中国科技网讯 据物理学家组织网日前报道,美国能源部斯坦福直线加速器中心国家加速器实验室的研究人员,采用金刚石细薄片把直线加速器的相干光源转化为手术刀般更精确的工具,以探测纳米世界。改进后的激光脉冲可在X射线波长更窄频带高强度聚焦,开展以前所不能为的实验。该研究结果刊登在《自然·光子学》杂志上。 这个过程被称为“自激注入”,金刚石将激光束过滤为单一的X射线颜色,然后将其放大。研究人员可以在原子水平研究和操纵物质上有更强的能力,传送更为清晰的物质、分子和化学反应的影像。 人们谈论“自激注入”已经近15年,直到2010年斯坦福线性加速器中心成立时,才由欧洲自由电子激光器和德国电子加速器研究中心的研究人员提出,并由来自斯坦福线性加速器中心和阿贡国家实验室的工程队伍将其建立。“自激注入”可潜在地产生更高强度的X射线脉冲,显著高于目前直线加速器相干光源的性能。每个脉冲增加的强度可以用来深入探测复杂的材料,以帮助解答诸如高温超导体等特殊物质或拓扑绝缘体中复杂电子态等问题。 直线加速器相干光源通过接近光速的电子群加速激光束,用一系列磁体将其设定为“之”字路径。这将迫使电子发射X射线,聚集成亮度超过之前10亿倍的激光脉冲。如果没有“自激注入”,这些X射线激光脉冲包含的波长(或颜色)范围比较宽,无法被所有的实验使用。之前在直线加速器相干光源创造更窄波段(即更精确波段)的方法则会导致大量的强度损失。 研究人员在可产生X射线的130米长磁体的中间段安装了一片金刚石晶体,由此创建了一个精确的X射线波段,并且使直线加速器相干光源更像是“激光”。该中心物理学家黄志荣(音译)说:“如果我们完成系统的优化,并添加更多的波荡,所产生的脉冲集中的强度将达10倍之多。”目前世界各地的相关实验室已经趋之若鹜,计划将这一重要进展与自身的X射线激光设施相结合。(记者 华凌) 《科技日报》(2012-09-17 二版)
光学技术作为一种无损的检验方法,在物证的发现、记录、提取、检验、鉴定和保全等各个方面都发挥着重要的作用。刑事影像技术方向的主要任务是利用先进的光学技术获取与物证相关的影像资料,通过区分物质的方法得到物证的清晰影像以及深入挖掘能够揭示案件事实真相的物证信息。http://www.zolix.com.cn/filespath/images/20150812153905.jpg 光谱成像技术能够根据不同物质光谱特征准确记录其空间分布状态,为物证鉴定光学检验提供了将形态检验和成分检验相结合的机会。 目前公安部物证鉴定中心有关光谱成像技术的研究已获得5项国家级科研项目资助,1项部级科研项目资助。已经在“十一五"和“十二五"国家科技支撑计划实施阶段,成功实现了科研衔接和可持续性研究态势。基于以上成果及未来的发展趋势,公安部物证鉴定中心与中国工程物理研究院以及卓立汉光旗下的四川双利合谱科技有限公司联合成立多光谱成像侦查技术联合实验室,将进一步促进和推广多光谱成像技术在刑侦领域的应用。基于联合实验室的平台,将逐步的建立光谱成像测试标准以及物证光谱数据库及数据分析网络服务器。http://www.zolix.com.cn/filespath/images/20150812153808.jpg 适用范围: 通过研究证明,光谱成像技术能够应用于痕迹检验、文件检验、微量物证检验、生物物证发现等物证鉴定领域多个专业的工作中。正是由于光谱成像技术适用性强的特点,体现出这项技术深入研究的价值和推广普及的潜力。http://www.zolix.com.cn/filespath/images/20150812153829.jpg 目前,国内技术人员,应用不同波段范围、不同工作原理的光谱成像技术,针对不同检验对象,进行了大量实验研究,均已取得一定的研究进展,具体研究情况整理如下http://www.zolix.com.cn/filespath/images/20150812153847.jpg
用1999年买的美国Acton Research公司的Spectro500i光谱仪测量Ar气保护电弧等离子体的光谱分布,出现了奇怪的问题。 一年前300g/mm的光栅突然采不到光谱,不知道是什么问题。 现在用1200g/mm和2400g/mm的光栅测量Ar保护电弧200-1000nm的光谱,发现如下问题:谱线分布大体分为3段(340-500nm,510-750nm, 680-1000nm),其中680-1000nm段的谱线能够与以前测量的谱线对应,基本是正确的,但是340-500nm, 510-750nm两段测得的的谱线实际为680-1000nm段的谱线,这三段谱线的强度依次减弱,在680-750nm波段中既有该段的谱线又有906.6-1000nm的谱线。 以前正常的谱线分布(Ar150A电弧光谱分布正常.txt)和现在异常的谱线分布(Ar200A电弧光谱分布异常.txt)放在附件中。如200.000 1 1.778e+002,前面是波长,后面是强度,中间用1分开。 不知道以上2个问题是怎么造成的,希望懂光谱仪的各位帮顶一下,给点解决办法。 [img]http://www.instrument.com.cn/bbs/images/affix.gif[/img][url=http://www.instrument.com.cn/bbs/download.asp?ID=31761]光谱数据正常和异常[/url]
紫外强吸收,可见和红外波段没有很明显的吸收峰出现,用532nm波长激光激发,请问材料是否会有三光子吸收出现? 还有一个问题就是:一种材料在紫外可见红外波段范围内是否可能没有特征吸收峰出现?如果是的话,那么是为什么?先谢过了
做[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]霉变检测,运用特征提取方法获取了一些波段,如1172nm,1902nm等,看文献中都有对波段的分析,比如该波段是由哪个基团的什么运动引起的,对应于什么物质(碳水化合物,水分,油),想请教下这些东西是怎么分析出来的,或者有大牛能否帮忙分析下我的特征波段,万分感谢!
现在做实验,老板让我查一下以下气体在可见光波段的吸收谱,二氧化碳,二氧化硫,臭氧,甲烷等。我在网上找了狠多,都没有发现结果,那位大哥帮帮忙给弄一下啊,谢谢了另外,那个附图是我用NIST MS Search查到的光谱图,但是横坐标为什么没有光谱单位呢??

激光雷达可以按照所用激光器、探测技术及雷达功能等来分类。目前激光雷达中使用的激光器有二氧化碳激光器,Er:YAG激光器,Nd:YAG激光器,喇曼频移Nd:YAG激光器、GaAiAs半导体激光器、氦-氖激光器和倍频Nd:YAG激光器等。其中掺铒YAG激光波长为2微米左右,而GaAiAs激光波长则在0.8-0.904微米之间。根据探测技术的不同,激光雷达可以分为直接探测型和相干探测型两种。其中直接探测型激光雷达采用脉冲振幅调制技术(AM),且不需要干涉仪。相干探测型激光雷达可用外差干涉,零拍干涉或失调零拍干涉,相应的调谐技术分别为脉冲振幅调制,脉冲频率调制(FM)或混合调制。按照不同功能,激光雷达可分为跟踪雷达,运动目标指示雷达,流速测量雷达,风剪切探测雷达,目标识别雷达,成像雷达及振动传感雷达。激光雷达最基本的工作原理与无线电雷达没有区别,即由雷达发射系统发送一个信号,经目标反射后被接收系统收集,通过测量反射光的运行时间而确定目标的距离。至于目标的径向速度,可以由反射光的多普勒频移来确定,也可以测量两个或多个距离,并计算其变化率而求得速度,这是、也是直接探测型雷达的基本工作原理。由此可以看出,直接探测型激光雷达的基本结构与激光测距机颇为相近。相干探测型激光雷达又有单稳与双稳之分,在所谓单稳系统中,发送与接收信号共同在所谓单稳态系统中,发送与接收信号共用一个光学孔径。并由发射/接收(T/R)开头隔离。T/R开关将发射信号送往输出望远镜和发射扫描系统进行发射,信号经目标反射后进入光学扫描系统和望远镜,这时,它们起光学接收的作用。T/R开关将接收到的辐射送入光学混频器,所得拍频信号由成像系统聚焦到光敏探测器,后者将光信号变成电信号,并由高通滤波器将来自背景源的低频成分及本机振荡器所诱导的直流信号统统滤除。最后高频成分中所包含的测量信息由信号和数据处理系统检出。双稳系统的区别在于包含两套望远镜和光学扫描部件,T/R开关自然不再需要,其余部分与单稳系统的相同。美国国防部最初对激光雷达的兴趣与对微波雷达的相似,即侧重于对目标的监视、捕获、跟踪、毁伤评(SATKA)和导航。然而,由于微波雷达足以完成大部分毁伤评估和导航任务,因而导致军用激光雷达计划集中于前者不能很好完成的少量任务上,例如高精度毁伤评估,极精确的导航修正及高分辨率成像。较早出现的一种激光雷达称为“火池”,它是由美国麻省理工学院的林肯实验室投资,于60年代末研制的。70年代初,林肯实验室演示了火池雷达精确跟踪卫星,获得多普勒影像的能力。80年代进行的实验证明,这种CO2激光雷达可以穿透某些烟雾,识破伪装,远距离捕获空中目标和探测化学战剂。发展到80年代末的火池激光雷达,采用一台高稳定CO2激光振荡器作为信号源,经一台窄带CO2激光放大器放大,其频率则由单边带调制器调制。另有工作于蓝-绿波段的中功率氩离子激光与上述雷达波束复合,用于对目标进行角度跟踪,而雷达波束的功能则是收集距离――多普勒影像,实时处理并加以显示。两束波均由一个孔径为1.2M的望远镜发射并接收。据报道,美国战略防御局和麻省理工学院的研究人员于1990年3月用上述装置对一枚从弗吉尼亚大西洋海岸发射的探空火箭进行了跟踪实验。在二级点火后6分钟,火箭进入亚轨道,即爬升阶段,并抛出其有效负载,即一个形状和大小均类似于弹道导弹再入飞行器的可充气气球。该气球有气体推进器以提供与再入飞行器和诱饵的物理结构相一致的动力学特性。目标最初由L波段跟踪雷达和X波段成像雷达进行跟踪。并将这些雷达传感器取得的数据交给火池激光雷达,后者成功地获得了距离约800千米处目标的像。[~116966~][~116967~][~116968~][img]http://ng1.17img.cn/bbsfiles/images/2017/01/201701191651_624049_1602049_3.jpg[/img]
1.建模时,校正集和验证集的选取到底应该是多大的比例呢?是不是用不同的算法选取的比例也不一样呢?看文献中,用SVM分类时,大部分按1:1分校正集和验证集,也有分为3:2的。用判别分析的就有2:1或者3:1的了,甚至还有就随便取10个或者几个的。有没有专门的指导或者手册呢?2.还有大家在建模的时候波段都是怎么选取的呢?????
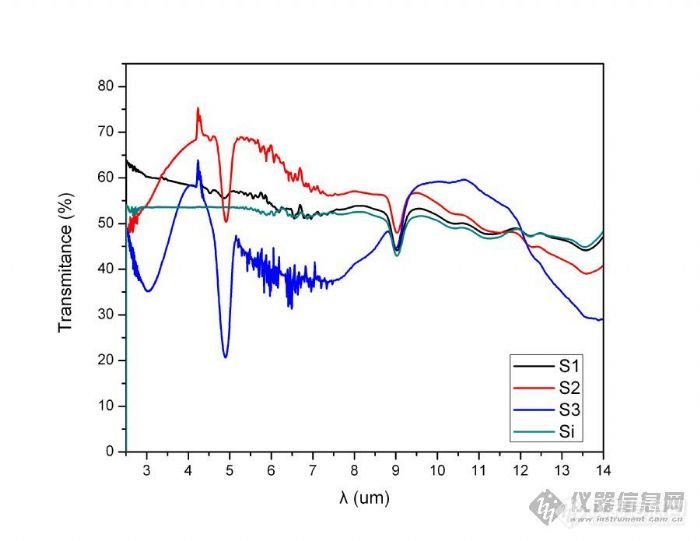
最近做的红外透过光谱,样品是沉积了一层薄膜(约800nm)的双抛的单晶硅片,结果一看样品的透过率比硅片的透过率还高(样品的谱线没有扣除衬底硅的影响),这种现象是不是说明薄膜有增透的作用,还有其他原因会产生这种现象吗?还有,样品35~8um波段的谱线波动的这么厉害是什么原因造成的?[img]http://ng1.17img.cn/bbsfiles/images/2009/09/200909061311_169972_1855701_3.jpg[/img]

为了解决日益突显的能源、环保问题,新能源行业越来越受到世界各国的关注。锂电池行业作为国家重点扶持新能源项目发展较为迅速。近两年,中央和地方各项扶持政策协同效果逐渐显现,我国的新能源汽车市场出现了超预期发展和增长,并带动了产业链上下游企业的高速增长尤其是锂电池行业, 随着新能源汽车销量的进一步提高,业内预计,2018年锂电池或将进入供应紧张的阶段,强烈的需求对锂电池的产品技术、工艺、性能提出了更高的要求,更进一步凸显了产能的不足。目前国际上大多采用先进的激光焊接技术对锂电池的电池芯及保护板进行焊接。随着制造业的不断发展,大力发展高端制造技术,如何提高激光技术在锂电池制造领域的技术水平、如何升级优化激光焊接设备的整体性能,成为目前各个厂家研究的重点。在运动平台部分,直线电机相较于滚珠丝杆有更优的动态性能,更精密的定位精度及重复定位精度,更高的稳定性,更低的维护成本。用直线电机传动平台替换滚珠丝杆运动平台已成为必然趋势。激光焊接技术特点及难点: 激光焊接是一个将正负极材料、隔膜和电解液等原材料化零为整的融合制造过程,是整个锂电池生产流程中的关键工艺。激光焊接是利用激光束优良的方向性和高功率密度等特点来进行工作的。激光焊接有以下特点:激光功率密度高,可以对高熔点、难熔金属或两种材料进行焊接 聚焦光斑小,加热速度快,作用时间短,热影响区域小,热变形可忽略;激光焊接属于非金属焊接,无机械应力和机械变形;激光焊接装置易于计算机联机,能精确定位,实现自动焊接。锂电池模组通过高效精密的激光焊接可以大大降低接触电阻,降低能耗,提高电池的安全性、可靠性和使用寿命。但激光焊接要求焊件装配精度高,且要求激光束在工件上的位置不能有显著偏移。若焊件装配精度以及激光束定位精度达不到要求,很容易造成焊接缺憾,影响焊接质量。激光焊接技术的特点以及锂电池的结构性能对激光焊接设备的运动平台提出了更高更精密的要求。双轴联动直线电机平台技术特点及难点: 直线电机的本质是把旋转电机平放展开并直接连接到驱动负载上。它能替代例如滚珠丝杠、齿条与齿轮、皮带与皮带轮和减速箱的所有机械传动部分,从而消除了齿隙以及与机械传动相关的问题。具有结构简单、调速范围宽、动态性能优良、定位精度高、安全可靠、运行噪声低、无磨损、免维护以及无限行程等优点。灵猴双轴联动直线电机平台加速度可达5g、重复定位精度可达1μm并且在深度优化结构设计的基础上采用独特自主编写控制算法,跟踪检测速度波动,并作出后续补偿,使双轴直线电机在高速度走曲线小圆弧运动条件下,速度波动在3%以下,轨迹偏差更是在微米级别。完全满足锂电池激光焊接对平台精度、加速度、速度等性能的要求。日前有某激光焊接设备厂商客户的设备运动平台采用的是丝杆模组,但在其加速度为1g、速度提到100mm/s时其设备的焊接质量将无法保证,现需求双轴联动直线电机平台以替代丝杆平台模组并明确要求提供包括圆弧转角在内的跟随误差测试报告,但该客户对直线电机运动平台并不了解,故向我公司寻求解决方案。经过与客户的数次技术交流,在完全理解掌握客户设备的特性信息后设计了初版双轴联动直线电机运动平台模组,但是其要求的运动平台的运动轨迹的圆弧转角要求较小,且其速度及精度要求较高,经过我司对双轴联动直线电机平台的结构优化,定制化编写算法控制上下两轴的耦合,经过详细的系统测试,最终满足客户的需求,升级优化了客户的激光焊接设备,使其设备的焊接速度、精度以及稳定性在同行业处于领先地位。客户要求如下:[b]直线电机需求表 [/b]客户名称:[u] 某激光焊接设备集成 [/u]运用行业:[u] 锂电池激光焊接 [/u]联系人电话:[u] [/u]电子邮箱:[u] [/u]运动轴运动方式 :□水平 √ □垂直速度规划曲线:□1/3-1/3-1/3梯形波 √ □1/2-1/2三角形波总的运动行程:[u] 上轴270mm、下轴300mm [/u]mm总的运行时间:[u] 1.8s [/u]s最大运行速度:[u] 0.5 [/u]m/s最大运行加速度:[u] 3g [/u]m/s2负载重量:[u] 30 [/u]kg精度定位精度:[u] ±5 [/u]μm重复定位精度:[u] ±1 [/u]μm分辨率:[u] 0.1 [/u]μm放大器和电源最大电流:[u] 6.3 [/u]A电压:[u] 220 [/u]VAC □50 Hz √ □60Hz使用环境环境温度:[u] 室温 [/u]℃最大允许温升:[u] 130 [/u]℃是否在无尘环境中: □是 √ □否是否允许水冷或空气冷却:□是 □否 √是否是真空环境: □是 √ □否硬件总体设计及验证系统配置: 双轴联动直线电机运动平台主要由:直线电机、检测反馈、驱动控制,防护装置四部分组成。该运动平台选用无铁芯直线电机,运动平滑无齿槽力;检测反馈由光栅或磁栅、霍尔、温控组成;此平台模组选用的是高创驱动器,防护装置由风琴防护罩、高性能拖链、光电传感器、优力胶硬限位组成,充分保护运动平台的安全可靠性。模型效果如图2所示: [img=十字滑台,554,415]http://ng1.17img.cn/bbsfiles/images/2017/08/201708311009_01_3294819_3.jpg[/img][align=center]图1:双轴联动模组模型[/align]双轴联动直线电机主要性能参数如图3所示: [img=,327,290]http://ng1.17img.cn/bbsfiles/images/2017/08/201708311010_01_3294819_3.jpg[/img][align=center]图2:双轴联动模组性能参数[/align]验证测试根据客户设备的运动特点及轨迹,为保证客户设备在运行过程中的稳定性及可靠性,我们多次做了过需求验证并出具了相关的验证报告,运动平台的各项参数均符合客户需求,并做了相当于设备连续运行1.5年的耐疲劳测试,各项参数均无异常。经过多次技术交流、结构优化、测试验证,灵猴双轴联动直线电机运动平台仅在两周的时间就达到了客户的要求,满足了交付条件并实时在客户现场调试安装,直到客户设备完全出货,我们还积极跟踪我司产品在客户设备终端的运行状况以及各项数据,实时为客户设备提供可靠性报告。该客户“非标私人订制”的双轴联动直线电机运动平台模组上下两轴均采用自主研发的BUM系列无铁芯直线电机,该系列直线电机具有高推力、低运动质量、无齿槽效应、无磁吸力等特点,特别是在走曲线圆弧轨迹时,可实现高速度小圆弧转角下的低速度波动。在使用了双轴联动直线电机运动平台后,使其焊接速度提高50%,提高了其圆弧转角处的焊接质量,升级优化了客户整体设备的性能,提高客户设备销量的同时也增加了直线电机模组的销量,真正实现了双赢价值。直线电机平台模组除上述应用外,还有在医疗行业应用的超薄十字蛇形运动平台模组,其整体尺寸大小仅有圆珠笔大小;在3C行业中的视觉检测以及点胶平台上的快速移动的四轴联动直线电机模组;在机床以及快速搬运行业的LPS系列单轴平台模组;可以完全直接替换丝杆的SP标准系列单轴平台模组等等。随着制造行业越来越苛刻的要求,现代先进制造装备向着高速度、高精度、快响应、大行程的趋势发展。这必然要求一个反应灵敏、高速、轻便的驱动系统,由于传统的进给方式—“旋转电机+ 滚珠丝杠”需要联轴器、丝杠等中间传递环节,造成整体系统刚性不够、弹性变形严重,又因为该“间接传动”中丝杠精度很难提高、存在反向间隙等缺点,使得传统的进给系统无法达到上述要求。相对而言,直线电机具有结构简单、安装方便、无接触、无磨损等优点,并在精度、重复定位精度、刚度、工作寿命等其他性能指标上都优于旋转电机。其主要推广与高速、高精等旋转电机无法满足要求的场合。现代直线电机技术日益成熟,其势必取代传统的“旋转电机+ 丝杠”的传动模式。
目前, 3 μm 波段光纤激光器在高功率化、 降低成本化、 生产规模化等方面还有许多限制。无氧玻 璃在原料提纯、 大尺寸制备、 光纤拉制等方面的工艺 仍显不足, 这也是制约所有中红外发光稀土掺杂光 纤走向实用化的最大障碍。另外, 提高稀土离子浓度虽能提高光纤单位长 度增益, 但也会增加光纤的传输损耗或发生浓度淬 灭现象, 也制约了其发展。而 “级联” 掺 Er 3 + 光纤激 光器由于具有较低的掺杂浓度和纤芯温度具有十分 广阔的研究前景。同时, 掺 Ho 3 + 光纤激光器由于采 用 1150 nm 的抽运光, 斜效率更高, 也具有较好的应 用前景。
[font=宋体]可以采用波长选择方法选择光谱中与目标组分相关的变量。目前,发展了很多波长选择方法,概括起来它们可以分为三大类:波长点选择、波段选择和变量加权的方法。波长点选择方法包括基于单一指标的方法、基于统计学的方法和基于智能优化算法的方法等;波段选择方法主要包括间隔偏最小二乘法、移动窗口偏最小二乘法及它们的衍生化方法;变量加权的方法是波长选择方法的发展与[/font][font=宋体][font=宋体]扩充,它使用全部的波长点,但是给每个变量赋予不同的权重,有变量加权的[/font][font=Times New Roman]PLS[/font][font=宋体]和变量加权的[/font][font=Times New Roman]SVR[/font][font=宋体]等方法。具体方法参考本章第[/font][font=Times New Roman]5[/font][font=宋体]节。[/font][/font]
本人现在做近红外光谱,正在学习用MATLAB对光谱数据进行特征波段的选取,哪位大侠教下我啊?有酬谢!有意的加我Q1355008248!
各位高工!光谱仪的波段范围 190-500nm是什么意思啊!它起什么作用,要怎么选择啊!!!
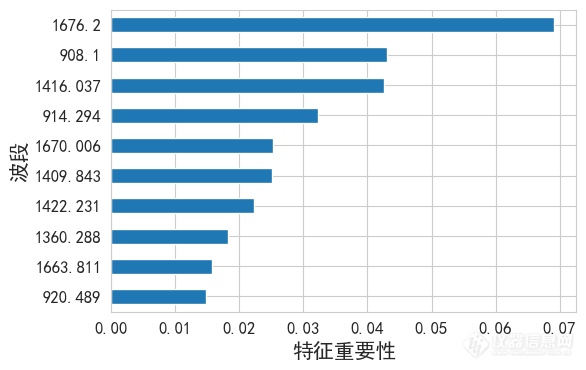
[font='times new roman'][size=16px][b]几种[/b][/size][/font][font='times new roman'][size=16px][b]波段选择[/b][/size][/font][font='times new roman'][size=16px][b]方法原理及应用[/b][/size][/font][size=14px][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据的波段数有[/size][size=14px]多[/size][size=14px]个,特征维度较多,数据量较大,不同波段之间的信息冗余度高,具有一定的重叠性。本实验所用的试验样品是由多个成分组成的混合物,这样采集的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]就会由于没有混合均匀等原因常常掺杂着一些对非目标组分的吸收,导致光谱数据中的某些波段与样品的性质之间是比较差的关联关系,甚至是有一些关联关系是错误的,这就容易出现部分波段信息冗余的现象。同时,也会有其他一些因素对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的准确性产生不利影响。[/size][size=14px]因此,为了得到更加有利于建立模型的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据,需要对一些无用的噪声波段进行剔除,找出那些含有较高信息量、容易分离、彼此相关度较低的波段,这就需要对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]进行波段选择。通过波段选择从原始[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]中选择包含大量有效信息的波段子集,这些波段在建模中起主要作用,这样不但可以大大降低[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的维度,提高模型建立的速度,而且可以将光谱中存在的噪声信息剔除掉,只保留对提升模型准确性有利的信息。本文使用的波段选择方法使皮尔森相关系数法和随机森林法。[/size][font='times new roman'][size=16px][b]皮尔森相关系数法[/b][/size][/font][size=14px]相关系数法[/size][font='times new roman'][size=14px][54][/size][/font][size=14px]是将采集光谱的所有波段与颗粒的实际水分含量进行相关性计算,得到光谱每个波段与水分含量的相关系数。确定一定的阈值,将波段按照相关系数绝对值的大小进行排序,相关系数的绝对值超过阈值大小的波段保留下来,用这部分波段进行建模。[/size][size=14px]两个变量之间相关系数的大小在[/size][size=14px]-1~1[/size][size=14px]之间变化,当其中一个变量增大而另一个变量减小时,说明两个变量是负相关的,其相关系数为负数,并且相关系数越小,说明两个变量的负相关性越大;当其中一个变量增大,另一个变量也随之增大时,说明两个变量是正相关的,相关系数为正数,并且相关系数越大,说明两个变量间的正相关性越大。为了了解两个变量间的相关程度,以相关系数的绝对值[/size][size=14px]|R|[/size][size=14px]为标准判断两个变量的线性相关性大小,如下表所示。[/size][align=center][font='times new roman'][size=16px]表两个变量的相关性大小[/size][/font][/align][table][tr][td][align=center][font='times new roman'][size=16px]相关系数绝对值[/size][/font][font='times new roman'][size=16px]|R|[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]相关性程度[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]≥[/size][/font][font='times new roman'][size=16px]0.95[/size][/font][/align][/td][td][align=center][size=13px]显著性相关[/size][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]≥[/size][/font][font='times new roman'][size=16px]0.8[/size][/font][/align][/td][td][align=center][size=13px]高度相关[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.5[/size][font='宋体'][size=13px]≤|[/size][/font][font='宋体'][size=13px]R[/size][/font][size=13px]|0.35[/size][/font][font='times new roman'][size=16px]光谱波段[/size][/font][/align][size=14px] [/size][size=14px] [/size][size=14px]图中,绿色方格线覆盖的波段为相关系数绝对值[/size][size=14px]|R|[/size][size=14px]0.35[/size][size=14px]的波段。图中可以看出,与水分相关系数比较高的地方都在波段[/size][size=14px]908.1nm~1400nm[/size][size=14px]之间,将全光谱的[/size][size=14px]125[/size][size=14px]个波段降低到了[/size][size=14px]80[/size][size=14px]个。[/size][font='times new roman'][size=16px][b] [/b][/size][/font][font='times new roman'][size=16px][b]随机森林法[/b][/size][/font][size=14px]随机森林[/size][font='times new roman'][size=14px][55][/size][/font][size=14px]是一种并行的[/size][size=14px]bagging[/size][font='times new roman'][size=14px][56][/size][/font][size=14px]集成学习算法。随机森林使用的数据采集方法为“自助采样法”,自主采样法在数据集较小的情况下会有较好的训练结果。从一个包含[/size][size=14px][i]n[/i][/size][size=14px]个[/size][size=14px]样本的数据集[/size][size=14px][i]M[/i][/size][size=14px]中每次随机取出一个样本,对样本进行记录后把该样本重新放回[/size][size=14px][i]M[/i][/size][size=14px]中再进行随机取样,即有放回的随机取样,这样取出来的所有样本组成数据集[/size][size=14px][i]D[/i][/size][size=14px]。重复采样[/size][size=14px][i]n[/i][/size][size=14px]次,[/size][size=14px][i]M[/i][/size][size=14px]中有一部分数据在[/size][size=14px][i]D[/i][/size][size=14px]中重复出现多次,有一部分数据从来没有在[/size][size=14px][i]D[/i][/size][size=14px]中出现过,一个样本被取到的概率为[/size][size=14px]1/[/size][size=14px][i]n[/i][/size][size=14px],那么在[/size][size=14px][i]n[/i][/size][size=14px]次采样过程中样本一直不被取到的概率为([/size][size=14px]1-1/[/size][size=14px][i]n[/i][/size][size=14px])[/size][font='times new roman'][size=14px]1/[/size][/font][font='times new roman'][size=14px][i]n[/i][/size][/font][size=14px],通过求极限可以得到[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]以采集的样本[/size][size=14px][i]D[/i][/size][size=14px]作为训练集,以未采集的样本数据集[/size][size=14px][i]P[/i][/size][size=14px]作为测试集。对数据集[/size][size=14px][i]D[/i][/size][size=14px]进行训练,并在训练过程中加入随机属性选择,这样就得到了一个决策树算法的[/size][size=14px]基学习器[/size][size=14px],然后把所有的[/size][size=14px]基学习器[/size][size=14px]组合起来,得到输出结果。在分类任务中,对每个[/size][size=14px]基学习器[/size][size=14px]对预测结果进行投票得到输出结果;在回归任务中,将每个[/size][size=14px]基学习器[/size][size=14px]的预测结果进行简单平均,求得的平均数作为最终的结果。[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]水分预测是一个回归任务,因此选择随机森林回归法,[/size][size=14px]基学习器[/size][size=14px]的决策树为回归树,训练样本过将多个[/size][size=14px]基学习器回归[/size][size=14px]树进行训练,使用简单平均法获得预测结果,获得比单一回归树模型具有更高的预测准确率[/size][font='times new roman'][size=14px][57][/size][/font][size=14px]。随机森林回归的示意图如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林回归示意图[/size][/font][/align][size=14px]随机森林回归算法中使用的基模型为[/size][size=14px]CART[/size][size=14px]回归树[/size][font='times new roman'][size=14px][58][/size][/font][size=14px],特征空间的划分和每个单元的输出值由这些回归树来决定。在回归树中,选择最佳的划分点需要对每个特征的所有值进行遍历,直到取得某个特征的某个值,使得损失函数最小,这就是最佳的划分点。假设有[/size][size=14px][i]n[/i][/size][size=14px]个[/size][size=14px]特征,每个特征有[/size][size=14px]个[/size][size=14px]取值,将特征空间划分为[/size][size=14px][i]M[/i][/size][size=14px]个[/size][size=14px]单元[/size][size=14px],[/size][size=14px]为[/size][size=14px]上输入[/size][size=14px]对应[/size][size=14px]的平均值,[/size][size=14px]则该过程的公式如下:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]选择最佳的划分点后,回归树的方程为:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]式中,[/size][size=14px][i]I([/i][/size][size=14px][i]x)[/i][/size][size=14px]为指示函数。[/size][size=14px]通过随机森林计算特征集中某一特征重要程度的过程如下:[/size][size=14px]([/size][size=14px]1[/size][size=14px])从数据集[/size][size=14px][i]M[/i][/size][size=14px]中通过随机自采样的方法获得数据集[/size][size=14px][i]D[/i][/size][size=14px],用数据集[/size][size=14px][i]D[/i][/size][size=14px]作为训练集进行建模,用没采集到的数据集[/size][size=14px][i]P[/i][/size][size=14px]进行验证,得到数据集[/size][size=14px][i]P[/i][/size][size=14px]的误差,记作[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]。[/size][size=14px]([/size][size=14px]2[/size][size=14px])生成一组随机噪声数据,将随机噪声干扰数据加入到数据集[/size][size=14px][i]P[/i][/size][size=14px]的某一特征中,使得该特征对预测结果产生干扰,然后再次对数据集[/size][size=14px][i]P[/i][/size][size=14px]的误差进行计算,记作[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]。[/size][size=14px]([/size][size=14px]3[/size][size=14px])计算[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]与[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]的差值。如果该特征是对预测结果起正向作用,则加入噪声数据后[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]与[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]的差值一定大于[/size][size=14px]0[/size][size=14px],反之则小于零。差值与这个特征对该模型预测精度的影响程度成正比。[/size][size=14px]([/size][size=14px]4[/size][size=14px])如果随机森林中有[/size][size=14px][i]N[/i][/size][size=14px]棵树,计算[/size][size=14px][i]N[/i][/size][size=14px]棵树对该特征[/size][size=14px][i]error2[/i][/size][size=14px]与[/size][size=14px][i]error1[/i][/size][size=14px]的差值的平均值,即[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]([/size][size=14px]5[/size][size=14px])遍历数据集[/size][size=14px][i]P[/i][/size][size=14px]中的所有特征,求出每个特征的重要性。[/size][size=14px]用随机森林回归法对光谱数据与水分含量进行建模,得到数据[/size][size=14px]中特征[/size][size=14px]重要性排名,其中排名前十的特征如图[/size][size=14px]3-9[/size][size=14px]所示。[/size][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031753099412_7932_3890113_3.png[/img][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林特征选择排名前十的特征[/size][/font][/align][size=14px]特征重要性值的数据分布如下表所示。[/size][align=center][font='times new roman'][size=16px]表[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林特征重要性分布[/size][/font][/align][table][tr][td][align=center][font='times new roman'][size=16px]数值分布[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]特征重要性[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]最小值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0022[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]1/4[/size][/font][font='times new roman'][size=16px]分位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0041[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]中位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0060[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]3/4[/size][/font][font='times new roman'][size=16px]分位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0081[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]最大值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0692[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]平均值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0080[/size][/font][/align][/td][/tr][/table][size=14px]分别以随机森林特征重要性数值分布的[/size][size=14px]1/4[/size][size=14px]分位数、中位数、[/size][size=14px]3/4[/size][size=14px]分位数和平均值为选择标准,以大于这个标准的特征重要性组合成的特征波段进行[/size][size=14px]PLS[/size][size=14px]建模,选择最佳的波段组合。建模的结果如下表所示。[/size][align=center][font='times new roman'][size=16px]表[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]不同特征重要性的波段模型评价[/size][/font][/align][table][tr][td][align=center][size=13px] [/size][size=13px] [/size][size=13px]评价参数[/size][/align][size=13px]特征重要性[/size][/td][td][align=center][size=13px]R[/size][size=13px]MSECV[/size][/align][/td][td][align=center][size=13px]R[/size][size=13px]MSEP[/size][/align][/td][td][align=center][size=14px]R[/size][font='times new roman'][size=14px]p[/size][/font][/align][/td][/tr][tr][td][align=center][size=13px]全波段[/size][/align][/td][td][align=center][size=13px]0.242[/size][/align][/td][td][align=center][size=13px]0.221[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]60[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0041[/size][/align][/td][td][align=center][size=13px]0.222[/size][/align][/td][td][align=center][size=13px]0.214[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]80[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0060[/size][/align][/td][td][align=center][size=13px]0.216[/size][/align][/td][td][align=center][size=13px]0.209[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].[/size][size=13px]983[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0080[/size][/align][/td][td][align=center][size=13px]0.228[/size][/align][/td][td][align=center][size=13px]0.225[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]75[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0081[/size][/align][/td][td][align=center][size=13px]0.2[/size][size=13px]3[/size][size=13px]2[/size][/align][/td][td][align=center][size=13px]0.230[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]6[/size][/align][/td][/tr][/table][size=14px]很明显,通过随机森林方法计算出各个特征的重要性,以[/size][size=14px]0.0060[/size][size=14px]作为最低标准选择的波段用来建立[/size][size=14px]PLS[/size][size=14px]模型的效果最好。选择的波段如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林波段选择[/size][/font][/align][size=14px] [/size][size=14px] [/size][size=14px]图中绿色背景的是通过随机森林选择的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]波段,其波段主要分布在[/size][size=14px]908.1nm~1150nm[/size][size=14px]和[/size][size=14px]1350nm~1500nm[/size][size=14px]之间,将[/size][size=14px]125[/size][size=14px]个光谱波段降低到了[/size][size=14px]60[/size][size=14px]个,[/size][size=14px]降维效果[/size][size=14px]和模型评价效果均优于相关系数法。因此在流化床制粒过程[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的建模中应用随机森林法进行波段选择。[/size]
在直读光谱仪的实际应用中,如C、P、S、As等元素的最优光谱线均在真空紫外波段,而空气中的氧气及水蒸气等会对这些谱线产生强烈的吸收,使光谱强度急剧减弱,影响元素测量,所以应当将光室中的空气除去。 目前主流市场上主要有两种方式可以实现真空紫外波段元素的测量,光室抽真空或充惰性气体(如氩气、氦气等)。 抽真空型的直读光谱仪需要用额外的真空泵,存在油蒸汽污染严重、噪音大等环境问题。同时,功耗高、真空稳定速度慢,仪器需长期开机,浪费严重。 光室充惰性气体能实现真空紫外探测能力的同时,还具有稳定时间短,无噪音等优点,且能避免由于真空系统造成的光室变形、仪器漂移和环境污染等问题,目前,市场主流光谱仪多采用CCD传感器作为检测装置,光室体积可做到很小,更有利于惰性气体环境建立,从而得到更好的紫外元素分析效果,且该项技术已经过十多年市场验证,稳定可靠。
用标准物质测试发现激光粒度仪不准确了怎么办
光谱的全波段波长指的是什么?包含哪些波长的光?
日前,由中国计量科学研究院承担的国家“十一五”科技支撑课题 “飞秒脉冲激光参数测量新技术研究”通过了专家验收。该课题自主研制的飞秒脉冲自相关仪和飞秒脉冲光谱相位相干仪实现了飞秒脉冲激光参数的准确测量,课题组提出的飞秒脉冲光谱相位还原方法降低了传统方法的测量不确定度,将我国飞秒脉冲激光参数的准确度提高到国际领先水平。 飞秒是时间单位,1飞秒相当于10-15秒。它有多快呢?我们知道,光速是1秒钟30万公里,而在1飞秒内,光只能走0.3微米,相当于一根头发丝的百分之一!飞秒脉冲是人类目前在实验室条件下能获得的在可见光至近红外波段的最短脉冲,它以其独具的持续时间极短、峰值功率极高、光谱宽度极宽等优点,在物理学、生物学、化学、光通讯、外科医疗、精细加工制造及超小器械制造等领域得到很广泛的应用。如何准确地测量超短脉冲信息已成为飞秒脉冲研究领域迫切需要解决的难题。
[color=#cc0000][b]有哪些直读光谱可分析谱线处于长波段的Na、Li 及K 等元素?[/b][/color]
遥感光谱分辨率象元光谱分辨率为28位的图那么 不同波段的光谱如何在二十八位上表示的? 连续还是先划好区间的?
请教各位朋友:仪器:UV-3600+积分球 1:我们测过自己的样品固体材料(200-3300Nm),发现在近红外区谱线震荡非常厉害,不成峰型。是否是因为红外区有空气水分子干扰?需要充氮气循环?2:确实小虫知识不足,我想请教UV-VIS-NIR+积分球主要测试材料漫反射的作用是什么呢? 是不是检测A-H基团的?3.问个初级问题,人体发出的红外波段大概是哪个范围呢?
请教各位朋友:仪器:UV-3600+积分球1:我们测过自己的样品固体材料(200-3300Nm),发现在近红外区谱线震荡非常厉害,不成峰型。是否是因为红外区有空气水分子干扰?需要充氮气循环?2:确实小虫知识不足,我想请教UV-VIS-NIR+积分球主要测试材料漫反射的作用是什么呢? 是不是检测A-H基团的?3.问个初级问题,人体发出的红外波段大概是哪个范围呢?
日本研究人员近日利用X射线自由电子激光装置成功发射出波长仅0.12纳米的X射线激光,刷新了这种激光最短波长的世界纪录。 根据日本理化研究所和高辉度光科学研究中心联合发布的新闻公报,来自这两家机构的研究人员利用建在兵库县的X射线自由电子激光装置发出了波长仅0.12纳米的X射线激光,打破了美国的直线加速器相干光源于2009年4月创下的0.15纳米的最短波长世界纪录。 公报说,研究人员将X射线自由电子激光装置的监视器、电磁石等硬件,以及精密控制各种仪器的软件都按最佳设计进行了彻底调整,从2月底装置运转开始,仅用了3个多月时间就发射出了世界最短波长的X射线激光。而当年美国的调整过程花费了几年时间。 X射线激光的波长小于1纳米,它被看作能给原子世界照相的“梦幻之光”。在从基础研究到应用开发的广阔领域,比如膜蛋白的结构分析、纳米技术等领域,X射线激光的应用前景都被看好。(科技日报)
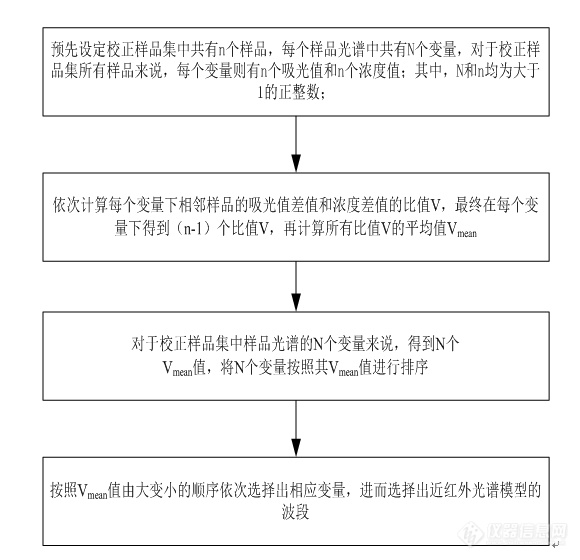
[align=center][b]基于“吸光度-浓度变化率”波段选择方法提高[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模能力[/b][/align][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]定量分析是一种二级分析方法,利用校正模型对未知含量或性质参考值的样品基于[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据进行预测,以测定未知待测样品的浓度或性质参考值,根据预测结果评价模型的预测能力和有效性。由于[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]吸收峰严重重叠,信号吸收较弱,背景干扰严重。因此需要运用波段选择方法提取有效波段,常用的波段选择方法包括前向间隔偏最小二乘法(forwardintervalpartialleastsquares, FiPLS)、反向间隔偏最小二乘法(backwardintervalpartialleastsquares, BiPLS),相关系数法(correlationcoefficient, CC)和无信息变量消除算法(uninformativevariableelimination, UVE)等。本实验对近红外建模物质的浓度与吸光度的变化率进行研究,提出了新的波段选择方法:“吸光度-浓度变化率”方法(Ratioof absorbance to concentration,RATC),弥补了常用波段选择的缺陷,构建了血浆蛋白含量检测模型。1材料1.1试剂血浆样品(山东泰邦生物制品有限公司,中国);去离子水。1.2仪器和软件AntarisⅡ傅里叶变换[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url],液体采样附件;液体玻璃小管(4×50mm,KimbleChase 德国);Matlab2015a(美国Mathworks公司);PLS_Toolbox工具箱(美国EigenvectorResearch)。2方法2.1光谱采集采用傅里叶变换[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url](Antaris II FT-NIR)液体温控透射采样模块,控制温度为37℃下,采集原料人血浆样品光谱。光谱扫描范围和分辨率为10000-4000cm[sup]-1[/sup]和8cm[sup]-1[/sup],扫描次数为32次,参比为空气,每隔1小时校正背景。实验室环境为温度26℃,湿度30%。2.2 校正集验证集划分方法需要划分校正集和验证集的样品:原料人血浆样品20份,[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模属性为总蛋白含量值;2.3 数据处理及模型建立研究采用MATLAB2015a数学软件以及PLS_Toolbox 1.95工具箱对光谱数据进行处理,对建模物质的吸光度和浓度进行变化率分析,选出用于建模的波数点,针对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术的建模分析,以验证均方根误差(RMSEP)值作为其建模预测能力的主要指标。通过讨论不同物质的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析模型建模结果,验证所提波段选择方法的可行性和应用性。3 “吸光度-浓度变化率”波段选择原理及方法本文提出了一种[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型的波段选择方法,基于“吸光度浓度变化率”对校正样品集中所有样品进行波段选择,其具体过程为:步骤1:预先设定校正样品集中共有n个样品,每个样品光谱中共有N个变量,对于校正样品集所有样品来说,每个变量则有n个吸光值和n个浓度值;其中,N和n均为大于1的正整数;步骤2:依次计算每个变量下相邻样品的吸光值差值和浓度差值的比值V,最终在每个变量下得到(n-1)个比值V,再计算所有比值V的平均值V[sub]mean[/sub];V[sub]i[/sub]=|(A[sub]i[/sub]-A[sub]i[/sub][sub]+[/sub][sub]1[/sub])|/(C[sub]i[/sub]-C[sub]i[/sub][sub]+[/sub][sub]1[/sub]) (1)V[sub]mean[/sub]=[img=,50,50]https://bbs.instrument.com.cn/xheditor/xheditor_skin/blank.gif[/img] (2)A[sub]i[/sub]表示第i个样品的吸光值,A[sub]i[/sub][sub]+[/sub][sub]1[/sub]表示第i+1样品的吸光值;C[sub]i[/sub]表示第i个样品的浓度值,C[sub]i[/sub][sub]+[/sub][sub]1[/sub]表示第i+1个样品的浓度值;V[sub]1[/sub]表示第1个样品与其相邻的第2个样品的吸光值差值和浓度差值的比值;V[sub]2[/sub]表示第2个样品与其相邻的第3个样品的吸光值差值和浓度差值的比值;V[sub]3[/sub]表示第3个样品与其相邻的第4个样品的吸光值差值和浓度差值的比值;V[sub]4[/sub]表示第4个样品与其相邻的第5个样品的吸光值差值和浓度差值的比值;V[sub]n[/sub][sub]-[/sub][sub]1[/sub]表示第n-1个样品与其相邻的第n个样品的吸光值差值和浓度差值的比值。步骤3:对于校正样品集中样品光谱的N个变量来说,得到N个V[sub]mean[/sub]值,将N个变量按照其V[sub]mean[/sub]值进行排序;步骤4:按照V[sub]mean[/sub]值由大变小的顺序依次选择出相应变量,直至所有变量全部选完,停止建模,记录所有情况的建模结果。其中,V[sub]mean[/sub]值越大,则代表吸光值因浓度变化所产生的响应越大,同时V[sub]mean[/sub]即为所提出的波段选择方法的关键值,命名为“吸光度-浓度变化率”值。从V[sub]mean[/sub]值最大的变量开始建模,随后按照V[sub]mean[/sub]值由大变小的顺序,采取依次增加一个变量的方法,开始建立[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型,简化流程图如图4-1所示。[align=center][img=,580,560]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161623164821_3386_3237657_3.png!w580x560.jpg[/img][/align][align=center]图4-1“吸光度-浓度变化率”波段选择方法简化流程图[/align]具体应用例证如图4-2所示:校正样品集有20个样品,其浓度值分别为C[sub]1[/sub],C[sub]2[/sub],…,C[sub]20[/sub]。[align=center][img=,670,461]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161623371131_5892_3237657_3.png!w670x461.jpg[/img][/align][align=center]图4-2“吸光度-浓度变化率”波段选择方法具体例证过程[/align]本文将所提出的波段选择方法用于血浆蛋白含量检测模型的构建中,讨论血浆蛋白含量变化同样品吸光度之间的变化率,进而选择合适的波段用于建模。[b]4 实验结果4.1 近红外建模样品集划分[/b]对三种样品进行校正集和验证集的划分结果如表4-1所示,其结果全部满足验证集的参数值范围在校正集之内,同时对于不同样品的不同属性的校正集和验证集来说,其平均值和标准偏差值也比较接近,满足[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模校正集和验证集的划分要求。[align=center]表4-1不同样品不同属性的校正集验证集数据统计结果[/align] [table][tr][td] [align=center]样品[/align] [align=center](检测参数) [/align] [/td][td] [align=center]样品集[/align] [/td][td] [align=center]样本数[/align] [/td][td] [align=center]最大值[/align] [/td][td] [align=center]最小值[/align] [/td][td] [align=center]平均值[/align] [/td][td] [align=center]标准偏差[/align] [/td][/tr][tr][td=1,2] [align=center]原料人血浆[/align] [align=center](蛋白含量值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]15[/align] [/td][td] [align=center]76.80[/align] [/td][td] [align=center]40.56[/align] [/td][td] [align=center]59.34[/align] [/td][td] [align=center]12.31[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]5[/align] [/td][td] [align=center]73.16[/align] [/td][td] [align=center]41.89[/align] [/td][td] [align=center]57.56[/align] [/td][td] [align=center]11.65[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](水分值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]10.99[/align] [/td][td] [align=center]9.38[/align] [/td][td] [align=center]10.22[/align] [/td][td] [align=center]0.39[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]10.94[/align] [/td][td] [align=center]9.64[/align] [/td][td] [align=center]10.27[/align] [/td][td] [align=center]0.36[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](蛋白质含量值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]3.83[/align] [/td][td] [align=center]3.09[/align] [/td][td] [align=center]3.50[/align] [/td][td] [align=center]0.18[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]3.82[/align] [/td][td] [align=center]3.18[/align] [/td][td] [align=center]3.48[/align] [/td][td] [align=center]0.18[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](油脂值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]9.71[/align] [/td][td] [align=center]7.66[/align] [/td][td] [align=center]8.73[/align] [/td][td] [align=center]0.53[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]9.60[/align] [/td][td] [align=center]8.11[/align] [/td][td] [align=center]8.49[/align] [/td][td] [align=center]0.32[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](淀粉值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]66.47[/align] [/td][td] [align=center]62.83[/align] [/td][td] [align=center]64.62[/align] [/td][td] [align=center]0.90[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]65.60[/align] [/td][td] [align=center]63.63[/align] [/td][td] [align=center]64.91[/align] [/td][td] [align=center]0.48[/align] [/td][/tr][tr][td=1,2] [align=center]汽油[/align] [align=center](辛烷值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]45[/align] [/td][td] [align=center]89.60[/align] [/td][td] [align=center]83.40[/align] [/td][td] [align=center]87.15[/align] [/td][td] [align=center]1.57[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]15[/align] [/td][td] [align=center]88.70[/align] [/td][td] [align=center]84.50[/align] [/td][td] [align=center]87.25[/align] [/td][td] [align=center]1.46[/align] [/td][/tr][/table][b]4.2 血浆样品[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模结果4.2.1“吸光度-浓度变化率”方法在血浆蛋白含量建模中的应用[/b]利用“吸光度-浓度变化率”方法对血浆样品进行数据分析,得到每个波数点下的V[sub]mean[/sub]值如图4-3所示,按照其V[sub]mean[/sub]值由大到小排列波数点,依次递增波数点个数进行建模,即得到不同[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型结果。[align=center][img=,653,353]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161624210201_7336_3237657_3.png!w653x353.jpg[/img][/align][align=center]图4-3血浆样品不同波数点的V[sub]mean[/sub]值[/align][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]血浆蛋白含量建模结果如图4-4所示,最小的RMSEP值为0.495,模型的RPD值为23.535>3,无模型过拟合现象,所涉及变量数为50个,具体波数点如表4-2所示。获得最佳模型的波数点大部分都分布在6200-6400cm[sup]-[/sup][sup]1[/sup],分析此处的特征吸收峰信息,多为N-H的一级倍频信息。[align=center][img=,653,353]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161625411205_2487_3237657_3.png!w653x353.jpg[/img][/align][align=center]图4-4 血浆蛋白样品[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术的建模结果[/align][align=center]表4-2血浆蛋白样品进行[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术的建模变量[/align] [table][tr][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][/tr][tr][td] [align=center]6363.940[/align] [/td][td] [align=center]6360.083[/align] [/td][td] [align=center]6321.514[/align] [/td][td] [align=center]6294.515[/align] [/td][td] [align=center]6267.517[/align] [/td][/tr][tr][td] [align=center]6367.797[/align] [/td][td] [align=center]6387.082[/align] [/td][td] [align=center]6317.657[/align] [/td][td] [align=center]6414.080[/align] [/td][td] [align=center]6425.651[/align] [/td][/tr][tr][td] [align=center]6371.654[/align] [/td][td] [align=center]6390.938[/align] [/td][td] [align=center]6313.800[/align] [/td][td] [align=center]6417.937[/align] [/td][td] [align=center]6263.660[/align] [/td][/tr][tr][td] [align=center]6356.226[/align] [/td][td] [align=center]6340.798[/align] [/td][td] [align=center]6402.509[/align] [/td][td] [align=center]6290.658[/align] [/td][td] [align=center]6259.803[/align] [/td][/tr][tr][td] [align=center]6375.511[/align] [/td][td] [align=center]6336.941[/align] [/td][td] [align=center]6309.943[/align] [/td][td] [align=center]6286.801[/align] [/td][td] [align=center]7208.608[/align] [/td][/tr][tr][td] [align=center]6352.369[/align] [/td][td] [align=center]6329.228[/align] [/td][td] [align=center]6406.366[/align] [/td][td] [align=center]6282.944[/align] [/td][td] [align=center]6255.946[/align] [/td][/tr][tr][td] [align=center]6348.512[/align] [/td][td] [align=center]6333.084[/align] [/td][td] [align=center]6306.086[/align] [/td][td] [align=center]6421.794[/align] [/td][td] [align=center]6429.508[/align] [/td][/tr][tr][td] [align=center]6379.368[/align] [/td][td] [align=center]6398.652[/align] [/td][td] [align=center]6302.229[/align] [/td][td] [align=center]6279.087[/align] [/td][td] [align=center]6252.089[/align] [/td][/tr][tr][td] [align=center]6383.225[/align] [/td][td] [align=center]6394.795[/align] [/td][td] [align=center]6410.223[/align] [/td][td] [align=center]6275.230[/align] [/td][td] [align=center]7204.751[/align] [/td][/tr][tr][td] [align=center]6344.655[/align] [/td][td] [align=center]6325.371[/align] [/td][td] [align=center]6298.372[/align] [/td][td] [align=center]6271.374[/align] [/td][td] [align=center]6433.365[/align] [/td][/tr][/table][b]4.2.2 同常规波段选择方法的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模比较[/b]为考察“吸光度-浓度变化率”方法的预测能力高低,将其同其他常规变量选择方法 (FiPLS, BiPLS, CC, UVE) 对相同光谱数据进行处理,建立的近红外模型结果对比如图4-5所示。从图4-5中可明显看出,同其他变量选择方法相比,RATC得到了最小的RMSEP值(RMSEP=0.495g/L)。综上所述,对于原料人血浆样品的总蛋白定量来说,RATC方法减少了参与[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模的变量数,提高了血浆蛋白含量建模的预测能力,是一种有效的变量选择方法。[align=center][img=,622,370]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161626000014_401_3237657_3.png!w622x370.jpg[/img][/align][align=center]图4-5 不同血浆蛋白含量的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模结果比较[/align][align=center][b] [/b][/align][b]5小结[/b]本文基于吸光度浓度变化率来对校正样品集中所有样品进行波段选择;其过程为:预先设定校正样品集中共有n个样品,每个样品光谱中共有N个变量,对于校正样品集所有样品来说,每个变量则有n个吸光值和n个浓度值;其中,N和n均为大于1的正整数;依次计算每个变量下相邻样品的吸光值差值和浓度差值的比值V,最终在每个变量下得到(n-1)个比值V,再计算所有比值V的平均值V[sub]mean[/sub];对于校正样品集中样品光谱的N个变量,得到N个V[sub]mean[/sub]值,将N个变量按照其V[sub]mean[/sub]值进行排序;按照V[sub]mean[/sub]值由大变小的顺序依次选择出相应变量,直至所有变量全部选完,停止建模,记录所有情况的建模结果。同常规波段选择方法比较,该方法从三个方面进行了改进,不仅减少了参与[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模变量的数目,提高了[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型的预测能力。丰富了[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型的波段选择方法,给[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型使用者提供“吸光度-浓度变化”波段选择方法。同时由于是根据物质的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]吸光度和浓度的关系建立的波段选择方法,某种程度上,该方法更能够反应物质的化学信息,即吸光度随着浓度变化率,使得该波段选择方法具有广泛的可行性和通用性。

激光测距是光波测距中的一种测距方式,如果光以速度c在空气中传播在A、B两点间往返一次所需时间为t,则A、B两点间距离D可用下列表示。 D=ct/2 式中:D——测站点A、B两点间距离; c——光在大气中传播的速度; t——光往返A、B一次所需的时间。 由上式可知,要测量A、B距离实际上是要测量光传播的时间t,根据测量时间方法的不同,激光测距仪通常可分为脉冲式和相位式两种测量形式。 相位式激光测距仪相位式激光测距仪是用无线电波段的频率,对激光束进行幅度调制并测定调制光往返测线一次所产生的相位延迟,再根据调制光的波长,换算此相位延迟所代表的距离。即用间接方法测定出光经往返测线所需的时间,如图所示。相位式激光测距仪一般应用在精密测距中。由于其精度高,一般为毫米级,为了有效的反射信号,并使测定的目标限制在与仪器精度相称的某一特定点上,对这种测距仪都配置了被称为合作目标的反射镜。若调制光角频率为ω,在待测量距离D上往返一次产生的相位延迟为φ,则对应时间t 可表示为:t=φ/ω将此关系代入(3-6)式距离D可表示为 D=1/2 ct=1/2 c·φ/ω=c/(4πf) (Nπ+Δφ) =c/4f (N+ΔN)=U(N+) 式中:φ——信号往返测线一次产生的总的相位延迟。 ω——调制信号的角频率,ω=2πf。 U——单位长度,数值等于1/4调制波长 N——测线所包含调制半波长个数。 Δφ——信号往返测线一次产生相位延迟不足π部分。 ΔN——测线所包含调制波不足半波长的小数部分。 ΔN=φ/ω 在给定调制和标准大气条件下,频率c/(4πf)是一个常数,此时距离的测量变成了测线所包含半波长个数的测量和不足半波长的小数部分的测量即测N或φ,由于近代精密机械加工技术和无线电测相技术的发展,已使φ的测量达到很高的精度。 为了测得不足π的相角φ,可以通过不同的方法来进行测量,通常应用最多的是延迟测相和数字测相,目前短程激光测距仪均采用数字测相原理来求得φ。 由上所述一般情况下相位式激光测距仪使用连续发射带调制信号的激光束,为了获得测距高精度还需配置合作目标,而目前推出的手持式激光测距仪是脉冲式激光测距仪中又一新型测距仪,它不仅体积小、重量轻,还采用数字测相脉冲展宽细分技术,无需合作目标即可达到毫米级精度,测程已经超过100m,且能快速准确地直接显示距离。是短程精度精密工程测量、房屋建筑面积测量中最新型的长度计量标准器具,宏诚科技的CEM手持式激光测距仪LDM-100就是测量的最佳助手。 手持式激光测距仪使用注意事项 [font=Times New Rom
领导想要买一个光谱仪 测试远红外灯发出的红外线波段 哪位大神可以推荐下吗?
紫外分光光度计有一项功能叫光谱波长扫描,请问是什么意思,全波段扫描和分波段扫描又是什么意思?谢谢
中红外光谱在遥感中的应用中红外波段光谱在遥感中有利用价值么?
想用光栅光谱仪测370~390nm波段中铁的特征谱我用的3~5微米的铁粉,二茂铁是晶体末,最近做了很多次光谱仪检测火焰的实验,比如1、将铁粉放入汽油喷灯中喷出燃烧,未能检测到;我怀疑是铁粉沉淀较快,火焰中几乎没有铁2、直接将铁粉或二茂铁放入开口盆中用AB胶固定,用汽油喷灯喷烧,仍未检测出;我怀疑是因为盆内铁粉接触空气面积较大,盆是铁质的,散热快,一段时间后铁块(铁粉粘在一起了)热量出入平衡,温度上不去,铁谱出不来3、将细绳放入溶有二茂铁的煤油中浸泡,然后挑出细绳点燃后放入一桶中,桶侧面底部开一小口用以通大量氧气,火苗很高很旺,但仍未能检测到铁谱我怀疑还是温度不够……这么多次实验失败,让我不得不想问问大家,用燃烧的方法,铁究竟需要多少温度才能激发跃迁,为光谱仪检测到?有什么方法可以做到吗?有个师傅建议用氧乙炔气焊烧铁块,烧到通红的时候就大概知道温度了,然后测一下,这个方法可行吗







 我要推广仪器
我要推广仪器
 下载APP
下载APP