我知道直读光谱仪由五个部分组成:1)光源系统 为样品提供能量2)真空系统 为短波元素提供真空环境3)色散系统 分离开不同的波长4)电子系统 测量每种波长的发光强度5)计算机 处理测量值和控制仪器 像问问ICP光谱是有那几部分组成,以及各自的作用?
[url=https://insevent.instrument.com.cn/t/Mp]气相色谱[/url]有几部分组成?
农残单一标准物质如果出几个峰(峰面积都差不多大),特备是几个峰基线分离而且保留时间差5、6分钟,使用瓦里安GC450气相gcms工作站软件(气相质谱通用的)分组时必须要输入各个峰的浓度(只知道总浓度),如何设置???包括岛津的lcsolution软件也是一样,分组时计算方法文件也必须输入个峰浓度,安捷伦软件说明也没有看到详细的说明各异构体有人采用其中一个峰来计算,对于不同农药其实异构体含量是不同的,假定各异构体相应相同(一般也差不多),用总面积其实更准确看了很久对分组情况软件都没有详细的说明,这几种软件是怎么设置的???
干洗剂由哪些成分组成?对人体有危害吗?
对于安捷伦[url=https://insevent.instrument.com.cn/t/bp][color=#3333ff]气质[/color][/url]工作站,某些化合物有短链和直链,需要峰面积单个积,然后分组加和形式定量,如何软件操作,感谢大家
最近在做5009.35-2023食品中合成着色剂的测定,其中亮蓝有两个峰,请问怎样利用变色龙软件对这两个峰的峰面积加和或者峰分组,从而做数据处理。
一般光电比色计主要由哪几个部分组成?滤光片的作用是什么?
卡尔·费休库仑法水分测定仪的阳极液和阴极液大致由哪些有效成分组成?如何判断需要更换电解液?
各位本人五一买了款新疆和田玉,用EDX定性定量测试,发现有以下几个元素:Si,Ca,K,Fe.想请教各位下玉是什么成分组成的,我买的玉是不是假货,还有EDX能不能测试这些矿石只类。
市面上疏通下水道的“疏通剂”是什么成分组成的?
[sup]?我指的是测奶粉中的营养元素如钾钠钙镁 铜锰 铁锌磷这些,各公司既有分组配标的,也有配所有元素混合标液的,为啥需要分组配制混标?难道不是混合的标液更接近于真实样品的组成么?[/sup]
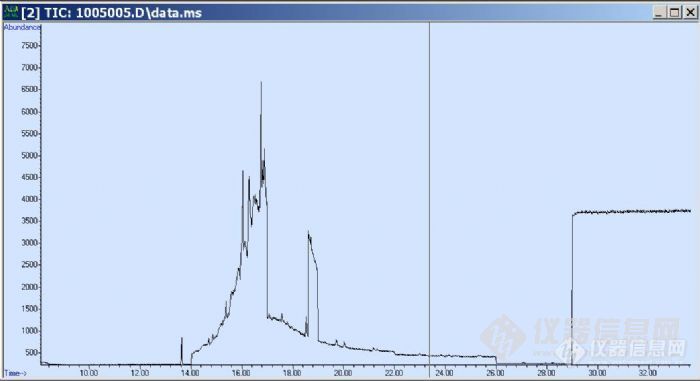
我做菊酯类农药时,进了一个0.5ppm的混标,利用sim分组扫描,得出来的图谱基线不是平稳的,却是按分组的时间呈现阶梯型的,一级级的很难看,请问是什么原因呢?大家在做sim分组扫描会不会遇到这种问题啊?还有,我上传的两张图片,程序升温的条件基本是一样的,只是第一张最后的保留时间我设了18分钟,第二张是12分钟,但是中间14到22分钟这一段,基线漂移明显很不一样,那一段的升温程序是一致的,但是为啥会有这么大的区别呢?谢谢~~[img]http://ng1.17img.cn/bbsfiles/images/2010/05/201005120947_217654_1934505_3.jpg[/img][img]http://ng1.17img.cn/bbsfiles/images/2010/05/201005120948_217656_1934505_3.jpg[/img]
色谱仪器依据保留时间来定性,根据保留时间将目标物分组;如:NY761质谱仪器依据特征离子来定性,为什么还要依据保留时间来分组?如:GB19649
用气质做VOCsim扫描大家是怎么进行分组的?
[font=宋体][font=宋体]相较于传统分析化学方法,结合化学计量学的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析更容易出现过拟合现象。因此对化学计量模型的验证尤为重要。在建模之前通常需要将采集的样本光谱和参考值分为校正集([/font][font=Times New Roman]calibrationset[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体][font=宋体]和验证集([/font][font=Times New Roman]validationset[/font][font=宋体])。前者主要用于建立多元校正或化学模式识别模型,后者用来验证所建立模型的预测性能。通常校正集和验证集中样本个数的划分比例介于[/font][font=Times New Roman]0[/font][/font][font='Times New Roman'].5~0.8[/font][font=宋体]之间(两者的样本数量具体根据样本、模型的复杂程度来定)。常见的样本分组方法包括:随机算法、[/font][font='Times New Roman']Kennard-Stone [font=宋体]([/font][/font][font=宋体][font=Times New Roman]KS[/font][font=宋体])算法、光谱[/font][font=Times New Roman]-[/font][font=宋体]理化值共生距离算法([/font][font=Times New Roman]S[/font][/font][font='Times New Roman']ample set [/font][font=宋体][font=Times New Roman]p[/font][/font][font='Times New Roman']artitioning based on joint x[/font][font=宋体][font=Times New Roman]-[/font][/font][font='Times New Roman']y distances[/font][font=宋体][font=Times New Roman], SPXY[/font][/font][font='Times New Roman'][font=宋体])[/font][/font][font=宋体]等。[/font][b][b][font=宋体]一、[/font][font=宋体]随机分组方法[/font][/b][/b][font=宋体]随机分组方法是从数据集中随机选择一部分样本作为校正集,其余样本作为预测集。[/font][font=宋体]其中,随机分组算法的选择过程具有不确定性,在样品量较少或者建模效果波动较大时难以建立高效的模型。[/font][font=宋体]随机分组不能保证每次选择的校正集样本都具有代表性,因而在验证新提出方法的性能时,为了保证模型性能不受分组方法的干扰,常采用多次随机分组方法进行综合评价。即将数据多次采用随机分组的方法进行分组,对校正集多次建模,计算模型预测结果的平均值。该预测结果不受数据分组的影响,能较好体现模型的性能。[/font][b][b][font=宋体]二、[/font][font=宋体]KS分组方法[/font][/b][/b][font=宋体][font=Times New Roman]KS[/font][font=宋体]算法由[/font][/font][font='Times New Roman']Kennard[font=宋体]和[/font][font=Times New Roman]Stone[/font][font=宋体]提出[/font][/font][sup][font=宋体][font=Times New Roman][[/font][/font][/sup][sup][font='Times New Roman']2[/font][/sup][sup][font=宋体][font=Times New Roman]][/font][/font][/sup][font=宋体],是一种基于光谱距离迭代选择样本的方法,旨在选择出覆盖范围广,且均匀分布的样本集。首先,选择一个初始样本,之后每一步都选择与已选样本光谱距离(通常为欧氏距离或者马氏距离)最远的一个样本,直到选择出的样本达到预设的数量为止。[/font][b][b][font=宋体]三、[/font][font=宋体]SPXY分组方法[/font][/b][/b][font=宋体][font=Times New Roman]KS[/font][font=宋体]算法仅考虑了光谱的信息,没有考虑参考值的影响。当待测组分含量较低时,若光谱特征不显著,采用[/font][font=Times New Roman]KS[/font][font=宋体]方法可能不会得到满意的校正集样本。[/font][font=Times New Roman]Galvao[/font][font=宋体]等[/font][/font][sup][font='Times New Roman'][3][/font][/sup][font=宋体][font=宋体]在[/font][font=Times New Roman]KS[/font][font=宋体]方法的基础上提出了光谱[/font][font=Times New Roman]-[/font][font=宋体]理化值共生距离算法([/font][font=Times New Roman]SPXY[/font][font=宋体])。该方法兼顾参考值和光谱距离,从而保证选择的样本的光谱和参考值都覆盖较大的范围并且均匀分布。[/font][font=Times New Roman]SPXY[/font][font=宋体]方法的逐步选择过程与[/font][font=Times New Roman]KS[/font][font=宋体]方法相同,只是在计算样本[/font][/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font=宋体]和样品[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font=宋体][font=宋体]之间的距离时,采用了同时考虑光谱[/font][font=Times New Roman]x[/font][font=宋体]和目标参考值[/font][font=Times New Roman]y[/font][font=宋体]的新的距离定义[/font][font=Times New Roman]d[/font][/font][sub][font='Times New Roman']xy[/font][/sub][font=宋体][font=Times New Roman]([/font][/font][i][font='Times New Roman']i[/font][/i][font=宋体][font=Times New Roman],[/font][/font][i][font='Times New Roman']j[/font][/i][font=宋体][font=Times New Roman])[/font][font=宋体]。[/font][/font][align=center][i][font='Times New Roman']d[/font][sub][font='Times New Roman']xy[/font][/sub][/i][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[font=宋体]=[/font][/font][img=,262,49]https://ng1.17img.cn/bbsfiles/images/2024/06/202406281001238984_1952_4070220_3.png!w262x49.jpg[/img][font='Times New Roman'][font=宋体],[/font][/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'][font=宋体],[/font][/font][i][font='Times New Roman']j[/font][/i][font=宋体]∈[/font][font='Times New Roman'][1,...,[/font][i][font='Times New Roman']z[/font][/i][font='Times New Roman']][/font][font=宋体] [font=Times New Roman](5-1)[/font][/font][/align][font=宋体]式中,[/font][font='Times New Roman']d[/font][sub][font='Times New Roman']x[/font][/sub][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[/font][font=宋体][font=宋体]是以光谱[/font][font=Times New Roman]x[/font][font=宋体]为特征参数计算的样本[/font][/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font=宋体]和[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font=宋体]之间的欧式距离,[/font][font='Times New Roman']d[/font][sub][font='Times New Roman']y[/font][/sub][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[/font][font=宋体]是以目标参考值[/font][i][font=宋体][font=Times New Roman]y[/font][/font][/i][font=宋体]为特征参数计算的样本[/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font=宋体]和[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font=宋体]之间的距离,[/font][i][font='Times New Roman']z[/font][/i][font=宋体]是样品的总数目。[/font][font='Times New Roman'][font=宋体]为了对[/font]x[font=宋体]和[/font][font=Times New Roman]y[/font][font=宋体]空间中的样本分布赋予同等重要性,距离[/font][font=Times New Roman]d[/font][/font][sub][font='Times New Roman']x[/font][/sub][font='Times New Roman']([/font][i][font='Times New Roman']i[/font][/i][font='Times New Roman'],[/font][i][font='Times New Roman']j[/font][/i][font='Times New Roman'])[font=宋体]和[/font][font=Times New Roman]d[/font][/font][sub][font='Times New Roman']y[/font][/sub][font='Times New Roman']([/font][i][font=宋体][font=Times New Roman]i[/font][/font][/i][font='Times New Roman'],[/font][i][font=宋体][font=Times New Roman]j[/font][/font][/i][font='Times New Roman'])[font=宋体]除以它们在数据集中的最大值[/font][/font][font=宋体]进行标准化处理。[/font][b][b][font=宋体]四、最优[/font][font=宋体]K[/font][font=宋体]相异性方法[/font][/b][/b][font=宋体][font=宋体]在选择校正样本时,需要同时考虑样本的代表性和多样化,所谓的代表性是所选样本要尽可能反映整个数据集中所有样本的属性,而多样化是指所选样本之间的差异应尽可能大,彼此容易区分。最优[/font][font=Times New Roman]K[/font][font=宋体]相异性方法([/font][font=Times New Roman]Optimizable K-[/font][/font][font='Times New Roman']d[/font][font=宋体][font=Times New Roman]issimilarity [/font][/font][font='Times New Roman']s[/font][font=宋体][font=Times New Roman]election[/font][font=宋体],[/font][font=Times New Roman]OptiSim[/font][font=宋体])是一种能选择既有代表性又兼顾多样化样本的方法[/font][/font][sup][font='Times New Roman'][4][/font][/sup][font=宋体][font=宋体]。最优[/font][font=Times New Roman]K[/font][font=宋体]相异性算法涉及三个参数:[/font][font=Times New Roman]K[/font][font=宋体]定义为每一次迭代中子样本集的大小;[/font][font=Times New Roman]R[/font][font=宋体]定义为一个有效的候选样本与任何一个已经选定的样本之间所允许的最小相似性;[/font][font=Times New Roman]M[/font][font=宋体]为所选的代表性子集样本的总数目。通过[/font][font=Times New Roman]K[/font][font=宋体]值可控制所选样本代表性和多样性之间的平衡,低的[/font][font=Times New Roman]K[/font][font=宋体]值能选出更具代表性的样本,较大[/font][font=Times New Roman]K[/font][font=宋体]值能选出更多样化的样本。[/font][/font]

有网友问,农药如何分组?http://ng1.17img.cn/bbsfiles/images/2016/05/201605232135_594449_1645480_3.jpg
在学习n-2010色谱工作站和其他工作站时发现有一个分组计算的工能不知道它具体有什么意义呢?请大虾给详细讲下 谢谢!
目前公司要进行2班倒。在人员分组搭配的时候,我发现男女搭配很轻松,目前实验已经搞成了两对了。当时有时感觉效率低了,请教有何高招啊!
谁有这方面的资料?大家都说说自己的标准溶液的分组情况~~~那些元素分在一起比较好?W是不是在酸中要沉淀~~
[size=4]有奖抢答,第一个全面答对的[color=#d40a00][color=#000000]奖励[/color]15积分[/color],参与者也都有一定的积分奖励哦![color=#013add][b]问题:[/b][/color][/size][color=#000000][size=4][color=#013add][b]质谱仪一般是由哪几部分组成的?其各部分的作用是什么?[/b][/color][/size][/color][color=#000000][size=4][u]本系列仅供新手学习的质谱基础知识,资深专家们可以略过。[/u][/size][/color]
人的头发是什么成分组成的?
本人近期做农药的多残留分析方法,有几个问题想请教大家1 关于离子选择分组,每组的开始时间一般是在一个农药 的保留时间之前,结束在选择的几个农药的保留时间之后,这之前,是要提前多少呢?有没有规定,或者规则什么的?2 进单标的时候是不是没有必要选择离子阿,只见看看保留时间就可以了?谢谢
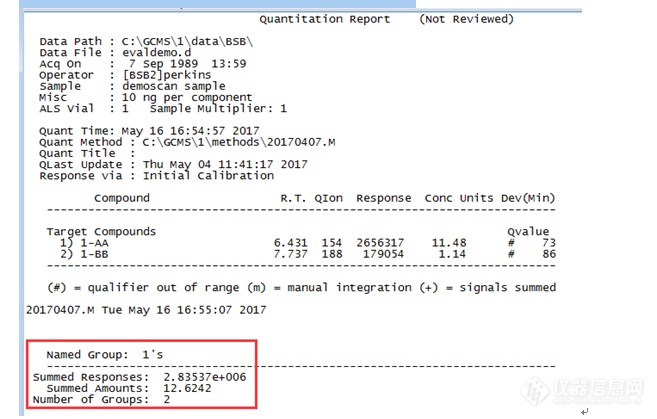
安捷伦5977[url=https://insevent.instrument.com.cn/t/bp][color=#3333ff]气质[/color][/url]MS HUNTER软件如何做峰分组定量进行菊酯类农药残留分析时,经常会遇到一个化合物有出了几个同分异构体的情形,而购买来的标准溶液却是这几个同分异构体的含量之和的浓度,比如我们常见的氯氰菊酯,氟氯氰菊酯等,通常标准物质证书上记载的也是氯氰菊酯浓度为100ug/mL,这个浓度说明了这是几个同分异构体的总浓度,这里介绍下如何使用 安捷伦5977[url=https://insevent.instrument.com.cn/t/bp][color=#3333ff]气质[/color][/url]MS HUNTER软件如何做峰分组定量的方法。1 先按照正常外标法的步骤建立好标曲(各自化合物的含量先随便输入数值),打算分到一个组的化合物在命名时需要包含共同的字段,比如都包含1,组分名分别1-AA,1-BB。2 在编辑化合物界面看到各自化合物的响应,根据响应来拆分各自的浓度应该是多少(手动计算),再修改成正确的浓度。3 在定量菜单下选中“包含化合物组的摘要报告”,输入组名称共同包含的字段(可以做多组的分组),点“确定”然后就可以看到组的含量和加和的报告。[img=,657,419]https://ng1.17img.cn/bbsfiles/images/2018/09/201809151543262756_5303_2166779_3.png!w657x419.jpg[/img]虽然这种分组定量方法还不能非常准确地对各个同分异构体进行定量(因为浓度不同,同分异构体在化合物中的比例会略有差异),但是这种分组定量的方法比手工对同分异构体的峰面积进行加和定量的方法更准确,也更简便直观了。如手动计算结果:[img=,451,60]https://ng1.17img.cn/bbsfiles/images/2018/09/201809181427487434_4359_2166779_3.png!w451x60.jpg[/img]氯氰菊酯的结果为:(863699+355335+722837+807188)*300/(30261+30292+26922+28028)/2=3568ng/g=3.6mg/kg用分组计算得出的结果为:[img=,667,125]https://ng1.17img.cn/bbsfiles/images/2018/09/201809181439420480_4903_2166779_3.png!w667x125.jpg[/img][img=,275,185]https://ng1.17img.cn/bbsfiles/images/2018/09/201809181440316810_4425_2166779_3.png!w275x185.jpg[/img][img=,329,227]https://ng1.17img.cn/bbsfiles/images/2018/09/201809181440436698_9309_2166779_3.png!w329x227.jpg[/img]分组计算的结果:(3089.19+1427.36+2422.53+2193.2)*0.001/2=4.6mg/kg从上可以看出:手动计算结果为3.6mg/kg, 分组[color=#000000]计算结果为4.6mg/kg,[/color][color=#000000]分组计算的结果相对来说更准确。[/color]版友们你们是如何对同分异构体的化合物进行定量的?欢迎讨论
必须按照761的有机磷混标分组么?因为我看卖的混标不是按照761的分组种类的?还有问一下有没有配置好按照761分组的混标么?不想自己配置了,太麻烦了还有刚开始农残测试,你们一般混标从哪里买的?单只买太贵了啊?而且有有效期
化合物A:56,44,41,57,保留时间12.4min;化合物B(内标):71,43,114,41,保留时间15.2min。SIM模式离子不分组的检测响应值低于分为两组时的响应值,且分组时2组的色谱图基线下移。请教一下,是否要分组,基线下移怎么解释?谢谢!
铁子们,求购一台自动部分组分收集器,可开票的私我谢谢
皮鞋油有哪些成分组成?对人体有哪些危害?
有二十来种有机磷农药,需要分组吗?
现在需要做邻苯二甲酸酯类,但是各个物质的定性和定量离子太多,而且出峰时间接近,各位看一下怎么离子分组好点?(第一个离子是标准中规定的定量离子。) 物质 保留时间 定量定性离子1 邻苯二甲酸二甲酯 7.6 163 77 1352 邻苯二甲酸二乙酯 8.5 149 177 1213 邻苯二甲酸二异丁酯 10.21 149 223 2054 邻苯二甲酸二丁酯 10.9 149 223 2055 邻苯二甲酸二己酯 14.68 104 149 766 邻苯二甲酸丁基苄基酯 14.61 149 91 2067 邻苯二甲酸二环己酯 16.64 149 167 838 邻苯二甲酸二苯酯 16.78 225 77 153
我有一组关于材料成分的实验数据,标准偏差比较大。我猜测这组数据其实来自两个不同的相,但是采集数据的时候这两个相从外观上无法区分,所以认为是一个相,数据也就混杂在一起了。因为数据存在波动,无法认为看出来哪些数据属于某个相。有没有什么统计方法或者软件可以对全部数据进行分析,我指定按照两个体系做统计,它就能自动对数据进行分组,然后分别得到平均值和标准偏差(一旦分组,这就很容易了)。







 我要推广仪器
我要推广仪器
 下载APP
下载APP