功劳。如果对上文还有印象的话,DRIE深硅刻蚀后来也成为MEMS的核心技术。所以说TSV和MEMS在技术是孪生兄弟一点都不为过!90年代中期,半导体行业发生一件大事: IBM用铜电镀大马士革工艺全面替代的溅射铝作为集成电路中晶体管互连。这样电镀铜在半导体行业便开始成为标准工艺,这让电镀铜用于TSV的微孔金属化填充更加顺理成章。至此, 现代TSV的两项核心技术:深硅刻蚀和电镀都出现了。 走向商用TSV不仅赋予了芯片纵向维度的集成能力,而且它具有最短的电传输路径以及优异的抗干扰性能。随着摩尔定律慢慢走到尽头,半导体器件的微型化也越来越依赖于集成TSV的先进封装。TSV对于像CMOS Image Sensor(CIS,CMOS图像传感器),High Bandwidth Memory(HBM)以及Silicon interposer(硅转接板)都极其重要。因为存在感光面的缘故,CIS芯片的电信号必须从背部引出,TSV因此成为其必不可少的电互连结构。HBM是基于多层堆叠的存储芯片,如今HBM已经可以实现12层的堆叠,16层以上更多层的堆叠相信在不久的将来也会实现,当然这一切都离不开TSV的互连。而Silicon interposer可以将多种芯片,像CPU, memory, ASIC等集成到一个封装模块的关键组件,它的垂直互连同样需要TSV。事实上,法国的Yole development咨询公司曾做过一项研究发现TSV几乎可以应用于任何芯片的封装以及任何类型的先进封装,包括LED, MEMS等。正是因为TSV的重要性,各大Foundry和OSTA公司也不断投入TSV技术的研发。这阶段的研发重点是如何保证电镀沉积主要发生在TSV孔内而不是硅片表面。如果不采取任何措施,电镀时硅表面金属沉积的速度会远快于TSV孔内。这个问题目前的解决方法是在电镀液中添加抑制剂和加速剂,分别抑制硅片表面的金属沉积并加速TSV孔内的沉积。为了获得完美的填充效果和足够高的良率,各大Foundry和OSTA公司都做了大量研究以获得最佳的电镀的参数,例如电流,温度,硅片的与电极的相对位置,添加剂的浓度等。各大半导体设备公司也开始针对TSV的电镀推出专用的半导体设备。21世纪,基于深硅刻蚀和铜电镀工艺的TSV技术日渐成熟,并开始正式走向商用。 1999年和2000年,日本分别率先研发出第一款三层堆叠的图像传感器和三层堆叠的存储器件。2004年,出于对TSV未来应用前景的看好,TSV名词的提出者Sergey Savastiou教授成立了ALLVIA的公司专注于TSV代工制造。2005年,10层堆叠的存储芯片被研制出来。2007年集成TSV的CIS芯片由Toshiba公司量产商用,同年ST Microelectronics和Toshiba一起推出8层堆叠的NAND闪存芯片。2013年第一款HBM存储芯片由韩国Hynix推出。2015年,第一款集成HBM的GPU由AMD推出。不走寻常路的Sil - Via随着TSV在CIS和HBM中的大规模应用,似乎TSV技术已经成熟并没有太多可以创新的空间了。但是无论是CIS还是HBM,其中用到的TSV都是孔径只有10微米左右的小孔径TSV, 而基于电镀的TSV却一直没能攻下最后一个阵地:大孔径TSV的实心填充。对于大孔径例如直径50微米以上甚至100多微米的微孔,如果用电镀填充满需要几个小时,不仅成本非常高而且良率也难以保证。 对于大孔径TSV,瑞典有家MEMS公司却走出了另外一条“特色”技术路线。这家叫 Silex的公司不走寻常路, 独立开发出了一项基于低阻硅的Sil-Via的TSV技术。Sil-Via与电镀TSV有两大不同:首先,它用的硅基板材料本身就是低阻硅,类似于1964年IBM专利中的简并掺杂硅。其次,在制造过程中,Sil-Via刻蚀的不是孔而是环槽,通过在环槽是填充绝缘材料的方式实现中心低阻硅圆柱作为导电介质。Sil-Via主要用于MEMS器件的封装中,正是因为Sil-Via的巨大成功,Silex也成为世界最大的MEMS代工厂。2015年7月,中国资本收购了Silex,只是Sil-Via这项技术的核心,在几十微米的圆槽中饱满填充可以耐800度以上温度的绝缘材料,仍然被瑞典人所掌握着。但Sil-Via并不完美,低阻硅只能满足MEMS器件的导电要求,金属化的大孔径TSV孔依旧有着很大的需求,而这又涉及到一条新的技术路线,以后专门写一篇细说。Sil-Via(from silex website )结 语2022年3月9号,苹果公司推出的M1 ULTRA处理器,这款性能爆表的处理器中,多个CPU使用带TSV的Silicon interposer进行集成的。如今,无论是AI/AR/VR中用到的传感器,图像传感器,堆叠存储芯片以及高性能处理器,都越来越离不开TSV。TSV, 这项并不为人熟知的技术,正在硬件的底层深深的影响着人类的生产生活方式。半个多世纪前的那个秋天,肖特基那个在硅片上打孔的想法最终将人类带入了人工智能的时代。【1】Anisotropic Etching for Forming Isolation Slots in Silicon Beam-Leaded Integrated Circuits, H.A. Waggener, IEEE TRANSACTION OF ELECTRON DEVICES, JUNE 1968.【3】JP S59 22954 & JP S63 156348【5】 METHOD OF MANUFACTURING SEMCONDUCTOR DEVICES, Patent No. 3,661,727.【7】E.W.Becker, W.Ehrfeld, D.Munchmeyer, H.Betz, A.Heuberger, S.Pongratz, W.Glashauser, H.J.Micheland V.R.Siemens, “Production of Separate Nozzle Systems for Uranium Enrichment by a Combination of X-ray Lithograohy and Galvanoplastics,” Naturwissenschaften,vol.69,pp.520-523,1982.
参数原理
2022.09.01

快速退火炉RTP设备的介绍
简介:快速退火炉是利用卤素红外灯做为热源,通过极快的升温速率,将晶圆或者材料在极短的时间内加热到300℃-1200℃,从而消除晶圆或者材料内部的一些缺陷,改善产品性能。快速退火炉采用先进的微电脑控制系统,采用PID闭环控制温度,可以达到极高的控温精度和温度均匀性,并且可配置真空腔体,也可根据用户工艺需求配置多路气体。行业背景:快速退火炉是现代大规模集成电路生产工艺过程中的关键设备。随着集成电路技术飞速发展,开展快速退火炉系统的创新研发对国内开发和研究具有自主知识产权的快速退火炉设备具有十分重大的战略意义和应用价值。目前快速退火炉的供应商主要集中在欧、美和台湾地区,大陆地区还没有可替代产品,市场都由进口设备主导,设备国产化亟待新的创新和突破。随着近两年中美贸易战的影响,国家越来越重视科技的创新发展与内需增长,政府出台了很多相关的产业政策,对于国产快速退火炉设备在相关行业产线上的占比提出了一定要求,给国内的半导体设备厂商带来了巨大机遇,预测未来几年时间国内退火炉设备市场会有快速的内需增长需求。技术特点:快速退火炉(芯片热处理设备)广泛应用在IC晶圆、LED晶圆、MEMS、化合物半导体和功率器件等多种芯片产品的生产。和欧姆接触快速合金、离子注入退火、氧化物生长、消除应力和致密化等工艺当中,通过快速热处理以改善晶体结构和光电性能,具有技术指标高、工艺复杂、专用性强的特点。一般参数:名称数值最高温度1200摄氏度升温速率150摄氏度/秒降温速率200摄氏度/分钟(1000摄氏度→300摄氏度)温度精度±0.5摄氏度温控均匀性≤0.5%设定温度加热方式红外卤素灯,顶部加热真空度10mTorr以下工艺应用:快速热处理(RTP),快速退火(RTA),快速热氧化(RTO),快速热氮化(RTN);离子注入/接触退火;金属合金;热氧化处理;高温退火;高温扩散。应用领域:化合物合金(砷化镓、氮化物,碳化硅等);多晶硅退火;太阳能电池片退火;IC晶圆;功率器件;MEMS;LED晶圆。设备说明:快速退火炉主要由真空腔室、加热室、进气系统、真空系统、温度控制系统、气冷系统、水冷系统等几部分组成。真空腔室:真空腔室是快速退火炉的工作空间,晶圆在这里进行快速热处理。加热室:加热室以多个红外灯管为加热元件,以耐高温合金为框架、高纯石英为主体。进气系统:真空腔室尾部有进气孔,精确控制的进气量用来满足一些特殊工艺的气体需求。真空系统:在真空泵和真空腔室之间装有高真空电磁阀,可以有效确保腔室真空度,同时避免气体倒灌污染腔室内的被处理工件。温度控制系统:温度控制系统由温度传感器、温度控制器、电力调整器、可编程控制器、PC及各种传感器等组成。气冷系统:真空腔室的冷却是通过进气系统向腔室内充入惰性气体,来加速冷却被热处理的工件,满足工艺使用要求。水冷系统:水冷系统主要包括真空腔室、加热室、各部位密封圈的冷却用水。硬件更换:1.加热灯管更换:加热灯管超过使用寿命或无法点亮时需进行更换。加热灯管的使用寿命为3000小时,高温状态下会降低其使用寿命。2.真空泵油更换:在使用过程中,请每季度固定观察1次真空油表,当油表显示油量低于1/3时请添加真空泵润滑油到油表一半以上。3.热电偶更换:当热电偶测温不正常或者损坏时需进行更换。热电偶的正常使用寿命为3个月,随环境因素降低其寿命。4.O型圈的更换:O型圈表面有明显破损或者无法气密时需进行更换,其寿命受外力以及温度因素影响。保养周期:项目检查周期零件或耗材加热灯管周IR灯管托盘表面擦拭周碳化硅材质热电偶固定状态周石英板清理季度O型圈检查更换季度真空泵油季度MR100M导向轴承季度使用润滑油产品推荐:全自动12英寸多腔体快速退火炉RTP设备规格:全自动操作模式,机械手臂自动上片取片;多腔体生产模式,单个腔体适应于 2英寸-12英寸 晶圆或者最大支持 300mmx300mm 样品;退火温度范围 300℃-1300℃;升温速率 ≦100℃/sec(裸片);温度均匀性 ≦±1%;真空腔体(可选配常压腔体或正压腔体);冷却方式包括水冷和氮气吹扫;MFC控制,3-5路制程气体。半自动12英寸快速退火炉RTP设备规格:适应于 2英寸-12英寸 晶圆或者最大支持 300mmx300mm 样品;退火温度范围 300℃-1300℃;升温速率 ≦100℃/sec(裸片);温度均匀性 ≦±1%;真空腔体(可选配常压腔体或正压腔体);冷却方式包括水冷和氮气吹扫;MFC控制,3-5路制程气体。桌上型4英寸快速退火炉RTP设备规格:桌上型小型快速退火炉;适应于 2英寸-4英寸 晶圆或者最大支持 100mmx100mm 样品;退火温度范围 300℃-1200℃;升温速率 ≦100℃/sec(裸片);温度均匀性 ≦±1%;常压腔体(可选配真空腔体);冷却方式包括水冷和氮气吹扫;MFC控制,1-4路制程气体。快速退火炉,RTA,RTP,合金炉,RTO,快速退火炉RTP,国产快速退火炉,自主研发,快速退火工艺,半导体设备,芯片退火设备
参数原理
2022.08.25

英特尔流产的10nm曝光,样品中含3个小芯片
10nm Cannon Lake CPU 是第一个在 10nm 工艺节点上制造的芯片。近日,网上出现了基于Cannon Lake架构的英特尔 CPU 样本,设计为 10nm 芯片的 CPU采用了三芯片设计。或许英特尔将会在其未来的处理器中采用小芯片/混合设计。 英特尔的 10nm Cannon Lake-Y“特殊样品”CPUYuuKi_AnS透露的图片显示,上述 SKU 是仅供内部使用的“特殊样品”系列的一部分。由于该特定芯片从未零售,我们可以假设这些特殊芯片并非用于大众营销,而是用于测试和内部测试目的。根据Angstronomics 的 SkyJuice分析,这里的 CPU 示例图片是一个 3-die MCP(多芯片处理器),采用 BGA1392 封装,尺寸为 28mmx16.5mm。封装上有三个小芯片,10nm CPU 芯片是这三个芯片中最大的,尺寸为 70.5mm2,其次是尺寸为 46.17mm2的 PCH 芯片,最后是尺寸为 13.72mm2的McIVR 芯片。第三个小芯片用作 CPU 的集成稳压器 (IVR),该功能起源于几年前英特尔的Haswell(和Devil's Canyon )第四代 CPU 架构。但由于有额外的芯片,Cannon 的实现被称为多芯片集成稳压器 (McIVR)。McIVR本应处理两个小芯片之间的电压调节,但英特尔此后又选择了 FIVR,并且还在考虑将 DLVR 用于他们的一些下一代设计。IVR 于 2013 年首次在英特尔的第四代 Haswell 架构中首次亮相。IVR 改变了主板和处理器处理电力传输的方式。它将CPU电压调节直接从主板转移到CPU芯片中。英特尔表示,这大大简化了Haswell 平台的供电设计,IVR 能够将主板上的五个稳压器替换为 CPU 内部的一个。这种设计的另一个好处包括对处理器进行更细粒度的电压控制。但最终,处于未知的原因,英特尔在第五代 Broadwell 芯片之后取消了所有主流桌面架构上的 IVR。然而,我们认为它的移除与热问题和芯片尺寸限制有关。尽管如此,IVR 在 Haswell 之后重新出现在其他架构中,包括一些移动架构和英特尔的Skylake-X HEDT 架构。英特尔也计划将 IVR 集成到其 Cannon Lake 移动处理器中,这个原型就是这个想法的证明。但是,IVR 在 Cannon Lake 中的独特之处在于它的多芯片实现。从英特尔的角度来看,这种方法很有意义,可以显着改善芯片的电压余量和温度限制。由于笔记本电脑上的 CPU 散热器比台式机散热器小得多,因此CPU 需要具有尽可能高的热效率。将 IVR 移至单独的芯片即可做到这一点,并将热量分散到不同的区域,从而使 CPU 冷却器能够更有效地处理热传递。以前的 IVR 设计,特别是 Haswell 上的设计,使芯片变得特别热,因为 CPU 冷却器现在必须处理来自稳压器和 CPU 内核、集成显卡和 CPU 缓存组合的热量。英特尔 Cannon Lake-Y 10nm CPU 系列仅发布了两个 SKU,即 Core i3-8121U 和 M3-8114Y。两者都包含 2 个具有 4 个线程的 Palm Cove 内核,但它们仅在少数笔记本电脑和 NUC 中提供。遗憾的是,这种三芯片设计从未上市。10nm Cannon Lake CPU 是第一个在 10nm 工艺节点上制造的芯片,但由于与产量相关的几个问题,当行业发展时,CPU 就进入了市场。因此,英特尔自己尝试在未来几年内迅速用 Ice Lake 和 Tiger Lake CPU 取代这个家族,这意味着 Cannon Lake 的寿命很短。 英特尔的10nm之路英特尔最早公布10nm工艺是在2015年7月。当时,英特尔指出此项工艺存在Multi-patterning缺陷密度高、良率低的问题。而且,10nm(品名:Cannon Lake)的量产时间是在2017年的下半年,相对原计划晚了一年左右。2018年年初,英特尔表示:“Cannon Lake已经开始小规模量产,2018年下半年计划开始量产”。但是,2018年4月,英特尔又公布说:“由于良率较低,10nm工艺CPU的量产推迟到2019年”。后来,2019年量产了第二代10nm工艺(注意,不要与10nm+工艺混淆),与首代10nm工艺技术相比,很多方面都有明显的优势。英特尔本身应该在2015年(首次正式公布10nm的时间)甚至之前就已经了解10nm工艺的优缺点。在充分了解了风险的基础上,英特尔认识到必须要在未来数年内大批量生产与成本、性能、市场投入时间相匹配的CPU。于是,在2016年年初,英特尔新发布了新的基本理念,目的是为了导入新工艺技术、微架构。也就是说,延续了十年的“Tick-Tock模式寿终正寝,新的“PAO(Process-Architecture-Optimization,制程-架构-优化)”开始上场。即,通过长期优化微架构,反复改善工艺技术、产品设计。Brookwood表示,十年来“Tick-Tock”充分发挥了其作用。但是,在14纳米中稍微“跌了个跟头”,导致量产时间延迟一年,而且在10纳米工艺中彻底“崩塌”。另一方面,台积电却保持两年更新一次的步调,虽然台积电的性能提高速度不太快,但性能预测的准确度却极高。实际上,在英特尔还在14纳米“徘徊”的时候,AMD几乎已经将所有系列的产品委托给台积电的7纳米工艺生产。
企业动态
2022.08.23
新型晶体管电介质材料有望实现硅无法做到的事
研究人员开发了一种微小、透明的材料,可用作晶体管中的新型电介质组件。编译来源:newsroom.unsw来自新南威尔士大学悉尼分校的研究人员开发了一种微小,透明和灵活的材料,可用作晶体管中的新型电介质(绝缘体)组件。这种新材料将实现传统硅半导体电子产品无法做到的事情——在不影响其功能的情况下变得更小。这种新材料可以帮助克服纳米级硅半导体生产的挑战,以实现可靠的电容和有效的开关行为。根据研究人员的说法,这是开发新一代未来电子设备的关键瓶颈之一,如增强现实,柔性显示器和新的可穿戴设备,以及许多尚未发现的应用。“它不仅为克服当前硅半导体行业在小型化方面的基本限制铺平了一条关键道路,而且还填补了由于硅的不透明和刚性而在半导体应用中形成的空白,”新南威尔士大学材料与制造期货研究所(MMFI)主任兼该研究的首席研究员Sean Li教授说。“同时,弹性和纤薄的特性可以实现灵活透明的2D电子产品。 解决半导体微缩问题晶体管是一种小型半导体器件,用作电子信号的开关,是集成电路的重要组成部分,从手电筒到助听器再到笔记本电脑,所有电子设备都是通过晶体管与其他组件(如电阻器和电容器)的各种排列和相互作用来实现的。随着时间的推移,晶体管变得越来越小,越来越强大,电子产品也是如此,想想你的手机——一个紧凑的手持式计算机,具有比将第一批宇航员送上月球的计算机更强的处理能力。但是有一个微缩问题。开发更强大的未来电子产品将需要亚纳米厚度的晶体管,这是传统硅半导体无法达到的尺寸。“随着微电子小型化,目前使用的材料由于信号从一个晶体管传递到下一个晶体管的能量损失和耗散而达到极限,”李教授说。微电子器件的尺寸不断减小,以实现更高的速度,当这种微缩发生时,设计参数会受到影响,以至于当前使用的材料由于信号从一个晶体管传递到下一个晶体管时的能量损失和耗散而被推向极限。目前由硅基半导体制成的最小晶体管为3nm。 打破未来电子产品的瓶颈在这项研究中,MMFI工程师使用独立的单晶钛酸锶(STO)膜作为栅极电介质制造了透明场效应晶体管。他们发现他们的新型微型器件与当前硅半导体场效应晶体管的性能相匹配。“这项工作的关键创新是,我们将传统的3D材料转化为准2D形式,而不会降低其性能,”该论文的主要作者Jing-Kai Huang博士说。“这意味着它可以像乐高积木一样,与其它材料自由组装,为各种新兴和未被发现的应用制造高性能晶体管。MMFI学者利用他们多样化的专业知识来完成这项工作。“制造设备涉及来自不同领域的人。通过MMFI,我们与2D电气设备领域以及半导体行业的专家学者建立了联系,“该论文的合著者Ji Zhang博士说。“第一个项目是制造独立的STO并研究其电气特性。随着项目的进展,它演变成使用独立式STO制造2D晶体管。在MMFI建立的平台的帮助下,我们能够共同努力完成该项目。该团队现在正致力于规模生产,换句话说,他们希望看看这种材料是否可以用来在一个芯片上构建整个计算机的所有电路。“收集了大量的数据来支持这些2D电子产品的性能,这表明该技术有望实现大尺寸晶圆生产和工业应用,”该论文的另一位合著者Junjie Shi博士说。“实现这一目标将使我们能够制造出密度更接近商业产品的更复杂的电路,这是使我们的技术惠及人们的关键一步,“黄博士说。目前,该技术受到两项澳大利亚临时专利申请的保护,MMFI和新南威尔士大学希望将知识产权商业化并将其推向市场。“我们目前正在用晶体管制造逻辑电路,”李教授说,“与此同时,我们正在与亚太地区的几个领先机构接洽,以吸引投资,并通过这项技术的工业化在新南威尔士州建立半导体制造能力。快速退火炉,RTA,RTP,合金炉,RTO,快速退火炉RTP,国产快速退火炉,自主研发,快速退火工艺,半导体设备,芯片退火设备
企业动态
2022.08.16
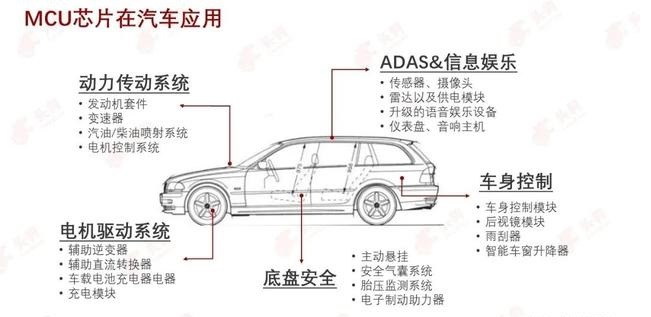
车规级触控MCU,迎来新蓝海
当前,汽车行业正在进行一场变革。电动化,智能化,网联化已成为汽车行业的长期演进趋势,从内燃机到纯电驱动,从分布式架构向集中控制域,汽车正变成继电脑、智能手机之后第三代大型移动智能终端。这一变革将引发一系列产业链连锁反应,带动汽车半导体市场迎来新一波的爆发。IHS Makit数据预测,随着汽车电子需求持续旺盛,预计汽车半导体市场规模将于2030年达到1100亿美元。其中,MCU作为汽车电子控制系统的核心,在车内应用十分广泛,涵盖车身控制、信息娱乐系统、驾驶辅助、动力总成控制等各个领域。在当前汽车“四化”趋势下,车规级MCU迎来了巨大的增量需求。在传统燃油车上,单车MCU用量大约在50-100颗,而智能电动汽车有望实现翻倍甚至更多。据IC Insights预测,2023年全球车规级MCU市场规模将有望增长至88亿美元。其中,汽车智能化的发展推动人机交互方式的革新,车内传统按键向智能按键以及智能表面的转变成为新的发展趋势。例如车钥匙应用中,传统的机械按键替代为压力按键可以实现全防水设计;汽车座舱也开始从传统静态表面快速朝着集成了座椅调节、智能B柱、车内氛围灯及影音娱乐等控制功能于一体的智能表面方向发展。智能触控按键除了提供传统机械按键的功能外,还打造了无实体按键、一体化、防误触的座舱人机交互界面,实现更高级、极简又更人性化的设计需求,提升驾驶员和乘员的用户体验。此外,在结构件的小体积轻量化方面也显示出越来越明显的优势。从目前市场现状来看,汽车中应用压感触控按键只替代了部分机械按键功能,单车替代率还不足25%。车内传统机械按键部分如方向盘、车灯、雨刷、座椅、车窗、空调、娱乐中控、门把手、启动/停车、智能Logo,还有阅读灯/天窗等顶部控制器以及挡位控制、脚踢控制器按键等几十个按键,都正在逐渐由机械开关向智能开关的方向演变。可以预见,未来两三年车载智能触控领域有望迎来爆发式的增长。这一系列应用场景的变革均加大了汽车对智能触控MCU的需求,据相关数据测算,现阶段单车上的触控MCU平均用量大概在4-5颗,未来有望增长到20颗以上,正在催生出一片新蓝海市场。触控MCU的挑战和趋势基于车规级MCU较高的设计门槛和对产品开发能力的高要求,相比通用MCU,目前车规级MCU供应商数量较少。从当前车规级触控MCU市场来看,供应商以英飞凌、Microchip等海外大厂为主,触摸开关大多是基于纯电容方案进行的参考设计。然而,有业内人士向笔者表示,从实际应用中的体验和感受来讲,纯电容触控MCU方案在检测灵敏度、防水性、防误触和电磁干扰(EMI)方面存在不足和优化空间。灵敏度方面,希望触摸电极的设计能有最小的对地寄生电容,这样在触摸状态下会产生更大的相对电容量变化,灵敏度高;在防水和防误触方面,当液体与电容式传感器发生接触时,电容值会增加,很容易造成触控反馈的误判。EMC抗干扰上,特别是抗射频干扰方面,希望触摸电极有低的对地阻抗,以减少射频能量的接收。一般的做法是在触摸电极周围加地线屏蔽环或在PCB的另一面加地屏蔽层,但这势必会增加对地寄生电容降低灵敏度,与上述灵敏度的要求是背离的。另外,在汽车电子应用中,触摸电极往往是单层的ITO或其它薄膜形式,增加地屏蔽层不可实现,这进一步增加了EMC设计的难度和复杂性。综合来看,单纯的电容触控会由于身体的无意触碰、覆盖水滴或者受到外部噪声或电磁干扰等都可能会产生误触发。因此,要实现可靠的电容触摸按键功能需要硬件方面经验的积累和软件算法的多轮优化,最终往往是多个性能指标、可靠性和抗干扰方面的折衷方案。面对这些技术挑战,引入两种不同的检测方式则可以大大简化硬件和软件发面的设计难度,在实现高灵敏度的情况下也可以满足抗干扰性能实现可靠的触摸检测。当前,通过压力传感器+电容触控的技术整合成为了汽车压感触控的创新技术方案,高灵敏度的压力检测用于识别按压动作,电容触控用于按压位置的定位,两者是“与”的关系。采用压力触控和电容触控融合的双模方案存在诸多优势,能很好的解决上述挑战:防水效果好:水流容易造成电容误触但难以造成压力触控的误触,压力和电容采用“与”的方式,水滴或水流同时触发的概率显著降低。另外,通过两种方式产生触发的精确时间和波形形态进行二次软件算法滤波与判断,可完全杜绝由于水造成的可能的误触现象。降低误触:压力+电容触控可消除由于静电、干扰以及无意触碰等导致的误触现象,大大提高可靠性。EMC测试更易通过:压力检测是差分输入,内在对共模干扰有很好的抑制作用,加上电桥等效阻抗低,接收干扰的功率低,抗电磁干扰的性能优异。电容电极类似天线,较容易受到干扰,EMC较难通过,但实现成本低。通过结合压力和电容可以发挥两者各自的优势,缩短开发和测试周期。压力检测装配方式灵活:可以采用表贴也可以采用悬臂梁,简支梁等结构,使用简易。综合来看,双模触控方案具有高可靠性、应用简单以及性价比高等诸多优势,在这场人机交互的变革中,双模汽车压力触控技术将扮演起不可或缺的角色,进而带动车载智能触控产业链技术的创新发展。车规级双模触控MCU,本土厂商新突破从MCU产业模式来看,传统的汽车电子MCU供应商以IDM为主,而基于以往半导体市场盛衰周期的经验,IDM厂商在扩产时会考虑产能利用率和投资回报,扩产相对谨慎,在新的技术浪潮下,新产能投资缓慢。从几个主要MCU 厂商发布的信息来看,随着当下市场需求的快速增长,整个车规级MCU供应状况更加紧张,今年二三季度车规级MCU的价格将有新一波的上涨,货期也在继续拉长,这一趋势预计还会持续较长时间。因此,面对车规级触控MCU向更具技术优势的双模MCU转变趋势,以及该市场的增量需求,英飞凌、Microchip等国外大厂开始变得“束手无力”。一方面,他们尚不能提供创新性的车规级双模触控MCU产品;另一方面,国外大厂在产能、交货周期以及价格和技术支持方面都存在挑战。目前客户端都在积极的寻找替代方案,以满足快速增长的需求。同时,在近两年一系列汽车供应链危机的警醒下,越来越多的自主车企从提升供应链安全的角度考虑,开始有意识地培养本土供应商,这也给了国内芯片企业很好的展示机会。加之芯片持续短缺,也在一定程度上倒逼本土企业自主突围,多重因素的叠加作用下,为本土芯片供应商提供了良好的发展契机。针对车用触控MCU,国内芯片厂商近年来也在积极布局,不断取得新突破。作为本土智能触控芯片赛道的代表厂商,泰矽微今年3月正式量产了专用于汽车智能表面和智能触控开关的TCAE31-QDA2和TCAE11-QDA2两款专用MCU芯片,可以部分解决触控专用MCU市场供应不足,替代品少的问题,两款芯片均已通过AEC-Q100 Grade 2完整的可靠性认证测试。其中,TCAE11是纯电容触摸的芯片,支持最多10路的电容触摸通道,功能上方面可以完全替代国外品牌;而TCAE31则是全球首款同时支持电容触控和压力感应的车规级MCU芯片,截止目前国内外尚未有此类车规级芯片面世。据了解,TCAE31 MCU是泰矽微创新性的将压力触控和电容触控融合形成单芯片解决方案的技术成果,其充分考虑了实际应用中可能面临的复杂变化要素,通过宽范围实时动态补偿结合智能演算法实现压力检测的持续可靠性。再结合电容触摸通道,实现电容+压感复合智能按键,可真正实现汽车应用所需的高抗干扰,防误触,防水等高可靠性要求,适用于如智能表面、智能B柱、智能中控、智能Logo、智能门把手等复杂的车内和车外应用环境。作为用于传统机械按键或旋钮的替代方案,TCAE31在提升用户体验的同时可以简化面板结构设计,降低成本。另外也具有防尘、防水、防静电等防护功能,融合压力和电容两种检测可以避免误判,提高检测可靠性。泰矽微创始人熊海峰向笔者强调,TCAE31单颗芯片即可同时实现两路压力传感和10路电容传感,能够在实现高性能的同时兼顾对功耗的良好控制。此外,在成本方面也是其优势所在。泰矽微研发的车规压力和电容触控二合一双模芯片性价比较高,配合车规级压力触控薄膜传感器,整体成本与传统国外品牌纯电容触控芯片价格相当,但整体可靠性和人机交互体验提升一大截,具有很高的性价比。除了芯片,泰矽微同时还可以为客户提供全方位的用于评估、测试、生产的软硬件平台,涵盖芯片评估、垂直方案、生产以及仿真调试下载工具等,可以简化代码开发,助力客户实现高效的产品开发和导入。泰矽微也可以根据客户特定项目提供从原理图到PCB到EMC 测试的完整方案,进一步缩短产品开发周期。可以看到,相较于国外供应商,泰矽微不仅可以提供更具技术优势的双模触控MCU,并且在供货与支持方面都更有保障,能够提供原厂保供和原创直接技术支持。正因为如此,在TCAExx-QDA2芯片推出后,很快在各类汽车智能按键应用中得到了多个整车厂和Tier1厂商的认可与方案导入。目前已有超50家各类汽车客户和主机厂进入实质开发阶段并有多个定点项目,最早预计将于年内导入量产。值得关注的是,在刚刚举办的第十二届“松山湖论坛”上,泰矽微TCAE31A-QDA2还是本届论坛本土创新IC新品推介产品之一,可见其实力和价值正在得到市场和客户的认可。熊海峰透露,基于已有成绩,目前泰矽微也在围绕智能触控开展下一代产品研发,在兼容通用触控MCU芯片的同时,进一步融入更多的功能,提升芯片集成度,在人机交互方面给予用户更好的体验,引领车规触控芯片市场。写在最后据IC Insights统计,整体MCU市场在2021年的平均售价(ASP)上涨12%,创下25年来的最大涨幅记录。MCU市场历史与未来预测(图源:IC Insights)在经历过2021年全面大缺货后,近期消费类电子市场看到了较为明显的过剩,消费类MCU市场拉货动能趋缓。然而,相比消费市场需求疲软,以汽车为代表的高端应用场景的电子需求还在持续提升,尤其是车用MCU产品景气度依旧较高。IC Insights发布的《McClean》报告指出,今年汽车MCU的增长将超过其他大多数终端市场,预估达215亿美元,年增10%,续创历史新高。其中,车用MCU比重达40%,且为未来5年增速最快的应用市场。综合来看,目前全球MCU市场已出现结构性失衡,消费市场MCU需求有所下降,但部分高端MCU市场依然处于短缺状态,车规级MCU首当其冲。基于车规MCU的战略重要性、稀缺性,出于供应链安全考虑,国内客户对使用国产芯片的意愿不断增强,越来越多的主机厂倾向于优先选择可用的国产MCU芯片。在此过程中,由于国产替代主要对标的是国际大厂,对产品质量的把控,以及在可靠性上持续的优化分析能力尤为关键,其他还包括敏锐的客户服务意识、深入的客户支持、提供整体解决方案的能力和足够的资金支持,都是取胜的关键要素在此趋势和机遇下,随着TCAExx-QDA2系列的正式量产及车厂的产品导入,意味着泰矽微在实现车规级MCU国产替代方面取得了显著进展,并实现了"自我造血"能力。泰矽微的突破也代表着国产MCU的突破。接下来,国产MCU应在市场需求和国产替代的双重契机下,集中力量进一步加大在车规级芯片领域的投入和创新力度,实现车规MCU的新突围,并有序迈入国际市场,在竞合关系中再上新台阶。
企业动态
2022.08.08

外媒称美国商务部已发放通知:禁止半导体设备商向中国提供14纳米及更先进的半导体制造设备!
据彭博社报道,美国的两家主要半导体设备供应商称,美国政府正在收紧对中国获得芯片制造设备的限制,这突显出华盛顿正在加紧努力遏制北京的半导体野心。华盛顿禁止在没有许可证的情况下向中国领先的半导体制造公司出售大多数可以制造10 纳米或更好芯片的设备。泛林集团(Lam Research Corp.)首席执行官 Tim Archer 告诉分析师,现在它已经将障碍扩大到可以制造比 14 纳米更先进的设备,据报道,这种限制除了中国大陆的本土公司,如中芯国际外,还有可能扩大包括了在中国大陆运营的合同芯片制造商运营的其他制造工厂——例如台积电在中国大陆的制造工厂。“我们最近被告知,对于运营在14 纳米以下的晶圆厂,将扩大对中国技术运输的限制。” Tim Archer在周三的电话会议上说。“这就是变化,我认为,人们一直这认为可能会到来,我们准备完全遵守。我们正在与美国政府合作。”在芯片制造中,以较低纳米数识别的生产更先进。这意味着将限制水平从10纳米提高到14纳米将涵盖更广泛的半导体设备。美国商务部在一份声明中表示,它正在收紧针对中国大陆的政策,但没有具体说明精确的芯片具体到多少纳米的制程。“拜登政府专注于削弱中国制造先进半导体的努力,以解决美国的面临的风险竞争。”该机构表示。据知情人士透露,在过去两周左右的时间里,所有美国设备制造商都收到了商务部的来信,要求他们不要向中国大陆提供14纳米或以下的制造设备。他们说,这些信件至少部分是拜登政府努力对中国采取强硬态度,但商务部在这之前已经拒绝了许多 14 纳米的许可证,因此这一新的要求对各公司财务影响不大。新要求针对的是代工厂——为其他人制造逻辑芯片的设备——并且“据我们所知,这不包括存储芯片。“Archer 说。Lam Research 的高管表示,他们已将美国要求的影响纳入他们对 9 月季度的展望,但没有详细说明。科磊(KLA Corp.)首席执行官 Rick Wallace 周四也证实,他的公司已收到美国政府的通知,通知对中国出口许可要求的变化,这些设备适用于比 14 纳米更先进的芯片。Wallace表示,目前这对科磊 的业务没有重大影响。来自这两家总部位于加州的公司的评论标志着拜登政府正在加大遏制中国大陆半导体进步企图的首次详细证实。同时美国也正在游说推动荷兰和日本等伙伴国家禁止ASML 和尼康公司向中国出售光刻机等主流技术,这些技术对制造全球大部分芯片至关重要。 新规则涵盖了众多行业的更广泛的半导体领域,并且可能比针对中芯国际的限制所影响的公司要多得多。虽然新的限制特别涵盖了能够制造比 14 纳米更先进的芯片的设备,但成熟的芯片仍可能受到影响,因为大约 90% 的设备从一代到下一代都兼容。半导体制造商可以在迁移到更复杂的节点时重复使用设备,这意味着禁止一代产品可能会产生长期的连锁反应。中芯国际和台积电是中国拥有最先进逻辑芯片制造能力的两家公司。中芯国际最尖端的技术是14纳米,而台积电在中国大陆最好的技术是16纳米。这比台积电在台湾地区拥有的最尖端技术落后了三代。与美国两个半导体巨头明确表示已收到新规则不同,ASML 的一位发言人表示,该公司尚未收到有关潜在新规则的通知。尼康发言人表示,新规则其对中国的发货不受影响。
企业动态
2022.08.02

GaN-On-SiC的未来
要说GaN有多火,如果你是手机制造商,不推出一款GaN快充可能会被嘲笑“落伍”。而在射频领域,GaN更被认为是高功率和高性能应用场景的未来。在SiC衬底上生长出的GaN呢?优秀基因的强强结合能否成就未来的王者? 快速退火炉,RTA,RTP,快速退火炉RTP“高规格”市场的枷锁 快速退火炉,RTA,RTP,快速退火炉RTPGaN-On-SiC(碳化硅基氮化镓)结合了SiC优异的导热性和GaN高功率高频的特点,目前已广泛应用于5G基站、国防领域射频前端的功率放大器(PA)。快速退火炉,RTA,RTP,快速退火炉RTP在RF GaN行业,碳化硅基氮化镓也确实是一位当之无愧的老前辈。除了在军用雷达方面的深度渗透外,由于能够更好满足5G技术的高功率、高频率及宽禁带等要求,也一直是华为、诺基亚、三星等电信OEM厂商5G基站基础设施的选择。快速退火炉,RTA,RTP,快速退火炉RTP业内人士指出,基站仍然是RF GaN收入的主要来源。“目前5G基站还是以Sub-6GHz通信技术为主,但未来会往毫米波方向布局,会向更高频的技术上发展” ,市场研究机构Yole的分析师邱柏顺在接受集微访谈采访时说。快速退火炉,RTA,RTP,快速退火炉RTP随着全球加速5G部署,碳化硅基氮化镓有望在不久的将来取代硅基LDMOS 在射频市场的主导地位。据Yole预计,到2026年,GaN射频市场将达到24亿美元,2020-2026年复合年增长率为18%。其中,碳化硅基氮化镓射频市场预计达到22亿美元以上,预测期内复合年增长率为17%。快速退火炉,RTA,RTP,快速退火炉RTP和基站市场的火热不同,碳化硅基氮化镓在移动终端领域却格外冷清,尚未开始规模应用。可以这样形容,碳化硅基氮化镓——这位“高规格”市场的老前辈,在面向大众的市场上,还只是一个正待冉冉升起的“新星”。快速退火炉,RTA,RTP,快速退火炉RTP作为限制GaN 同质外延的最主要因素,成本也是碳化硅基氮化镓要提高全民 “喜爱度”必须解决的首要问题。快速退火炉,RTA,RTP,快速退火炉RTP近两年,业界纷纷开始扩展碳化硅基氮化镓的衬底尺寸,以寻求更优的成本效益,包括美国Cree 和Qorvo都在向6英寸升级。去年,NXP宣布在美国亚利桑那州建造的首座6英寸GaN RF晶圆厂正式运营。快速退火炉,RTA,RTP,快速退火炉RTP邱柏顺认为,NXP是一个非常关键的例子,代表了碳化硅基氮化镓正受到主流厂商的采用。未来需求的可预见性增长正加速生产平台从4英寸向6英寸方向演进。预计到2024年,整体市场上的6英寸碳化硅基氮化镓的数量将超过4英寸,6英寸将渐渐成为主流。快速退火炉,RTA,RTP,快速退火炉RTP不过,鉴于碳化硅衬底制造困难,关键技术仍掌握在少数美国厂商如Cree、II-VI等手中,因此在邱柏顺看来,“工艺技术的升级可能仍会先以美国公司为主”,全球范围的推广可能存在时间上的差异。快速退火炉,RTA,RTP,快速退火炉RTP但无论如何,GaN-On-SiC走出“高规格”市场需要的不仅是工艺端的进步,更需要整个供应链协同发展,产业上下游全面建设。快速退火炉,RTA,RTP,快速退火炉RTP来自“大众情人”硅的威胁 快速退火炉,RTA,RTP,快速退火炉RTP这一天多久才能到来? 快速退火炉,RTA,RTP,快速退火炉RTP在那之前,硅基氮化镓能否先于碳化硅基氮化镓在移动终端领域大放异彩?相比于SiC,Si基衬底价格更加便宜,且易于垂直集成,尺寸扩展也相对容易。不过就目前来说,硅基氮化镓PA在5G手机等消费电子领域还处于探索阶段。快速退火炉,RTA,RTP,快速退火炉RTPYole在之前的一份报告中指出,截至2021年第二季度硅基氮化镓的市场容量很小,但硅基氮化镓PA因其大带宽和小尺寸已吸引智能手机OEM,预计可能很快会被支持Sub-6GHz的5G手机型号采用。快速退火炉,RTA,RTP,快速退火炉RTP尽管如此,在邱柏顺看来,硅基氮化镓PA仍然需要打开射频市场。这一过程需要第一个吃螃蟹的公司。谁会最终站出来,并将硅基氮化镓PA的供应链梳理完备?快速退火炉,RTA,RTP,快速退火炉RTP截至目前,包括美光、意法半导体在内的公司都在推动硅基氮化镓研发计划。上半年,雷神和格芯也宣布将合作研发新型硅基氮化镓半导体。国内方面,6月5日,英诺赛科苏州8英寸硅基氮化镓研发生产基地已经正式进入量产阶段。快速退火炉,RTA,RTP,快速退火炉RTP邱柏顺对集微网表示,随着这些重点公司的投入,如果硅基氮化镓迎来产品应用的机会,一些公司也愿意采用,这可能会成为硅基氮化镓打入5G手机PA的契机。快速退火炉,RTA,RTP,快速退火炉RTP但在SiC基GaN领域研究超过十年的SweGaN可不这么认为。快速退火炉,RTA,RTP,快速退火炉RTP瑞典半导体材料公司SweGaN的首席技术官兼联合创始人陈志泰博士在接受eeNews采访时表示,硅基GaN 越来越受到IC设计者的青睐,但当前的技术仍然存在很多问题,最大的问题在于可靠性。快速退火炉,RTA,RTP,快速退火炉RTP据了解,Si与GaN在晶格参数和热膨胀系数上分别有17%与46%的极大差异,以致硅基上生长出的GaN单晶往往会出现龟裂等缺陷,良品率较低。在相同条件下,SiC 的器件的可靠性和使用寿命均胜过Si。快速退火炉,RTA,RTP,快速退火炉RTP据陈志泰称,在硅衬底上,GaN必须生长 5μm 厚度才能达到良好的质量,但GaN-On-SiC只需长到 2μm厚 。而随着 SiC 衬底尺寸不断扩大,将可以生长出缺陷更少、质量更好的GaN外延片。快速退火炉,RTA,RTP,快速退火炉RTP此外,SiC具有高电阻特性,这对毫米波传输十分有益,在设计带有高频MMIC时是必需的。针对这一点,邱柏顺也指出,一些公司未来可以投入新的技术,特别是通过从前段工艺到后段工艺的整体配合,把材料的潜能开发出来,这会是整个供应链的新的商机。快速退火炉,RTA,RTP,快速退火炉RTP站在风口无论是5G基站还是雷达、卫星等国防领域,甚至智能手机的发展,中国的速度举世瞩目。在一系列第三代半导体产业政策背后,国内的GaN-On-SiC产业从衬底,到外延,再到整个垂直工艺端,正不断涌进新的参与者。“整体来说目前的布局还是比较完整的,”邱柏顺说。快速退火炉,RTA,RTP,快速退火炉RTP市场机遇扑面而来,站在风口的“国产三代半”们,准备好了吗?快速退火炉,RTA,RTP,快速退火炉RTP,合金炉,RTO,国产快速退火炉,自主研发,快速退火工艺,半导体设备,芯片退火设备
企业动态
2021.08.23
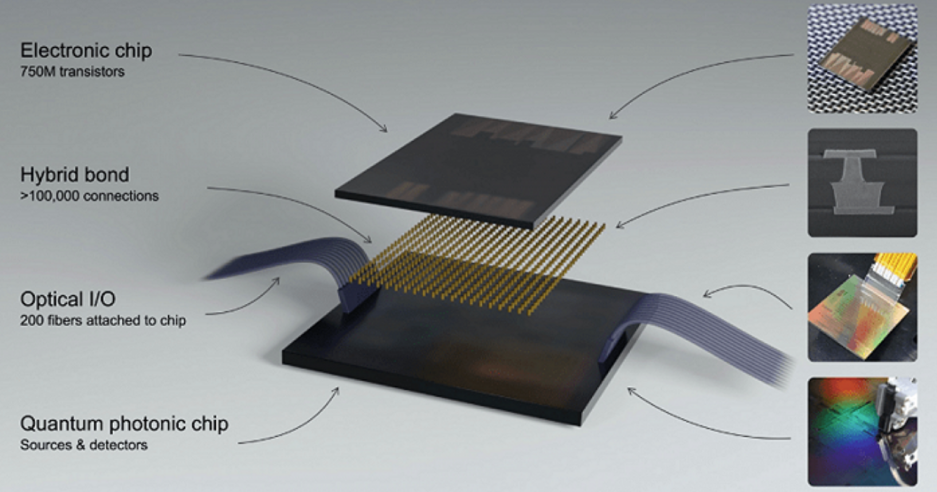
量子和光能超越摩尔吗?
后摩尔时代,全世界的科学家们都在寻找新的计算体系和架构来突破算力瓶颈。量子和光被寄予了厚望,并且在经历了数十年的实验室研究和学术探讨之后,终于开始接近成为一个商业命题。上个月底,美国光量子计算创企PsiQuantum宣布,已完成4.5亿美元的D轮融资。由美国投资管理公司贝莱德(BlackRock)领投,微软M12风险投资基金等跟投。而在5月,PsiQuantum刚和晶圆厂Global Foundries宣布合作推出Q1量子系统,且双方正在生产量子计算机部件和芯片。PsiQuantum称,本轮融资将主要用于建造世界上第一台具有商业可行性的量子计算机。中国资本也同样开始关注这一领域。今年2月刚成立的图灵量子团队,三个月后即宣布完成近亿元人民币天使轮融资,由联想之星领投,中科神光、前海基金、源来资本、小苗朗程跟投。脱胎于上海交通大学集成量子信息技术研究中心,图灵量子的研究团队同时在光量子信息和光子芯片领域研究十余年。图灵光子创始人、上海交通大学集成量子信息技术研究中心主任金贤敏教授介绍,融资将主要用于光量子计算芯片以及光量子计算机的研发。基于光与量子的超越摩尔的漫长产业化征程也由此撕开了一道口子,而挑战才刚刚开始。算力真正爆发的前夜:光与量子能带来什么?人工智能(AI)正在深入改变诸如智能驾驶、语音翻译、新零售、医疗诊断等诸多领域,但计算速度、算力以及功耗问题正在成为AI进一步发展的主要瓶颈。OpenAI发布的分析数据显示,自2012年以来,AI训练对算力的需求每3.43个月翻一番。这一增速明显快于摩尔定律——作为过去几十年来统治计算的一个基准法则,摩尔定律指出,微处理器芯片上的晶体管数每18-24个月翻一番。这意味着,基于冯·诺依曼架构的电子计算机已无法满足大数据时代对算力与功耗的要求。此外,随着晶体管尺寸逼近物理尺寸极限,摩尔定律还将面临散热等无法克服的挑战。近几年,关于用量子和光学芯片加速AI的研究逐渐兴起。“也许我们正处在计算能力真正爆发的前夜。”金贤敏对集微网指出,而提高算力的根本性对策在于提高运算速度和降低运算功耗。这一点上,光学将能让计算机芯片设计克服电子学的根本局限,因为光子是当前速度最快的粒子,相较电子,具有更速度、更低功耗以及低延时等特点,且不易受到温度、电磁场和噪声变化的影响,光子芯片因而也被包括金贤敏在内的海内外科学家视作最有可能替代电子芯片的未来基础性核心技术,也是超越摩尔定律的重要技术基础之一。与此同时,量子计算是后摩尔时代突破算力瓶颈另一项被寄予厚望的技术。相比之下,量子计算经过数十年的发展,已经形成了比较成熟的理论体系。利用量子力学的反直觉特性,可以大幅加速某些类型的计算。这让量子计算机在原理上具有超快的并行计算能力,可望通过特定算法在一些具有重大社会和经济价值的问题方面(如机器学习,密码破译、大数据优化、材料设计、药物分析等)相比经典计算机实现指数级别的加速。不过尽管优势众多,但是过去很长一段时间,光学技术主要应用于通信传输领域,借助光的更快速度、更高容量等特点实现数据的远距离传输,在计算领域则进展缓慢。由于光计算的应用场景不清晰,软硬件体系也不够完善,因而关于如何用光子代替电子芯片执行计算的想法长期停留在研究阶段。量子计算的产业化应用也面临工程和材料上的难题。近年来全球对量子计算的投入持续上涨,据粗略统计,包括美国、英国、中国和德国在内的各国政府合计已投入数十亿美元以推进量子研究。国外高科技企业如谷歌、IBM、微软、英特尔等在量子计算技术方面投入了大量资源,在推动量子计算技术由基础研究向工程化发展迈进方面取得了显著的成效,但目前量子计算机的研究还处于十分初级的阶段。耶鲁大学应用物理教授Steven Girvin博士此前曾对集微网指出,量子计算机还处于普通电脑1940年的阶段,相当于“刚刚做出了真空管,或者刚刚发明晶体管这样的阶段”。光量子芯片或是通向大规模通用量子计算的最可行路径如今,随着以神经网络计算为主的AI应用的普及,需要巨大数据计算量以及高计算速度的深度学习、机器学习等相关应用,将最有可能成为光计算以及量子计算的“应用”。但是光与量子各自面临着不同程度的产业化落地困境。构建实用的光学计算机需要材料科学、光子学、电子学等领域的研究人员之间的广泛跨学科努力和合作。此外,尽管研究表明光子处理器具有较高的单位面积计算能力和潜在的可伸缩性,但是全光学计算规模(光学人工神经元的数量)仍然很小。同时,由于存在固有地吸收光的计算元件,且电信号和光信号经常需要转换,去能量效率也同样会受到限制。同样的,量子计算机也还处在早期发展阶段,目前主流的技术路径有超导、半导、离子阱、光学以及量子拓扑这五个方向。金贤敏指出,而要实现通用的量子计算机有三个前提——百万量子比特的操纵能力、低环境要求、高集成度。在这个意义上,光量子计算机与其他技术路线相比具有明显的优势。而光量子路径也是唯一能够满足这些条件的技术体系,是通向大规模通用量子计算的最可行路径。金贤敏解释,因为量子计算的实现,不能脱离现有大规模的半导体工艺。沿用成熟的CMOS半导体制程,光量子芯片可以实现大规模的生产和制备。基于光量子芯片进行的快速试错和迭代,为构建商用量子计算机提供了坚实的基础。“可以说现在的光量子芯片,处于当年电子芯片的仙童半导体时代。”金贤敏称,当前光量子芯片发展正处于类似当年大规模集成电路发展初期的关键节点,即将爆发的关键前期节点。而从全球来看,目前各国在量子与光子计算领域均未形成绝对优势,现阶段各国研发基本处于同一起跑线,对于国内产业界来说具备换道超车的重大战略机遇。金贤敏进一步解释,目前这个领域还处于刚刚起步阶段,还不够大,不像电子芯片那么细化,“现在我们一个团队就可以把目前光子芯片设计的EDA软件搞定。”集微网了解到,图灵量子团队目前已掌握了自主知识产权的三维和超高速光子芯片核心技术与工艺,从设计、流片到封装测试,再到系统集成和量子算法,可实现光量子计算芯片的全链条研发。目前,已有大量的量子算法内核在光量子计算芯片上得到了实现。金贤敏称,基于底层技术的相通性,未来将实现与光有关的技术全覆盖。其中光子芯片技术,在获得规模化商用后有望可以解决我国芯片“卡脖子”的难题,摆脱受制于关键技术、关键设备的困境。超越摩尔之路:未来是“架构为王”的时代在后摩尔时代的突破算力瓶颈的探寻之路上,金贤敏认为,未来一定是“构架为王”的时代,光量子芯片凭借全新的构架和大算力等特点,有望创造全新的机会。在他看来,随着量子计算技术和光量子集成能力持续演进,混合光量子计算架构、光子计算,以及人工智能光子处理器会展现出巨大潜能。此外,另一个研究途径是发展先进的非线性集成光子计算体系结构,即通过将电子电路和数千或数百万个光子处理器集成到合适的体系结构中,同时利用光子和电子处理器的混合光电框架可能在不久的将来,带给AI硬件的变化。这些硬件将在通信、数据中心操作和云计算等领域具有重要的应用。不管哪一种技术路径,架构创新成为未来计算创新的关键驱动力已经成为业界共识。比如英特尔近年来一直在推进的XPU战略,就是用不同的架构去处理不同类型的数据,根据处理速度和带宽的不同要求去优化。其中,CPU适宜处理标量架构,GPU则适宜处理矢量运算,AI则更多是块状运算,FPGA则适合做一些稀疏的运算,可以大幅度降低I/O以及计算的消耗。“把它们整合起来就能各取所需,打组合拳会好过只用一种武器去解决所有问题。”在今年世界人工智能大会期间,英特尔研究院副总裁、英特尔中国研究院院长宋继强指出,他还特别介绍了集成光电的创新路径,认为光是替代铜的非常好的互联介质替代品。而针对光本身的一些问题,如光的器件都比较大,光和电之间的转换也比较困难且效率不高。而英特尔正在从几个方面解决这一问题。首先是把光器件与电器件紧密封装在一起,减少两端转换的损耗;其次是制作出收发器,以更小的模式放到服务器当中,比如硅光产生、光的发射、调制,接收端的检测、放大等光处理的中间过程的几个模块做成非常小的模块,可以和CMOS光处理器件整合到一个芯片中,这样集成的光电可以大幅度缩小系统的尺寸和功耗。超越摩尔的探索之路刚刚开始,但无论是传统电子芯片,还是未来的光与量子,都需要经过一个漫长的技术积累的过程。在传统电子芯片时代,国外巨头们正是通过漫长的技术迭代,通过产业落地和应用的规模化,诞生了一个又一个“伟大的科技公司”。同理,在未来的光与量子计算的领域,也必将经历这样一个过程。
企业动态
2021.08.16

SiC、GaN功率元件5年内成本将逐步降低
英飞凌大中华区电源与感测系统事业部协理陈志星日前表示,SiC、GaN等新材料产品,公司旗下已有CoolSiC、CoolGaN系列产品线走入量产,未来从目前主流的6英寸厂转到8英寸晶圆厂生产则是国际大厂看好的共同趋势。据digitimes报道,陈志星指出,SiC、GaN相关宽能隙(WBG)功率元件价格已经出现很大的降幅,但成本仍是打开市场的关键,SiC/GaN两者之间价差不大,但与Si(硅)产品之间的落差确实存在,英飞凌则预期,在经济规模、产能投资、良率控制等推进下,成本可望有效下降,预期3~5年后有机会把成本降到跟硅基元件相仿的程度,后段制程技术也持续推进。从英飞凌的产能规划上来看,该公司领先业界率先以12英寸晶圆厂生产硅基功率元件,SiC材料已经问世20多年,GaN则是近年来较受重视,SiC以往以2、4英寸厂生产,现今走到主流的6英寸,未来走到8英寸厂生产是相当正常的。
企业动态
2021.08.12
仪器信息网APP

展位手机站