【网络讲座】ADMET性质预测及建模软件ADMET Predictor在药物研发中的应用http://www.pharmogo.com/upload/%E7%AB%8B%E5%8D%B3%E6%8A%A5%E5%90%8D(10).png 【内容】计算机模拟通过已有的实验数据及自身的算法,可快速预测药物的吸收、分布、代谢、毒理性质。美国Simulations Plus公司开发的ADMET Predictor软件,现已在国内外的药品监管部门(FDA, CFDA, EMA、EPA等)、各制药企业(罗氏、诺华、礼来、药明康德等)、研究单位(中国科学院、上海药物所、协和药物所、军科院、上海医工院、中国药科大学、上海中医药大学等)得到了广泛的应用,为他们的药物研发工作提供了强有力的技术支持。本次网络会议将向您详细展示ADMET Predictor现有的143个模型预测的功能;介绍如何通过软件预测为药物设计、筛选过程提供帮助;讲解采用该软件的自建模型功能快速搭建属于您自己的QSAR模型。期待通过本次软件的功能介绍和应用案例演示,能让您更好地熟悉这款软件,并将其用于您日常的科研工作中。在这盛夏的午后,期待您的参与!主题ADMET性质预测及建模软件ADMET Predictor在药物研发中的应用时间2014年8月21日 (周四) 下午3:00-4:30主办方上海凡默谷主讲人陈涛、李平 产品经理 【关于ADMET Predictor】:点击了解详情全球领先的药物ADME/Tox性质预测软件 FDA、CFDA、美国环保署EPA、欧盟化学品管理局ECHA等法规部门长期信赖的ADMET预测软件 TOP 50制药企业,学术单位运用最广的ADMET预测软件只需输入化学结构式,即可快速准确地预测理化性质、吸收、分布、代谢、排泄及毒性等性质,还可利用已有的数据,通ADMETPredictor搭建高质量的QSPR预测模型。如需了解更多信息,请联系我们:电话:021-50510193;邮箱:market@pharmogo.com;客服QQ:1114996120http://www.pharmogo.com/upload/QQ%E5%9B%BE%E7%89%8720140604144550.jpg 加入微信,更多资讯

[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]快速检测人血白蛋白原液蛋白质含量的建模研究摘要:本研究建立[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]定量分析模型,对浓缩液蛋白含量进行快速及有效的测定。在实验室条件下配置不同浓度的蛋白样品,建立用于蛋白含量测定的定量分析模型,以实现浓缩液蛋白含量的快速及有效的判断。关键词:[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术;人血白蛋白;定量分析模型1材料1.1 试剂供试品:人血白蛋白原液;生理盐水。1.2 仪器和软件AntarisⅡ傅里叶变换[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url](美国Thermo Fisher scientific公司);内径4×50 mm的玻璃小管(Kimble Chase,德国); MATLAB 2015a(美国Mathworks公司);PLS_Toolbox工具箱(美国Eigenvector Research公司)。2方法2.1 蛋白含量的测定及样品溶液的配制2.1.1 蛋白质含量的测定取生产过程中超滤浓缩后的人血白蛋白原液为实验供试品,用半微量凯氏定氮法测定蛋白质浓度,浓度应不低于26.5%。2.1.2样品溶液的配制根据试验需要,将供试品溶液用生理盐水进行稀释得到多个不同蛋白质浓度的实验样品。2.2 样品光谱的采集本实验使用AntarisⅡ傅里叶变换[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url],采用透射分析模块,采用仪器自带的RESULT-Intergration软件编写采集光谱的工作流程。光谱分辨率为8 cm-1,扫描范围为10000-4000 cm-1,扫描次数为32次,用偏最小二乘回归(Partial Least Squares Regression, PLSR)方法建立定量模型。2.3 校正集和验证集的划分校正集中的样品应包含使用该模型预测的未知样品的所有化学成分。且校正集中的样品的化学成分浓度范围应覆盖使用该模型预测的未知样品中可能存在的浓度范围。而且验证集中的样品应涵盖使用模型分析的待测样品中的化学组成,测定浓度范围也应尽可能覆盖该模型分析的待测样品可能存在的浓度范围,且分布均匀。所以,需要选择合理的样品集划分方法,以提高模型的应用性及准确性。2.4 预处理方法的选择为了消除噪声和产生的基线漂移,提高模型的预测能力,得到稳健的模型,需要在模型建立前对样品的原始光谱进行预处理,常用的谱图处理方法有均值中心化(Mean Center)、标准化(Auto scale)、平滑和导数等。导数是常用的基线校正和光谱分辨预处理方法,但也会放大噪声的信号,降低光谱的信噪比;为消除光谱变换带来的噪声,常对原始光谱进行平滑后求导,能有效提高信噪比;均值中心化可增大不同样品之间的差异,从而使模型的稳健性和预测能力得到提高;标准化可以使光谱中所有波长变量的权重相同,增加光谱之间差异化,适合于低浓度成分的建模。本研究中对Auto scale、Mean Center、一阶导数(First Derivative,FD)SG13点平滑、二阶导数(Second Derivative,SD)SG13点平滑等预处理方法进行了考察,以模型的RMSEP为指标,选择最合适的预处理方法。2.5 光谱区间的选择[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]信息十分复杂,在建立校正模型的过程中选择有效的建模变量是十分必要的。本研究选用间隔偏最小二乘法(Interval Partial Least Squares Regression, iPLS)),以RMSECV值为评价标准,选择变量区间以建立最佳的定量模型。3 实验结果3.1 蛋白质含量的测定结果采用半微量凯氏定氮法进行蛋白含量的测定,测定得到17个样品的蛋白含量。用生理盐水稀释样品,共得到49个不同蛋白质含量的样品。3.2 样品的原始光谱图1为49个蛋白样品的原始光谱,原始光谱图中可见各样品的光谱差异不明显,因此需要使用化学计量学方法对样品光谱进行处理。[align=center][img=,494,237]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151606_01_1626619_3.png[/img][/align][align=center]图1 样品原始光谱图[/align]3.3 校正集和验证集的划分结果本研究采用Kennard-Stone(K-S)分类的算法,按照2:1的比例进行样品集的划分,划分为33个校正集样品和16个验证集样品。图2为校正集样品和验证集样品的主成分得分图,图中灰色点为校正集样品,红色点为验证集样品,从主成分得分图中可以看出,校正集样品和验证集样品分布比较均匀,且验证集样品比较均匀的分布在校正集样品之间,符合理想校正集和验证集的要求。[align=center] [img=,467,301]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151608_01_1626619_3.png[/img][/align][align=center]图2 样品主成分得分图[/align]3.4 光谱预处理的结果建模过程中,分别采用各种方法对光谱数据进行预处理,包括标准化(Auto scale)、均值中心化(Mean Center)、一阶导数(First Derivative,FD)、SG13点平滑、二阶导数(Second Derivative,SD)等处理方法,以RMSEP作为评价模型的参数,通过对比预处理后的建模结果,选出最合适的预处理方法。表1列出了预处理后各模型的评价参数,通过比对,可以较直观的选出一阶导数SG13点平滑和Mean Center的组合为最佳预处理方法。图3所示为用经过一阶导数SG13点平滑和Mean Center 预处理后的光谱所建立的模型的结果,从图3中可以看出,建模效果较好,预测能力较高,Rc2=0.994,Rp2=0.986,RMSEC=0.1993%,RMSEP=0.2585%,RMSECV=0.2518%。[align=center]表1 不同预处理后各模型参数[/align][align=center][img=,629,241]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151613_01_1626619_3.png[/img][/align][align=left]FD+SG:一阶导数+SG13点平滑[/align][align=left]SD+SG:二阶导数+SG13点平滑[/align][align=center][img=,572,305]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151616_01_1626619_3.png[/img][/align][align=center]图3 一阶导数+SG平滑+ Mean Center[/align]3.5 光谱区间的选择结果通过筛选光谱区间,可以选择与样品白蛋白含量相关性大的光谱变量进行建模,去掉大量无关信息,减少模型的计算量,使得模型的效果更好。本实验采用iPLS进行变量的选择。将光谱进行SG13点平滑+一阶导数+ Mean Center预处理后,分别采用Forward iPLS和Reverse iPLS方法选择最佳的光谱区间,改变窗口宽度,分别选择最佳变量,以RMSECV为标准选择谱区。3.5.1Forward iPLS选择波段采用FiPLS的方法以RMSECV为标准选取最佳的光谱区间,分别选择50、100、200个变量进行自动选择,如表2所示窗口宽度为100个变量时建模结果较佳,结果图4所示。[align=center]表2 Forward iPLS结果[/align] [align=center][img=,645,163]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151618_01_1626619_3.png[/img][/align][align=center][img=,517,246]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151619_01_1626619_3.png[/img][/align][align=center]图4 Forward iPLS波段结果图[/align]由图4中可以看出,绿色部分为建模的波段,图5为建模预测结果图。[align=center][img=,551,291]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151620_01_1626619_3.png[/img] [/align][align=center]图5 Forward iPLS建模结果图[/align]3.5.2 Reverse iPLS选择波段采用Reverse iPLS的方法选取最佳的光谱区间,同样,分别选择50、100、200个变量进行自动选择,如表3所示窗口宽度为50个变量时建模结果较佳,波段选择结果如图6所示。[align=center]表3 Reverse iPLS结果[/align][align=center][img=,652,456]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151622_01_1626619_3.png[/img][/align] [align=center]图6 Reserve iPLS 选波段结果图[/align]如图6中所示,其中绿色部分为建模波段,图7为预测结果。[align=center][img=,520,228]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151624_01_1626619_3.png[/img][/align][align=center]图7 Reserve iPLS 建模结果图[/align]通过采用Forward iPLS和Reservei PLS波段选择方法建立PLSR模型,经过两种方法中选择的最优变量的对比(见表4),选择窗口宽度为100变量的Forward iPLS变量选择方法建立的模型最佳。最终建立的PLSR模型结果:模型的参数为Rc2=0.997,Rp2=0.987,均方根误差RMSEC=0.1394%,RMSEP=0.2560%,RMSECV= 0.1831%,建模结果较好。[align=center]表4不同变量选择方法的建模结果[/align][align=center][img=,641,142]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151629_01_1626619_3.png[/img][/align]3.6 一级数据与预测值比较对16个验证集样品的传统方法获得的蛋白含量和NIRS蛋白含量预测值进行偏差分析,结果见表5所示。蛋白含量一级数据和预测值的平均偏差和相对平均偏差的计算公式见式1和式2,蛋白含量NIRS的预测值和一级数据间的平均偏差为0.17,相对平均偏差为0.81,两者都较低,说明了NIRS和传统的凯氏定氮法结果相差较小,表明NIRS用于蛋白含量测定的准确性和可靠性。[align=center][img=,372,89]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151631_01_1626619_3.png[/img][/align]式中yi, actual为传统凯氏定氮方法得到的一级数据值,yi, predicted为NIRS得到的预测值,n为验证集样品数量。[align=center]表5 验证集样品方法结果比较表[/align][align=center][img=,585,86]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151632_01_1626619_3.png[/img][/align]3.7 预测值的精密度通过重复测量光谱计算,建立的蛋白含量校正模型的预测精密度。随机选取验证集样品中的1号、15号、35号、42号和47号样品,每个样品重复测量10次,然后采用建立的蛋白含量模型采集以上样品的光谱,得到样品的预测值。然后计算每个样品预测值的平均值、标准偏差和相对标准偏差,用这些指标来表示预测的精密度,结果见表6。如表中所示, RSD值均在1.0%以下,远远低于5.0%,证明了模型的精密度良好。[align=center]表6 模型精密度考察结果[/align][align=center][img=,584,394]http://ng1.17img.cn/bbsfiles/images/2017/09/201709151636_01_1626619_3.png[/img][/align]4结论和讨论本研究建立了人血白蛋白生产过程中蛋白含量测定的近红外定量模型,用于人血白蛋白原液蛋白质含量的测定,为下一步原液的生产配制提高依据。首先,取生产过程中的样品17个,用凯氏定氮法测得各个样品的蛋白含量,然后在实验室条件下,用生理盐水配制成49个不同浓度的蛋白样品。对49个样品进行[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的采集,然后对样品进行校正集和验证集的划分,对光谱进行预处理方法和不同的变量选择方法进行了考察;采用Kennard-Stone(K-S)分类的算法,按照2:1的比例进行样品集的划分,优先选出Mean Center +一阶导数SG13点平滑的预处理方法,并采用窗口宽度为100变量的Forward iPLS变量选择方法选出变量区间,最终建立最佳的近红外定量模型。最终建立的PLSR模型结果:Rc2=0.997,Rp2=0.987,均方根误差RMSEC=0.1394%,RMSEP=0.2560%,RMSECV= 0.1831%。除此之外,对模型进行了重复性考察,从结果可知模型具有较好的重复性。在模型的建立中,选用Kennard-Stone(K-S)分类的算法进行样品集的划分,通过PCA分析得到具有代表性的校正集和验证集样品。在预处理方法的选择中,分别选用Autoscale、Mean Center、SG平滑一阶导数以及各预处理方法的组合进行预处理方法的考察,其中SG平滑中,不同的窗口宽度会对平滑产生不同的效果,窗口宽度越宽平滑效果越好,但也会丢掉有用的信息,经过考察选择13点平滑时结果较佳。参考文献吴清, 周法根. 脑梗死治疗中白蛋白应用价值的探讨 . 心脑血管病防治, 2005, 5(2): 49-50.王华平, 米宇俊. 人血白蛋白治疗肾综合征出血热低血压休克患者疗效观察 . 医师进修杂志, 2001, 24(8):20-21.郑红光, 杨志藩, 关欣. 静脉输注人血白蛋白对肾病综合征的正负临窗效应观察 . 中国实用内科杂志, 2003, 23(1):25-27.刘丽萍. 人血白蛋白在肝硬化资料中的应用 . 中国医院用药评价与分析, 2013, 13(5):388-390.常花蕾, 史涛. 人血白蛋白临床不合理应用及改进措施 . 中国药物应用与监测, 2014, 11(1): 52-54.孙世光, 余明莲, 王建民, 张国辉. 人血白蛋白的临床应用误区及其对策 .解放军药学学报, 2009, 25(4):366-368.
[font=宋体][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]定量分析技术在对样品成分含量进行快速无损检测前,需要利用化学计量学方法建立样品成分与[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]之间的相关关系,称之为校正模型。合理可靠的校正模型建立需要大量具有代表性的样品参与,称之为校正样品,其样品分布范围要广,尽可能包含待分析样品的范围。因此,校正样品的作用主要为建模提供代表性的样品,使建立的模型合理可靠。[/font]
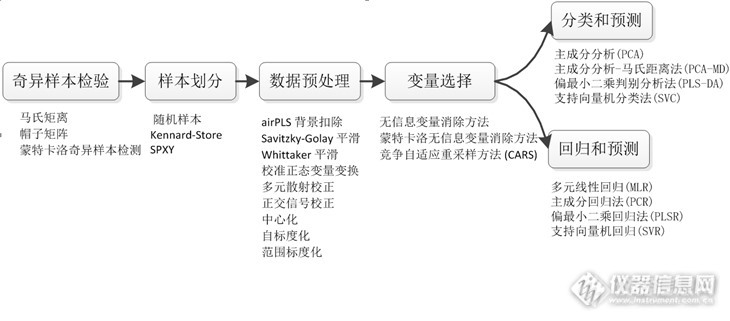
化学计量学建模步骤 梁逸曾教授在Modern Scietific Instruments 1998里的《化学计量学》一文中把化学计量学概括为,"化学计量学运用数学、统计学、计算机科学、以及其他相关学科的理论与方法,优化化学量测过程,并从化学量测数据中最大限度地获取有用的化学信息,可以说是一门化学量测的基础理论与方法学"。 从定义可以了解到,化学计量学主要是帮助我们从各种化学量测手段即不同的仪器获得的数据转化为有用的信息,这些有用的化学信息才是用户终极目标。故化学计量学在整个化学量测过程中起到至关重要的作用,而最终硬件结合软件的运用才可以最大化化学测量仪器的作用。 随着现代的仪器的发展,量测仪器获得的数据日趋复杂,从单变量到多变量,从一维到多维的发展,还有很多其他干扰因子的影响,化学计量学也变成了一个复杂的建模过程,而不是简单的化学方程式可以解决的。 一般我们建立一个化学计量学模型,我们要求模型稳健、可靠和精度高。能满足这些要求已经很不简单了,因为数据中不可避免存在的噪音、背景、漂移、颗粒大小影响。下面通过分子光谱的建模过程进行讲解:如下图所示,是整个建模过程和所用到的经典方法http://ng1.17img.cn/bbsfiles/images/2013/08/201308200859_458687_2761650_3.png 建模之前血建模之前需要对偏离整体的一些奇异样本进行剔除以保证模型的稳健性;为了检验模型的有效性应该对样本划分为训练集和预测集需要的样本划分的方法;数据中不可避免存在的噪声、背景、漂移、颗粒大小影响等问题或者多元校正方法中需要的标度化方法等需要有数据预处理方法;为建立稳健和更加简洁的模型中需要的变量选择的方法;最终是为预测未知物中感兴趣的指标的回归和对未知物类别归属的多元校正方法。 简单的来说可以这样理解每个建模的步骤,奇异样本检验,是看在整个建模的样本中有没有坏的样本,如果坏的样本进入建模集,会使得模型失真;而样本划分是为把数据分为建模子集和预测子集,预测子集是用来检测模型建立的好坏的;数据预处理就是解决仪器的不理想不可避免的一些随机误差的影响;变量选择是提取特征,使得模型更加清晰;分类是模式识别,如检测真假,或检测类别的归属等;回归是定量化学信息的含量等。 如果对图中算法感兴趣的,算法详细的介绍在附件里,请查阅,若有疑问可以一起交流探讨。
【网络讲座】ADMET性质预测及建模软件ADMET Predictor在药物研发中的应用http://www.pharmogo.com/upload/%E7%AB%8B%E5%8D%B3%E6%8A%A5%E5%90%8D(10).png【内容】计算机模拟通过已有的实验数据及自身的算法,可快速预测药物的吸收、分布、代谢、毒理性质。美国Simulations Plus公司开发的ADMET Predictor软件,现已在国内外的药品监管部门(FDA, CFDA, EMA、EPA等)、各制药企业(罗氏、诺华、礼来、药明康德等)、研究单位(中国科学院、上海药物所、协和药物所、军科院、上海医工院、中国药科大学、上海中医药大学等)得到了广泛的应用,为他们的药物研发工作提供了强有力的技术支持。本次网络会议将向您详细展示ADMET Predictor现有的143个模型预测的功能;介绍如何通过软件预测为药物设计、筛选过程提供帮助;讲解采用该软件的自建模型功能快速搭建属于您自己的QSAR模型。期待通过本次软件的功能介绍和应用案例演示,能让您更好地熟悉这款软件,并将其用于您日常的科研工作中。在这盛夏的午后,期待您的参与!主题ADMET性质预测及建模软件ADMET Predictor在药物研发中的应用时间2014年8月21日 (周四) 下午3:00-4:30主办方上海凡默谷主讲人陈涛、李平 产品经理【关于ADMET Predictor】:点击了解详情全球领先的药物ADME/Tox性质预测软件 FDA、CFDA、美国环保署EPA、欧盟化学品管理局ECHA等法规部门长期信赖的ADMET预测软件 TOP 50制药企业,学术单位运用最广的ADMET预测软件只需输入化学结构式,即可快速准确地预测理化性质、吸收、分布、代谢、排泄及毒性等性质,还可利用已有的数据,通ADMETPredictor搭建高质量的QSPR预测模型。如需了解更多信息,请联系我们:电话:021-50510193;邮箱:market@pharmogo.com;客服QQ:1114996120http://www.pharmogo.com/upload/QQ%E5%9B%BE%E7%89%8720140604144550.jpg加入微信,更多资讯
在线的近红外分析仪,测量工艺管道里面的液体成分(2种成分),必须要建模吗?建模是什么意思呢?我听朋友介绍,建模时,工程师在要在现场呆1-2年的时间,真的如此吗?在线近红外的价格大致在什么价格?(像测2种比较简单的成分)
使用unscrambler进行建模,光谱数据需要jcamp-dx格式,但是我的光谱数据是excel格式的,请问大神们有什么方法转换吗,我用的是海洋光学的仪器,软件保存jcamp-dx格式出来时jdx形式的,无法用软件打开,请问该怎么办
http://ng1.17img.cn/bbsfiles/images/2014/08/201408151009_510401_2864659_3.bmp采用 the unscrambler 建模,回归后出现的这个图,请问这是怎么回事啊?麻烦各位大神给解释一下,非常感谢!!
请问国内有没有关于核磁共振谱化学分析建模的讲座,通常建模采用什么软件?
【网络讲座】ADMET性质预测及建模软件ADMET Predictor在药物研发中的应用http://www.pharmogo.com/upload/%E7%AB%8B%E5%8D%B3%E6%8A%A5%E5%90%8D(10).png 【内容】计算机模拟通过已有的实验数据及自身的算法,可快速预测药物的吸收、分布、代谢、毒理性质。美国Simulations Plus公司开发的ADMET Predictor软件,现已在国内外的药品监管部门(FDA, CFDA, EMA、EPA等)、各制药企业(罗氏、诺华、礼来、药明康德等)、研究单位(中国科学院、上海药物所、协和药物所、军科院、上海医工院、中国药科大学、上海中医药大学等)得到了广泛的应用,为他们的药物研发工作提供了强有力的技术支持。本次网络会议将向您详细展示ADMET Predictor现有的143个模型预测的功能;介绍如何通过软件预测为药物设计、筛选过程提供帮助;讲解采用该软件的自建模型功能快速搭建属于您自己的QSAR模型。期待通过本次软件的功能介绍和应用案例演示,能让您更好地熟悉这款软件,并将其用于您日常的科研工作中。在这盛夏的午后,期待您的参与!主题ADMET性质预测及建模软件ADMET Predictor在药物研发中的应用时间2014年8月21日 (周四) 下午3:00-4:30主办方上海凡默谷主讲人陈涛、李平 产品经理 【关于ADMET Predictor】:点击了解详情全球领先的药物ADME/Tox性质预测软件 FDA、CFDA、美国环保署EPA、欧盟化学品管理局ECHA等法规部门长期信赖的ADMET预测软件 TOP 50制药企业,学术单位运用最广的ADMET预测软件只需输入化学结构式,即可快速准确地预测理化性质、吸收、分布、代谢、排泄及毒性等性质,还可利用已有的数据,通ADMETPredictor搭建高质量的QSPR预测模型。如需了解更多信息,请联系我们:电话:021-50510193;邮箱:market@pharmogo.com;客服QQ:1114996120http://www.pharmogo.com/upload/QQ%E5%9B%BE%E7%89%8720140604144550.jpg 加入微信,更多资讯
各位,天冷了,要注意保暖呀。有个问题请教下,对于建模中的校正标样,一直很模糊,不知道其在建模中起什么作用,还请指教。谢了!
书上说:只有建模后才能了解建模所需变量数,从而进一步了解建模所需校正集样品数。如果建模需要3个以下(包括3个)的变量,那么去掉异常点后,校正集至少应有24个样品。我看的有点糊涂,既然先建模才能确定样品数,那我之前应该用多少样品建模?!
常用材料建模软件中,哪一个更易短期掌握及使用方便,解决常见材料建模问题。
[font=宋体]随着样本数量的增多,单个样本增加引起的模型提升效果越来越小。当样本数量超过一定的限度后,建模算法可能成为限制模型进一步优化的瓶颈,此时选择更加复杂的算法可能获得进一步的模型提升。但是样本量增加,可能增加实验成本和计算成本,需要综合考虑成本和收益,以确定合适的建模样本。[/font]
[em04] 哪位高手帮忙一下啊? 我刚接触近红外分析仪,想知道,没有建立分析模型的情况下,直接做样,再建模型分析数据 还是先把模型建立好,再做样呢?
近红外测起来比较简单,但是关于建模比较复杂,我想求助一些关于建立模型过程的资料
近红外真那么好吗?如果没其他检测设备的检测结果建模型,岂不成摆设了。
[font=宋体][font=宋体]建模所需的样品数量与样品情况以及光谱与性质数学关系的复杂程度有关。石化样品尤其是生产过程中的样品往往比较类似,特别在生产比较稳定,原料和操作没有变化的时候,这种情况下应当再多收集一些样品,拓宽性质变化范围。光谱与性质的数学关系比较复杂时,需要更多的样品来解释光谱与性质的关系。应用多元校正方法建立油料样品的近红外模型,对建模的样品数量要求,读者可参考[/font][font=Times New Roman]GB/T 29858-2013[/font][font=宋体]。[/font][/font]
很希望对matlab建模应用到近红外光谱的朋友可以互相交流讨论下,聊下matlab建模的那点事儿。共同学习
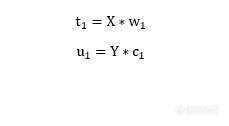
[align=center][b]基于PLS算法的实验数据建模方法[/b][/align][align=center]谢佩章(南京质检NQI)[/align][align=left]摘要:检验检测过程中产生的大量数据,由于其本质是非线性的,传统的拟合方法具有一定的局限性。本文所提出的PLS算法基于数据驱动模型的方法,其本质是数学拟合方法,不依赖于过程机理,同时能够处理各类非线性数据,因此适用于各类检验检测数据的建模。[/align]关键词:PLS, 数据驱动模型,非线性1 背景 检验检测过程中产生的数据通常存在着内部机理复杂、变量众多、过程存在干扰、非线性等问题,难以建立精确的机理模型,这就使得很多基于机理的建模方法失效或者基本失效。 模型建立的方法目前主要有三类:基于机理建模的方法、基于知识模型的方法以及基于数据驱动的方法。其中基于机理模型的方法通过过程所遵循的物理、化学规律建立关键参数与其他可测变量之间的数学方程,其模型准确性较高,但是建立模型的基本条件是对生产过程的机理有比较深入的认识。基于知识模型的方法对生产过程的实际操作经验和定性分析等结果的归纳总结,而获得诸如专家系统形成的知识模型,这种模型具有形式简单,易于理解和在线实现方便的特点,但精度较低,知识规则提取困难等缺点。基于数据驱动模型的方法通过采集过程中产生的丰富数据,根据多元统计分析、人工智能等理论,建立关键参数变量与其他可测变量的统计回归模型,具有不依赖于过程机理、较高的精确性等优点,然而由于其数据具有非线性、高维等特点,使得其建模方法较为复杂且不易理解等缺点。比较三种建模方法,在检验检测过程中,由于多数实验机理较为复杂,且非线性、干扰较大,不易于使用机理建模及知识建模,特别适合于数据驱动模型方法。 数据驱动建模方法,主要有两类,一类是基于数理统计的方法,另一类是非统计建模的方法,目前非统计建模的方法主要有神经网络等现代模型方法,统计类建模历史较为悠久,对于线性方法具有较强的适应性。对于多变量数据,由于其各参数间存在着关联及共线性等问题,为了更好的解决这些问题,多元统计方法在不断的发展,如PCA-主元分析、PLS-偏最小二乘算法、SVM-支持向量机、小波分析、独立主元分析等。这些方法在建模方面得到了很好的应用。2 偏最小二乘方法(PLS) 偏最小二乘方法采用成分提取的方法,在抽取自变量特征信息的同时,也抽取拟合参数的特征信息,并以最大化自变量与拟合参数特征信息的相关性为目标。[img=,670,611]http://ng1.17img.cn/bbsfiles/images/2017/08/201708251725_01_2984502_3.jpg[/img][img=,690,577]http://ng1.17img.cn/bbsfiles/images/2017/08/201708251726_01_2984502_3.jpg[/img][img=,621,529]http://ng1.17img.cn/bbsfiles/images/2017/08/201708251727_01_2984502_3.jpg[/img]3. 总结 偏最小二乘算法对于非线性、难以使用机理建模或者知识建模、参数间具有耦合性的数据,具有良好的拟合能力,在数据分析方面有一定的作用。
foss建模软件有winisi有中文版吗 英文版用着好痛苦
以前没有接触过建模 不知道具体流程 求教
我现在正在做一些有关近红外数学模型的工作,了解到很多建模的方法,但是郁闷的是不知道怎么来选择建模需要的波长,请各位高手前辈指点!谢谢!
近红外无损检测建模时会遇到对模型建立的方法选择,其中有一个是散射及标准化处理方法的选择,根据电脑软件的分析,我的建模结果是不做散射及标准化处理得到的R值最大,请问大家下,这个不做散射及标准化处理的好处是什么,或者说不对光谱做处理对模型有哪些好处呢
看了[b]ruojun[/b]在[url]http://bbs.instrument.com.cn/shtml/20100318/2452915/index.shtml[/url]中的回帖原文由 [b]闲鹤野云(ruojun)[/b] 发表:原文由 [b]睿武孝文(chaifayong)[/b] 发表:我可不这样认为,定量是需要经典分析方法来协助建立模型,但这样无形中也加大了工作量啊。而定性就不一样了,只要收集合适一定的样品,采集完[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url],也就直接可以建立模型了,或者可以直接像其他光谱方法一样,去做定性鉴别啊。其实两者都不容易,关键是采集的模型的次数一定要多,以减少随即误差。我用便携式设备定型建模最少一个样品要扫描6次。三次的模型就不太好。6次很好。感觉扫描次数对建模影响很大。我之前一直都是取1次采集的光谱建模的,呜呜~~忧虑ing~
Bruker MPA近红外建模中,决定系数"R方"与哪些因素有关?
近红外小白求有关matlab近红外的变量筛选和建模的教程资料,有偿,价格可以商量。有意的加qq:2417631550
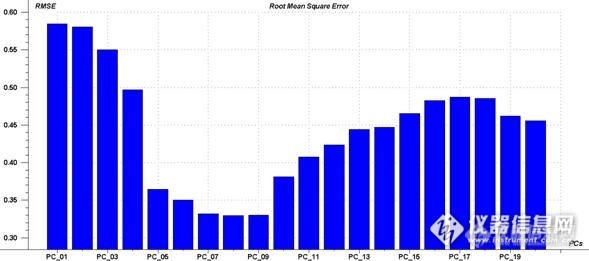
正在用the unscrambler9.8学习建模,但是不知道如何确定主成分数(PC?),还有在软件里如何做RMSEV随PCs变化图?希望各位大神指导下,不胜感激。。http://ng1.17img.cn/bbsfiles/images/2014/04/201404210954_496865_2864659_3.jpg还有建模过程中,剔除异常点进行recalculate without marked或不剔除异常点只做recalculate without marked的时候,PC值会变化,这又是怎么回事呢?
一般来讲,如果使用pls建模得到的预测结果与测量值相关度在0.97左右是不是可以说使用呢,这样的建模效果能否说是成功呢?因为我看到很多材料上这个相关度在0.998左右,所以心里没有底。请大牛指导,不胜感谢。 另外,一般对于[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的预处理方法除了导数法以外,还有别的么?谢谢。
本人研究生期间主要做的就是近红外的建模和模型分析,但不知道毕业后找啥工作?







 我要推广仪器
我要推广仪器
 下载APP
下载APP