
视频号

抖音号

哔哩哔哩号

前沿资讯手机看



分享到微信朋友圈
打开微信,点击底部的“发现”,
使用“扫一扫”即可将网页分享到朋友圈。
浅谈多元校正建模的几个常见问题
王冬
北京市农林科学院质量标准与检测技术研究所, 北京 100097
摘要 本文分别从样品代表性、数据分集、线性与非线性算法、关键变量筛选、异常样本的剔除、模型维数的选择与模型评价等方面分析了多元校正建模的常见问题。本文可为多元校正模型的建立、优化与维护提供一定的参考。
1. 引 言
近年来,化学计量学的发展、计算机技术和制造技术的进促使近红外光谱以及近红外高光谱技术高速发展。采用近红外光谱、近红外高光谱建立待测物质中目标物质含量的定量校正模型是近红外光谱、近红外高光谱分析过程的重要环节。本文对多元校正定量模型的建立过程,从样品代表性、数据分集、线性与非线性算法、关键变量筛选、异常样本的剔除、模型维数的选择与模型评价等方面对多元校正建模的常见问题展开讨论,以期为多元校正建模过程提供一定的参考。
2. 多元校正建模的常见问题
以下分别从样品代表性、数据分集、线性与非线性算法、关键变量筛选、异常样本的剔除、模型维数的选择与模型评价等方面分析多元校正建模的常见问题。
2.1 样品代表性
样品代表性强调多元校正建模需使用具有代表性的样品,即代表性样品。代表性样品是建立多元校正模型的基础。样品的代表性一般包含样品的品种代表性、空间(地域)代表性、时间代表性。在建立多元校正模型前,需要特别注意所收集样品是否具有足够的代表性。
一组具备良好代表性的样品应尽量包含分析工作中遇到的各种情况。以建立樱桃可溶性固形物含量多元校正模型为例,所收集的代表性样品应均匀覆盖一定的品种和地域范围,例如一定的园区、县域、市域等,尽量涵盖各品种的样品。另一方面,欲建立一个较为稳健的校正模型,尤其对农产品,还需考虑农产品的时间代表性。对于农产品,时间代表性主要体现在两方面:一是一年之内的时间代表性,例如樱桃从成熟、采摘到入库、储存;二是跨年的时间代表性,例如对某地樱桃连续3~5年采样。这样做的原因是,农产品内部各种物质的相对含量会因水肥、光照、温度等的年度差异而不同,且农产品不能用已知材料“勾兑”;因此对于农产品需要连续3~5年采样,并根据具体情况逐年维护,从而保证校正数据中含有足够多的、代表性充足的样品,进而为提高所建模型的稳健程度提供具有充足代表性的基础数据。
2.2 数据分集
数据分集将全部数据中的一部分划分为外部验证集,该部分样品不参与模型的建立过程,只用来对模型的预测性能做出评价;余下的样品作为校正集。因此,所选的外部验证集必须要有足够的数据代表性。这里所谓的“数据代表性”主要是指所选的外部验证集数据、校正集数据应该和全部样本数据具有相似的数据分布特征或趋势,以图1为例说明。
图1中,第1行示意全部样本数据的分布,第2~6行蓝色圆圈表示校正集数据的分布,红色菱形表示外部验证集数据的分布。从图1可见,很明显,只有ExVal.-1的外部验证集数据和其对应的校正集数据与全部样本数据具有相似的数据分布特征;ExVal.-2数据分布位于原数据集的左侧,即数值偏小;ExVal.-3数据分布位于原数据集的右侧,即数值偏大;ExVal.-4数据分布集中于原数据集的中部;ExVal.-5数据分布位于原数据集的左右两端;ExVal.-6数据分布集中于原数据集的中部且数据量明显少于其他外部验证集。
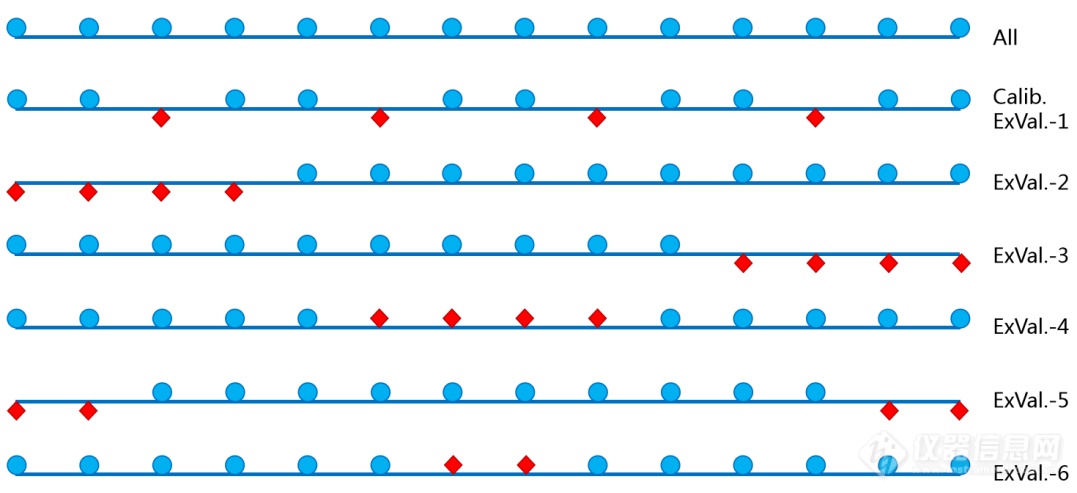
图1 各数据集分布示意图
为了对数据分集所得的校正集和外部验证集的数据代表性进行量化分析,对全部样本(All)数据、校正集(Calib.)数据、外部验证集(ExVal.-1)数据以及其他几种外部验证集(ExVal.-2 ~ ExVal.-6)数据分别计算样本容量(n)、最小值(Min)、最大值(Max)、平均值(Ave)、样本标准差(Std)、极差(Rx)和变异系数(CV),如表1所示。
从表1数据可见,根据Min、Max、Ave、Std、Rx、CV的数据特征可以得知,Calib.和ExVal.-1皆与All具有相似的数据分布特征。ExVal.-2由于所选外部验证集数值偏小,其数据分布特征和All的数据分布特征的差异主要体现在Max、Ave、Std、Rx、CV;ExVal.-3由于所选外部验证集数值偏大,其数据分布特征和All的数据分布特征的差异主要体现在Min、Ave、Std、Rx、CV;ExVal.-4由于所选外部验证集集中于All的中部,其数据分布特征和All的数据分布特征的差异主要体现在Min、Max、Std、Rx、CV;ExVal.-5由于所选外部验证集分布于All的左右两端,其数据分布特征和All的数据分布特征的差异主要体现在Std、CV;ExVal.-6由于所选外部验证集集中于All的中部且数据量明显少于其他外部验证集,其数据分布特征和All的数据分布特征的差异主要体现在Min、Max、Std、Rx、CV,同时,ExVal.-6的n也可间接说明了该问题。
最后要注意的是,校正集和外部验证集的样本容量之比一般为3:1 ~ 5:1;特殊情况除外。
表1 各数据集统计信息
Stat. | All | Calib. | ExVal.-1 | ExVal.-2 | ExVal.-3 | ExVal.-4 | ExVal.-5 | ExVal.-6 |
n | 25 | 20 | 5 | 5 | 5 | 5 | 5 | 2 |
Min | 1.19 | 1.19 | 2.93 | 1.19 | 8.59 | 5.65 | 1.19 | 6.04 |
Max | 10.24 | 10.24 | 9.58 | 4.15 | 10.24 | 6.52 | 10.24 | 6.38 |
Ave | 6.30 | 6.26 | 6.43 | 2.72 | 9.41 | 6.08 | 6.42 | 6.21 |
Std | 2.43 | 2.48 | 2.49 | 1.39 | 0.66 | 0.37 | 4.70 | 0.24 |
Rx | 9.05 | 9.05 | 6.65 | 2.96 | 1.65 | 0.87 | 9.05 | 0.34 |
CV | 38.6% | 39.6% | 38.7% | 51.0% | 7.0% | 6.1% | 73.1% | 3.9% |
从以上分析可见,当数据集划分不合理时,所选数据集(例如外部验证集)的Min、Max、Ave、Std、Rx、CV的数值会表现出和全部样本数据对应统计量数值的差异,从而提示数据集划分存在问题。因此,建立校正模型前,应对校正集数据、外部验证集数据和全部样本数据分别计算n、Min、Max、Ave、Std、Rx、CV统计量,并比较三个数据集的各统计量是否存在明显差异。
2.3 线性和非线性算法
选择线性拟合算法、亦或是非线性拟合算法,是建立校正模型过程的重要问题。线性拟合和非线性拟合各有优点,也各有不足。一般地,非线性拟合模型较线性拟合模型具有更高的复杂程度和更多的不确定性,选择拟合算法应以合适为原则。
以下举例说明线性拟合算法和非线性拟合算法的选择。图2(a)中“▲”代表校正集数据。线性拟合模型、非线性拟合模型的预测值-参考值回归方程和测定系数(Determination Coefficient, R2)如表2所示。结合图2(a)和表2数据可见,非线性拟合模型的拟合准确度更高。然而,待测样本的数据分布如图2(b)的菱形(◆)所示。显然,对于如图2(b)所示的待测样本数据,用线性拟合模型所得的预测值将具有更小的预测误差。
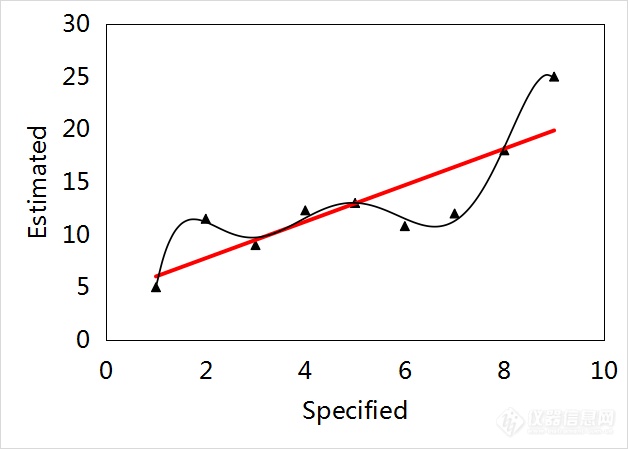
(a)
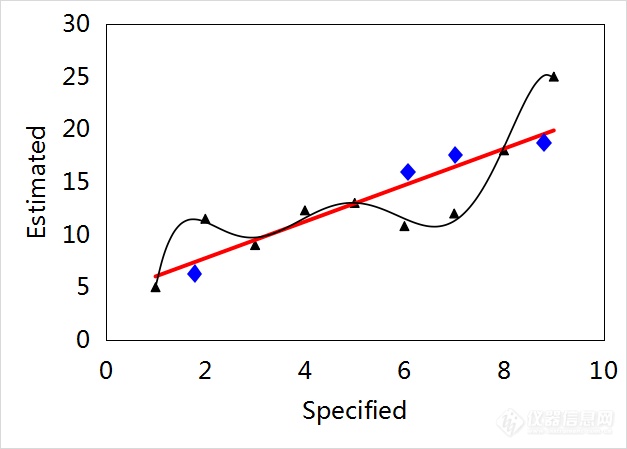
(b)
图2 线性拟合模型和非线性拟合模型示意图
▲校正集数据, ◆待测数据
表2 线性拟合模型和非线性拟合模型的预测值-参考值回归方程和测定系数
模型 | 回归方程 | R2 |
线性 | Y=1.7333X+4.2889 | 0.6999 |
非线性 | Y=-0.0145X6+0.4367X5-5.1345X4+29.851X3-89.49X2+130.05X-60.644 | 0.9912 |
在这里需要注意的是,如果数据本身确实是遵循非线性规律,就需要使用非线性拟合算法对其建立校正模型。
2.4 关键变量筛选
对于近红外光谱,通过一定的算法筛选关键变量在一定程度上可以减少参与建模的变量个数,减轻运算负荷并提高运算速度。然而,对于建立校正模型,特别是定量校正模型,所选变量的稳定性是筛选关键变量不可避免的问题。这里所谓的“变量的稳定性”,是指所选变量在校正集发生变化时还能保持其关键变量特征的属性。
这里建议采用蒙特卡洛方法和变量筛选方法相结合,通过设置蒙特卡洛方法的单次采样率和蒙特卡洛次数2个关键参数,相当于获得了基于原校正集的多个子校正集。再通过对多个子校正集筛选关键变量,从而进一步对所选变量的稳定性进行比较与评估,进而提高所选关键变量的稳定性。
2.5 异常样本的剔除
在建立校正模型时,常会遇到异常样本。异常样本对模型准确度具有很大的负面影响。正确地识别异常样本并对其进行剔除,可以有效提高模型的准确度。异常样本的识别方法有很多,本文采用预测残差和杠杆值相结合的方法对异常样本进行识别。通常,预测残差阈值设定为全部校正集样本预测残差平均值的2倍,杠杆值阈值设定为全部校正集样本杠杆值平均值的3倍。当某个样本同时满足预测残差大于预测残差阈值、杠杆值大于杠杆值阈值时,可判定该样本为异常样本,应予以剔除。
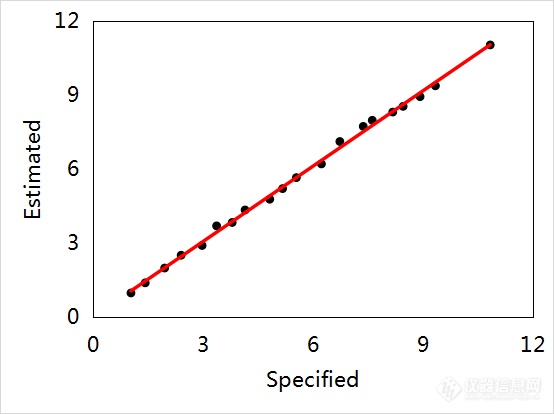
下面以图3结合表3数据说明剔除异常样本对模型的影响。图3(a)是剔除异常样本前预测值-参考值相关关系图。从图3(a)结合表3数据可见,由于异常样本的存在,模型测定系数(Determination Coefficient, R2)仅0.5766,均方根误差(Root Mean Square Error, RMSE)为2.17。当剔除异常样本后,如图3(b)所示并结合表3数据可见,模型R2提高到0.9977,RMSE下降到0.19。可见,剔除异常样本有利于减小模型的误差、提高模型的准确度,进而可提高模型的预测性能。
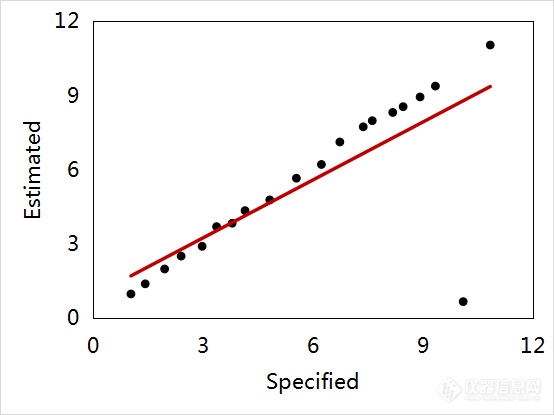
(a)
(b)
图3 剔除异常值前(a)、后(b)的预测值-参考值相关关系图
表3 剔除异常样本前、后的预测值-参考值回归方程、测定系数和均方根误差
剔除异常样本 | 回归方程 | R2 | RMSE |
剔除前 | Y=0.7797X+0.9081 | 0.5766 | 2.17 |
剔除后 | Y=1.0174X+0.0160 | 0.9977 | 0.19 |
2.6 模型维数的选择与模型评价
不同于一元线性回归只有1个自变量,多元校正模型有多个自变量。在建立多元校正模型时,模型自变量的个数即模型维数的选择成为另一个关键问题。一般地,在建立多元校正模型的过程中,往往计算多个维数,再通过预测残差平方和(Prediction Residual Error Sum of Squares, PRESS)随模型维数(Nf)的下降趋势判断多元校正模型的最佳维数。
图4分别为PRESS随Nf变化的3种较为典型的情况。图4(a)中,PRESS随Nf的增加先下降、后上升,在Nf= 6时达到最小;此种情况一般选PRESS最小值所对应的Nf作为模型的最佳维数。图4(b)中,PRESS随Nf的增加一直下降,此种情况需要对各维数PRESS下降值做显著性检验,当PRESS下降不显著时,则取上一个Nf作为模型的最佳维数;图4(b)中,Nf从6到7时PRESS下降不显著,因此模型的最佳维数定为6。图4(c)是较为隐匿的情况,Nf从4到5时PRESS下降不显著,但PRESS在Nf从5到6又发生了显著下降,因此该种情况模型的最佳维数应定为6而不是4。
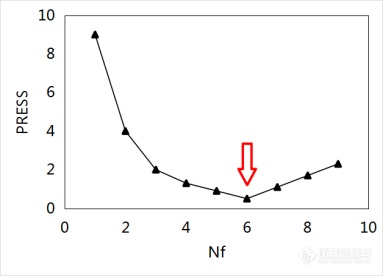
(a)
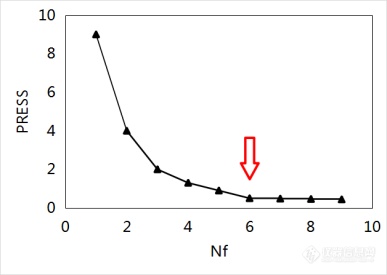
(b)
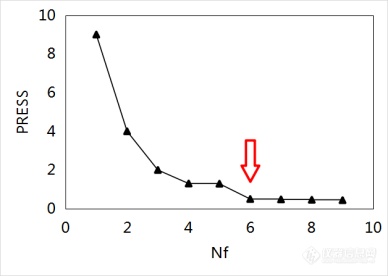
(c)
图4 PRESS随Nf变化示意图
在建立多元校正模型时还需注意模型的欠拟合和过拟合问题。如图5所示,所谓欠拟合是指模型维数低于最佳维数,导致所建模型的预测能力不足;所谓过拟合是指模型维数高于最佳维数,亦会导致所建模型的预测能力下降。

图5 欠拟合、过拟合、理想情况的PRESS随Nf变化示意图
欠拟合、过拟合和理想情况的预测值-参考值的相关关系图如图6所示,其对应的回归方程、R2和RMSE如表4所示。图6(a1)、图6(a2)分别是欠拟合校正、交互验证数据的预测值-参考值相关关系图;结合表4数据可见,欠拟合的校正、交互验证R2皆不高,RMSE皆较大。图6(b1)、图6(b2)分别是过拟合校正、交互验证数据的预测值-参考值相关关系图;结合表4数据可见,过拟合的校正R2很高,而交互验证R2不高,二者相差很大;另一方面,过拟合的校正RMSE很小,而交互验证RMSE很大,二者相差也很大。图6(c1)、图6(c2)分别是理想情况校正、交互验证数据的预测值-参考值相关关系图;结合表4数据可见,理想情况的校正、全交互验证R2皆较高且二者相差不大,RMSE皆较小且二者相差不大。欠拟合、过拟合皆不能用于实际工作。
造成上述现象的主要原因是:对欠拟合模型,由于模型维数过低,没有提取到足够的有用信息,导致模型的预测准确度下降。对过拟合模型,由于模型维数过高,在提取有用信息的同时还裹挟了校正集的噪声信息;由于模型维数过高,模型对校正数据进行自预测的准确度显然是很高的,但是对于交互验证,由于所建模型裹挟了校正集的噪声信息,因此对交互验证的预测准确度很低。

图6 欠拟合、过拟合、理想情况的校正、交互验证数据预测值-参考值相关关系图
(a1)欠拟合校正, (a2)欠拟合全交互验证, (b1)过拟合校正, (b2)过拟合全交互验证,
(c1)理想情况校正, (c2)理想情况交互验证
表4 欠拟合、过拟合、理想情况校正、交互验证回归方程、测定系数和均方根误差
拟合情况 | 数据集 | 回归方程 | R2 | RMSE |
欠拟合 | 校正 | Y=1.0676X+0.1742 | 0.7986 | 1.75 |
全交互验证 | Y=0.9135X+0.5115 | 0.7123 | 1.79 | |
过拟合 | 校正 | Y=0.9989X+0.0299 | 0.9996 | 0.07 |
全交互验证 | Y=0.9671X+0.1071 | 0.7698 | 1.62 | |
理想 | 校正 | Y=0.9918X-0.0564 | 0.9630 | 0.60 |
全交互验证 | Y=0.9770X+0.2067 | 0.9597 | 0.62 |
对多元校正模型的评价,主要从相关性和误差两个方面进行。对多元校正模型的相关性一般采用测定系数(Determination Coefficient, R2)作为评价参数:R2取值范围为0 ~ 1,且R2值越接近1,模型的相关性越强,反之亦反。对多元校正模型的误差一般采用均方根误差(Root Mean Square Error, RMSE)作为评价参数:一般地,RMSE值越小,模型的误差越小,反之亦反。对应不同的数据集,测定系数有:校正测定系数(Determination Coefficient of Calibration, R2C)、交互验证测定系数(Determina Coefficient of Cross Validation, R2CV)、预测测定系数(Determination Coefficient of Prediction, R2P),均方根误差有:校正均方根误差(Root Mean Error of Calibration, RMSEC)、交互验证均方根误差(Root Mean Error of Cross Validation, RMSECV)、预测均方根误差(Root Mean Error of Prediction, RMSEP)。
除此之外,评价模型的另一个重要指标是相对预测性能(Ratio Performance Deviation, RPD)。RPD的大小反映模型预测性能的高低。一般地,RPD ≥ 3.0表示模型预测能力较好,可以用于实际工作;1.5 ≤ RPD < 3.0表示模型预测能力一般,通常只能用于快速筛查;RPD < 1.5表示模型预测能力较差,一般不能用于实际工作。
2.7 避免“假线性”
在建立多元定量校正模型时还需要注意避免“假线性”。如图7所示,从图7(a)和图7(b)可见,这两组数据的线性很差。然而,当把图7(a)和图7(b)的数据放在一起,如图7(c)所示,结合表5数据可知,放在一起的数据,即数据集(c),所建模型的R2超过0.999,貌似线性很好,但实际上这是“假线性”。从RMSE数据可见,数据集(c)的模型并未因其R2的增大而明显减小。数据集(c)的模型如果用于实际工作,会存在很大的风险。导致该现象的主要原因是,两组数据之间跨度过大,并且在两组数据之间缺失样本。这样的“假线性”应特别注意并避免。
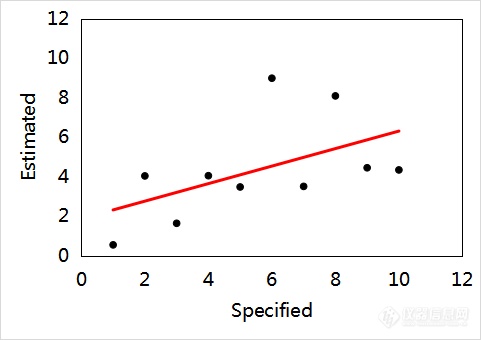
(a)
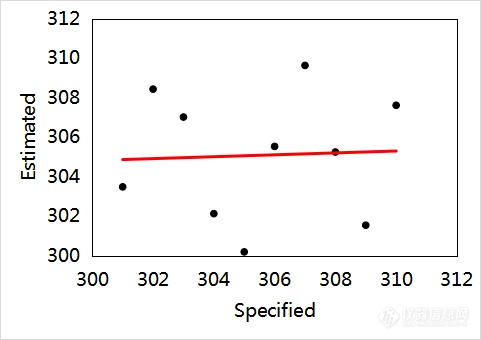
(b)
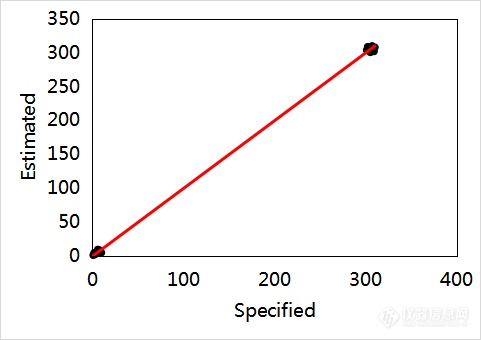
(c)
图7 三种数据集的预测值-参考值相关关系图
表5 三种数据集的预测值-参考值回归方程、测定系数和均方根误差
数据集 | 回归方程 | R2 | RMSE |
(a) | Y=0.4436X+1.8685 | 0.2753 | 3.03 |
(b) | Y=0.0482X+290.36 | 0.0021 | 4.30 |
(c) | Y=1.0023X-1.1627 | 0.9995 | 3.62 |
3. 总结
校正模型是近红外光谱、近红外高光谱能够进行高效分析的数学基础。建立性能良好的校正模型对实现近红外光谱、近红外高光谱无损、快速、高效分析是非常重要的。多元校正建模过程需要注意很多细节,包括样品代表性、数据分集、算法选择、关键变量筛选、异常样本剔除、模型维数选择、模型评价等。在其中,样品代表性是基础,也是决定建模工作成败的关键之一。对于农产品,还要特别注意样品的时间代表性。
建立校正模型并不是一劳永逸的工作。模型不是产品,而是一种方法。当样品的情况发生变化时,所建模型很可能不再适合当前样品,就需要对模型进行维护,甚至重建。需要特别注意的是,多元校正模型有严格的应用前提;如果不满足模型的应用前提,模型预测值的准确性将难以保证。
进一步地,建模过程要秉承客观公正的原则。例如:在剔除异常样本方面,对异常样本的识别需要有一定的根据,不能凭感觉剔除所谓的异常样本;在模型评价方面,需要客观地根据有关统计量的数据对模型的准确度、精密度、预测性能等进行客观公正的评价,不可以根据主观好恶随意调节模型维数。
作者简介:
 王冬,男,1982年生,籍贯北京;2010年毕业于中国农业大学,获得农学博士学位;现就职于北京市农林科学院质量标准与检测技术研究所,副研究员;主要研究方向为振动光谱分析与化学计量学,主要从事近红外光谱、中红外光谱、拉曼光谱、太赫兹波谱无损快速分析工作。曾主持完成中国博士后科学基金会、科技部国家科技支撑计划子课题任务、北京市农林科学院博士后基金、北京市农林科学院青年基金、北京市农林科学院科技创新能力建设专项储备性研究课题等,曾以科研骨干身份参加农业农村部公益性行业(农业)科研专项课题、科技部国家重大科学仪器设备开发专项、北京市科委专项课题等。截至目前在振动光谱和化学计量学等有关领域发表学术论文60余篇,其中第一作者论文40余篇;获授权发明专利9项、实用新型专利3项;获得软件著作权2项;参编著作及科普读物4部;参与制定国家标准1项;合作指导硕士研究生2名;获得中华人民共和国教育部高等学校科学研究优秀成果奖-科技进步奖一等奖1项、中华人民共和国农业农村部神农中华农业科技奖一等奖1项。
王冬,男,1982年生,籍贯北京;2010年毕业于中国农业大学,获得农学博士学位;现就职于北京市农林科学院质量标准与检测技术研究所,副研究员;主要研究方向为振动光谱分析与化学计量学,主要从事近红外光谱、中红外光谱、拉曼光谱、太赫兹波谱无损快速分析工作。曾主持完成中国博士后科学基金会、科技部国家科技支撑计划子课题任务、北京市农林科学院博士后基金、北京市农林科学院青年基金、北京市农林科学院科技创新能力建设专项储备性研究课题等,曾以科研骨干身份参加农业农村部公益性行业(农业)科研专项课题、科技部国家重大科学仪器设备开发专项、北京市科委专项课题等。截至目前在振动光谱和化学计量学等有关领域发表学术论文60余篇,其中第一作者论文40余篇;获授权发明专利9项、实用新型专利3项;获得软件著作权2项;参编著作及科普读物4部;参与制定国家标准1项;合作指导硕士研究生2名;获得中华人民共和国教育部高等学校科学研究优秀成果奖-科技进步奖一等奖1项、中华人民共和国农业农村部神农中华农业科技奖一等奖1项。
作者邮箱: wangd@iqstt.cn, nirphd@163.com.
[来源:仪器信息网] 未经授权不得转载

多元化产品线布局,坚持技术突破与创新——访元析仪器生命科学部门经理章宏飞
2023.07.20

视频回看上线|“高光谱技术在农业领域的最新应用进展” 网络研讨会成功召开
2023.08.11

2023.08.15


“中国近红外光谱三十年贡献人物”候选人申报材料提交截止日期延至2024年7月31日
2024.07.08

全国第十届近红外光谱学术会议征稿截止日期延至2024年7月31日
2024.07.05
品牌合作伙伴






























版权与免责声明:
① 凡本网注明"来源:仪器信息网"的所有作品,版权均属于仪器信息网,未经本网授权不得转载、摘编或利用其它方式使用。已获本网授权的作品,应在授权范围内使用,并注明"来源:仪器信息网"。违者本网将追究相关法律责任。
② 本网凡注明"来源:xxx(非本网)"的作品,均转载自其它媒体,转载目的在于传递更多信息,并不代表本网赞同其观点和对其真实性负责,且不承担此类作品侵权行为的直接责任及连带责任。如其他媒体、网站或个人从本网下载使用,必须保留本网注明的"稿件来源",并自负版权等法律责任。
③ 如涉及作品内容、版权等问题,请在作品发表之日起两周内与本网联系,否则视为默认仪器信息网有权转载。
![]() 谢谢您的赞赏,您的鼓励是我前进的动力~
谢谢您的赞赏,您的鼓励是我前进的动力~
打赏失败了~
评论成功+4积分
评论成功,积分获取达到限制
![]() 投票成功~
投票成功~
投票失败了~










