
最近遇到一个问题 用UV-Vis分光光度计进行全波段扫描时,在325nm-385nm这件总是波动很大,其他波段处是正常的,原以为是样品造成的,所以重新配置了个其他的溶液,结果还是在325nm-385nm这很波动。所以肯定是仪器哪出问题了,有遇到过这种情况的同行么?求解答。http://ng1.17img.cn/bbsfiles/images/2012/04/201204101841_360483_1614145_3.jpg
[url=https://www.hach.com.cn/product-categories/294zhongjinshufenxiyi]重金属检测仪[/url](微量检测,最好是电极法原理的),还有全波段的分光光度计,多用来测量微量样品的DNA的纯度,上述两仪器大概需要多少预算,今天领导突然问我,一下子还真没有概念,好多年不了解仪器了,现在国产多了,是不是价格也相对下来了。
分光光度计如何进行基线平噪和波段积分处理,谁做过,请指教
请教分光光度计检测的波段能不能达到mm级别,例如:"分光光度计可测波长为697.5mm",这里的"mm"是不是"nm"
紫外分光光度计有一项功能叫光谱波长扫描,请问是什么意思,全波段扫描和分波段扫描又是什么意思?谢谢
请问: 听说分光光度计只有全波段扫描也能做到定量分析,请指教!
我系于2002年购买的754型紫外可见分光光度计,最近出现了故障,具体是:除了波长为300-370nm、460-530nm、640-730nm时有光通过外,其他波段均无光通过。请问是什么原因,如何排除故障?因为学生现在正在做毕业论文实验,等着用,很着急!
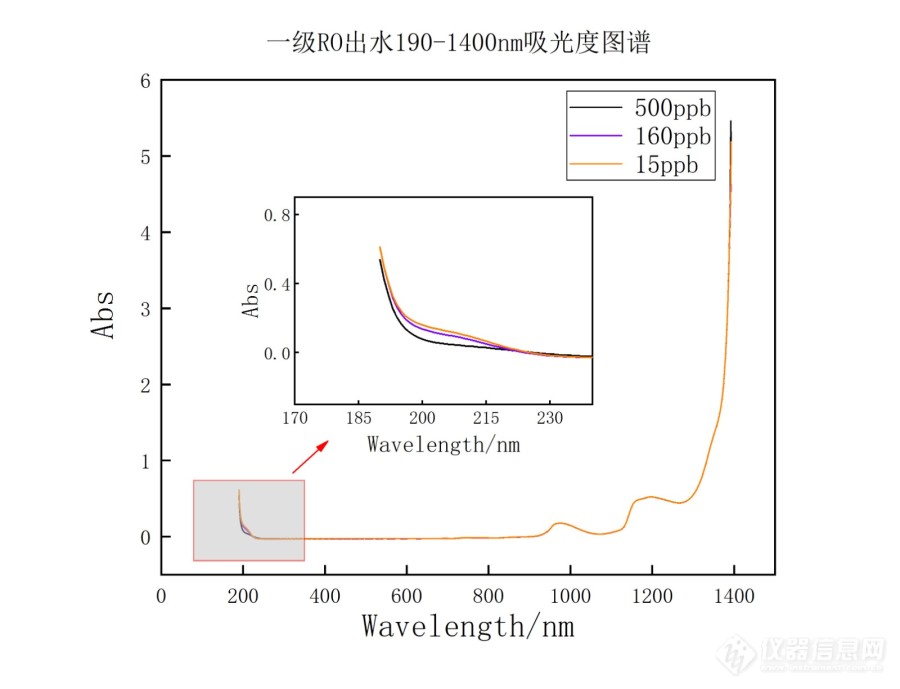
[size=24px]电子级水/超纯水 远紫外波段吸光度检测[/size]请教各位大神,对于类似超纯水、半导体行业用水这种水质指标极高的水,远紫外波段(<200nm)吸光度应该如何检测?有几个疑问,请论坛大神解答;1.远紫外波段真空紫外光易被空气吸收,且光程短,如何适配比色皿,排除空气干扰?2.类似安捷伦、lambda这些仪器为什么标称170nm-3300nm都可以检测,但是实际应用中最低只能检测到190nm处?3.为获得特定波长处(如185nm,超纯水TOC降解波段)吸光度,该如何实现?[img=,690,528]https://ng1.17img.cn/bbsfiles/images/2023/03/202303291111198785_2326_5961157_3.jpg!w690x528.jpg[/img]
紫外可见分光光度计是通过测定被测物质在特定波长处或一定波长范围内光的吸收度,对该物质进行定性和定量分析的仪器。在生物制药、精细化工、环境监测等领域有着广泛应用,并被纳入《中华人民共和国强制检定的工作计量器具明细目录》,需要根据检定规程定期检定。但实际检定过程中经常会出现对同一台仪器不同的检定机构给出的检定结果完全不同,判定不合格的仪器返厂修理时并未发现问题的情况发生。实际上很多时候并不是仪器发生了问题,而是在对仪器的检定过程中,检定人员对一些细节问题了解不足、重视不够造成的。一、波长误差检定中需注意的问题波长误差是一项重要指标,规程中对该项指标的检测,给出了多种标准物质进行选择。选择哪一种标准物质,要根据仪器的情况。一般最常用的波长标准物质是氧化钬玻璃滤光片、镨钕玻璃滤光片。因其使用最方便(不用打开仪器光源部分),汞灯等波长标准需放到光源部分,操作起来相对麻烦。但由于氧化钬玻璃等滤光片需要通过高等级紫外可见分光光度计对参考波长定值后才可使用,所以使用时需充分考虑定值时使用的紫外可见分光光度计的性能,尤其需要考虑到仪器的光谱带宽,定值用仪器的光谱带宽多设定为2nm。但大多数仪器的光谱带宽是固定的,而且较大,尤其是低档仪器,如752型紫外可见分光光度计光谱带宽为4nm,721型可见分光光度计光谱带宽为5nm。表1、表2分别为同一台紫外可见分光光度计在其他条件不变下,光谱带宽分别设定为0.5nm、2.0nm、5.0nm时使用氧化钬玻璃和镨钕滤光片扫描得到的峰值数据,可见当仪器的光谱带宽发生变化时,使用氧化钬玻璃或镨钕玻璃滤光片检测得到的波长误差存在着较大的差异,对于光谱带宽较大的仪器甚至部分波峰检测不到。所以检定过程中应尽量将仪器的光谱带宽设定为滤光片定值时所使用的紫外可见分光光度计的光谱带宽。而且虽然镨钕玻璃滤光片的波长范围可以达到(500~900)nm,但不建议将镨钕玻璃滤光片作波长主标准器,原因是镨钕玻璃滤光片的峰值并不尖锐,比较圆滑。仅可作为对某一空白波段的补偿。例如使用氧化钬玻璃滤光片作为主标准器检测(200~700)nm 范围的波长值,再用镨钕玻璃滤光片补充(700~900)nm波段的波长值。对于光谱带宽不可调且较大的仪器如果使用滤光片检定不合格时切不可急于判定,而应该改用汞灯等自然标准重新对仪器波长误差进行检定,以此为依据做出判断。光谱带宽(nm)0.52.05.0波长(nm)536.5537.0537.0460.2460.4459.9453.9454.0/445.8446.3446.9418.4418.7418.2360.9361.2361.5287.4287.8288.3279.4279.5279.0241.6241.8[
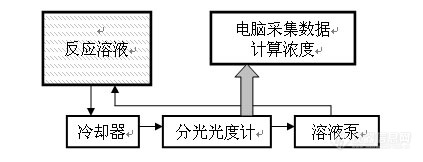
各种反应的实时监测是探索反应过程和积累加工经验的重要手段,近年来越来越为各行业所重视。其中,对物料浓度的在线测试(实时监测)是最重要的也是最麻烦的项目。各种浓度检测方法中,分光光度法是最简单的,但是由于其易受干扰和浓度范围限制等原因,真正用于实验或生产的极少。近年来随着仪器的开发,全波段同步检测手段、多波段吸光度综合分析方法、多种光度测试探头等,对分光光度分析在实时监测方面的发展提供了有力的支持。因此,我想应该进一步进行这方面应用试验研究了。去年底设想了一个简单的分光光度计单波长在线监测装置,各部件的连接如下面框图。装置搭好后,请人在实验中试用了一下,电脑记录了一些染色过程的染料浓度变化情况(每个约3小时),效果倒还可以。以往要做2-3天的工作,大半天就完成了,而且每个过程采集1千多个数据是原来常规方法不可能做到的。我想请各位高手根据原理和方案提点意见,如果要作各种其它监测,应该做些什么调整或改进?请有这方面经验的先行专家不吝赐教。[img]http://ng1.17img.cn/bbsfiles/images/2009/02/200902132144_133087_1633752_3.jpg[/img]
分光光度计是用不连续的波长采样反射物体或透射物体的一种测量仪器。由于不同物体分子的结构不同,对不同波长光线的吸收能力也不同,因此,每种物体都具有特定的吸收光谱。能从含有各种波长的混合光中,将每一种单色光分离出来,并测量其强度的仪器叫做分光光度计。分光光度计所使用的波长范围不同,可分为紫外光区,可见光区、红外光区以及全波段分光区。因此,分光光度计可分为可见光分光光度计。紫外/可见光分光光度计、荧光分光光度计、红外分光光度计等。无论是哪一类分光光度计主要都是由光源、单色器、狭缝、吸收器检测器系统5部分组成的。分光光度计通常提供用白光采样的照明光源。以及包括扩散后折射的反射光,而且允许测量在不连续波长时反射的总光量。分光光度计的准确度是由很多因素决定的,但是最重要的因素之一是光谱波段(即在所测量的光谱中每点波长的范围)。使用分光光度计可以绘制吸收光谱曲线,具有尖峰分光光度法曲线的介质要求分光光度计能通过狭窄的波段,典型的波长间隔是5nm,比较便宜的仪器通常能通过1Onm或20nm的波段。
公司近期需购置一台分光光度计,主要用来测试 光学镀膜 (玻璃或塑胶 等) 的190-1100全波段的透过率。求助 求推荐 目前看中岛津的UV-1900i (需要等待45天,态度差) 想再找多一两个选择
[font=宋体]可以采用波长选择方法选择光谱中与目标组分相关的变量。目前,发展了很多波长选择方法,概括起来它们可以分为三大类:波长点选择、波段选择和变量加权的方法。波长点选择方法包括基于单一指标的方法、基于统计学的方法和基于智能优化算法的方法等;波段选择方法主要包括间隔偏最小二乘法、移动窗口偏最小二乘法及它们的衍生化方法;变量加权的方法是波长选择方法的发展与[/font][font=宋体][font=宋体]扩充,它使用全部的波长点,但是给每个变量赋予不同的权重,有变量加权的[/font][font=Times New Roman]PLS[/font][font=宋体]和变量加权的[/font][font=Times New Roman]SVR[/font][font=宋体]等方法。具体方法参考本章第[/font][font=Times New Roman]5[/font][font=宋体]节。[/font][/font]
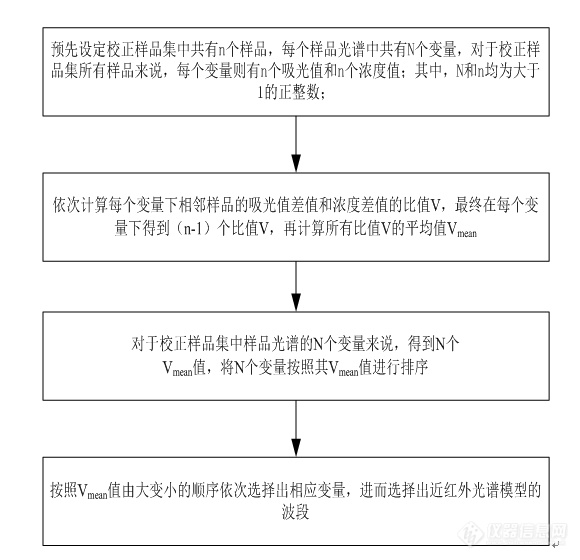
[align=center][b]基于“吸光度-浓度变化率”波段选择方法提高[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模能力[/b][/align][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]定量分析是一种二级分析方法,利用校正模型对未知含量或性质参考值的样品基于[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据进行预测,以测定未知待测样品的浓度或性质参考值,根据预测结果评价模型的预测能力和有效性。由于[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]吸收峰严重重叠,信号吸收较弱,背景干扰严重。因此需要运用波段选择方法提取有效波段,常用的波段选择方法包括前向间隔偏最小二乘法(forwardintervalpartialleastsquares, FiPLS)、反向间隔偏最小二乘法(backwardintervalpartialleastsquares, BiPLS),相关系数法(correlationcoefficient, CC)和无信息变量消除算法(uninformativevariableelimination, UVE)等。本实验对近红外建模物质的浓度与吸光度的变化率进行研究,提出了新的波段选择方法:“吸光度-浓度变化率”方法(Ratioof absorbance to concentration,RATC),弥补了常用波段选择的缺陷,构建了血浆蛋白含量检测模型。1材料1.1试剂血浆样品(山东泰邦生物制品有限公司,中国);去离子水。1.2仪器和软件AntarisⅡ傅里叶变换[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url],液体采样附件;液体玻璃小管(4×50mm,KimbleChase 德国);Matlab2015a(美国Mathworks公司);PLS_Toolbox工具箱(美国EigenvectorResearch)。2方法2.1光谱采集采用傅里叶变换[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱仪[/color][/url](Antaris II FT-NIR)液体温控透射采样模块,控制温度为37℃下,采集原料人血浆样品光谱。光谱扫描范围和分辨率为10000-4000cm[sup]-1[/sup]和8cm[sup]-1[/sup],扫描次数为32次,参比为空气,每隔1小时校正背景。实验室环境为温度26℃,湿度30%。2.2 校正集验证集划分方法需要划分校正集和验证集的样品:原料人血浆样品20份,[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模属性为总蛋白含量值;2.3 数据处理及模型建立研究采用MATLAB2015a数学软件以及PLS_Toolbox 1.95工具箱对光谱数据进行处理,对建模物质的吸光度和浓度进行变化率分析,选出用于建模的波数点,针对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术的建模分析,以验证均方根误差(RMSEP)值作为其建模预测能力的主要指标。通过讨论不同物质的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析模型建模结果,验证所提波段选择方法的可行性和应用性。3 “吸光度-浓度变化率”波段选择原理及方法本文提出了一种[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型的波段选择方法,基于“吸光度浓度变化率”对校正样品集中所有样品进行波段选择,其具体过程为:步骤1:预先设定校正样品集中共有n个样品,每个样品光谱中共有N个变量,对于校正样品集所有样品来说,每个变量则有n个吸光值和n个浓度值;其中,N和n均为大于1的正整数;步骤2:依次计算每个变量下相邻样品的吸光值差值和浓度差值的比值V,最终在每个变量下得到(n-1)个比值V,再计算所有比值V的平均值V[sub]mean[/sub];V[sub]i[/sub]=|(A[sub]i[/sub]-A[sub]i[/sub][sub]+[/sub][sub]1[/sub])|/(C[sub]i[/sub]-C[sub]i[/sub][sub]+[/sub][sub]1[/sub]) (1)V[sub]mean[/sub]=[img=,50,50]https://bbs.instrument.com.cn/xheditor/xheditor_skin/blank.gif[/img] (2)A[sub]i[/sub]表示第i个样品的吸光值,A[sub]i[/sub][sub]+[/sub][sub]1[/sub]表示第i+1样品的吸光值;C[sub]i[/sub]表示第i个样品的浓度值,C[sub]i[/sub][sub]+[/sub][sub]1[/sub]表示第i+1个样品的浓度值;V[sub]1[/sub]表示第1个样品与其相邻的第2个样品的吸光值差值和浓度差值的比值;V[sub]2[/sub]表示第2个样品与其相邻的第3个样品的吸光值差值和浓度差值的比值;V[sub]3[/sub]表示第3个样品与其相邻的第4个样品的吸光值差值和浓度差值的比值;V[sub]4[/sub]表示第4个样品与其相邻的第5个样品的吸光值差值和浓度差值的比值;V[sub]n[/sub][sub]-[/sub][sub]1[/sub]表示第n-1个样品与其相邻的第n个样品的吸光值差值和浓度差值的比值。步骤3:对于校正样品集中样品光谱的N个变量来说,得到N个V[sub]mean[/sub]值,将N个变量按照其V[sub]mean[/sub]值进行排序;步骤4:按照V[sub]mean[/sub]值由大变小的顺序依次选择出相应变量,直至所有变量全部选完,停止建模,记录所有情况的建模结果。其中,V[sub]mean[/sub]值越大,则代表吸光值因浓度变化所产生的响应越大,同时V[sub]mean[/sub]即为所提出的波段选择方法的关键值,命名为“吸光度-浓度变化率”值。从V[sub]mean[/sub]值最大的变量开始建模,随后按照V[sub]mean[/sub]值由大变小的顺序,采取依次增加一个变量的方法,开始建立[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型,简化流程图如图4-1所示。[align=center][img=,580,560]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161623164821_3386_3237657_3.png!w580x560.jpg[/img][/align][align=center]图4-1“吸光度-浓度变化率”波段选择方法简化流程图[/align]具体应用例证如图4-2所示:校正样品集有20个样品,其浓度值分别为C[sub]1[/sub],C[sub]2[/sub],…,C[sub]20[/sub]。[align=center][img=,670,461]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161623371131_5892_3237657_3.png!w670x461.jpg[/img][/align][align=center]图4-2“吸光度-浓度变化率”波段选择方法具体例证过程[/align]本文将所提出的波段选择方法用于血浆蛋白含量检测模型的构建中,讨论血浆蛋白含量变化同样品吸光度之间的变化率,进而选择合适的波段用于建模。[b]4 实验结果4.1 近红外建模样品集划分[/b]对三种样品进行校正集和验证集的划分结果如表4-1所示,其结果全部满足验证集的参数值范围在校正集之内,同时对于不同样品的不同属性的校正集和验证集来说,其平均值和标准偏差值也比较接近,满足[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模校正集和验证集的划分要求。[align=center]表4-1不同样品不同属性的校正集验证集数据统计结果[/align] [table][tr][td] [align=center]样品[/align] [align=center](检测参数) [/align] [/td][td] [align=center]样品集[/align] [/td][td] [align=center]样本数[/align] [/td][td] [align=center]最大值[/align] [/td][td] [align=center]最小值[/align] [/td][td] [align=center]平均值[/align] [/td][td] [align=center]标准偏差[/align] [/td][/tr][tr][td=1,2] [align=center]原料人血浆[/align] [align=center](蛋白含量值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]15[/align] [/td][td] [align=center]76.80[/align] [/td][td] [align=center]40.56[/align] [/td][td] [align=center]59.34[/align] [/td][td] [align=center]12.31[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]5[/align] [/td][td] [align=center]73.16[/align] [/td][td] [align=center]41.89[/align] [/td][td] [align=center]57.56[/align] [/td][td] [align=center]11.65[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](水分值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]10.99[/align] [/td][td] [align=center]9.38[/align] [/td][td] [align=center]10.22[/align] [/td][td] [align=center]0.39[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]10.94[/align] [/td][td] [align=center]9.64[/align] [/td][td] [align=center]10.27[/align] [/td][td] [align=center]0.36[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](蛋白质含量值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]3.83[/align] [/td][td] [align=center]3.09[/align] [/td][td] [align=center]3.50[/align] [/td][td] [align=center]0.18[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]3.82[/align] [/td][td] [align=center]3.18[/align] [/td][td] [align=center]3.48[/align] [/td][td] [align=center]0.18[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](油脂值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]9.71[/align] [/td][td] [align=center]7.66[/align] [/td][td] [align=center]8.73[/align] [/td][td] [align=center]0.53[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]9.60[/align] [/td][td] [align=center]8.11[/align] [/td][td] [align=center]8.49[/align] [/td][td] [align=center]0.32[/align] [/td][/tr][tr][td=1,2] [align=center]玉米[/align] [align=center](淀粉值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]60[/align] [/td][td] [align=center]66.47[/align] [/td][td] [align=center]62.83[/align] [/td][td] [align=center]64.62[/align] [/td][td] [align=center]0.90[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]20[/align] [/td][td] [align=center]65.60[/align] [/td][td] [align=center]63.63[/align] [/td][td] [align=center]64.91[/align] [/td][td] [align=center]0.48[/align] [/td][/tr][tr][td=1,2] [align=center]汽油[/align] [align=center](辛烷值)[/align] [/td][td] [align=center]校正集[/align] [/td][td] [align=center]45[/align] [/td][td] [align=center]89.60[/align] [/td][td] [align=center]83.40[/align] [/td][td] [align=center]87.15[/align] [/td][td] [align=center]1.57[/align] [/td][/tr][tr][td] [align=center]验证集[/align] [/td][td] [align=center]15[/align] [/td][td] [align=center]88.70[/align] [/td][td] [align=center]84.50[/align] [/td][td] [align=center]87.25[/align] [/td][td] [align=center]1.46[/align] [/td][/tr][/table][b]4.2 血浆样品[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模结果4.2.1“吸光度-浓度变化率”方法在血浆蛋白含量建模中的应用[/b]利用“吸光度-浓度变化率”方法对血浆样品进行数据分析,得到每个波数点下的V[sub]mean[/sub]值如图4-3所示,按照其V[sub]mean[/sub]值由大到小排列波数点,依次递增波数点个数进行建模,即得到不同[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型结果。[align=center][img=,653,353]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161624210201_7336_3237657_3.png!w653x353.jpg[/img][/align][align=center]图4-3血浆样品不同波数点的V[sub]mean[/sub]值[/align][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]血浆蛋白含量建模结果如图4-4所示,最小的RMSEP值为0.495,模型的RPD值为23.535>3,无模型过拟合现象,所涉及变量数为50个,具体波数点如表4-2所示。获得最佳模型的波数点大部分都分布在6200-6400cm[sup]-[/sup][sup]1[/sup],分析此处的特征吸收峰信息,多为N-H的一级倍频信息。[align=center][img=,653,353]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161625411205_2487_3237657_3.png!w653x353.jpg[/img][/align][align=center]图4-4 血浆蛋白样品[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术的建模结果[/align][align=center]表4-2血浆蛋白样品进行[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]分析技术的建模变量[/align] [table][tr][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][td] [align=center]波数(cm[sup]-[/sup][sup]1[/sup])[/align] [/td][/tr][tr][td] [align=center]6363.940[/align] [/td][td] [align=center]6360.083[/align] [/td][td] [align=center]6321.514[/align] [/td][td] [align=center]6294.515[/align] [/td][td] [align=center]6267.517[/align] [/td][/tr][tr][td] [align=center]6367.797[/align] [/td][td] [align=center]6387.082[/align] [/td][td] [align=center]6317.657[/align] [/td][td] [align=center]6414.080[/align] [/td][td] [align=center]6425.651[/align] [/td][/tr][tr][td] [align=center]6371.654[/align] [/td][td] [align=center]6390.938[/align] [/td][td] [align=center]6313.800[/align] [/td][td] [align=center]6417.937[/align] [/td][td] [align=center]6263.660[/align] [/td][/tr][tr][td] [align=center]6356.226[/align] [/td][td] [align=center]6340.798[/align] [/td][td] [align=center]6402.509[/align] [/td][td] [align=center]6290.658[/align] [/td][td] [align=center]6259.803[/align] [/td][/tr][tr][td] [align=center]6375.511[/align] [/td][td] [align=center]6336.941[/align] [/td][td] [align=center]6309.943[/align] [/td][td] [align=center]6286.801[/align] [/td][td] [align=center]7208.608[/align] [/td][/tr][tr][td] [align=center]6352.369[/align] [/td][td] [align=center]6329.228[/align] [/td][td] [align=center]6406.366[/align] [/td][td] [align=center]6282.944[/align] [/td][td] [align=center]6255.946[/align] [/td][/tr][tr][td] [align=center]6348.512[/align] [/td][td] [align=center]6333.084[/align] [/td][td] [align=center]6306.086[/align] [/td][td] [align=center]6421.794[/align] [/td][td] [align=center]6429.508[/align] [/td][/tr][tr][td] [align=center]6379.368[/align] [/td][td] [align=center]6398.652[/align] [/td][td] [align=center]6302.229[/align] [/td][td] [align=center]6279.087[/align] [/td][td] [align=center]6252.089[/align] [/td][/tr][tr][td] [align=center]6383.225[/align] [/td][td] [align=center]6394.795[/align] [/td][td] [align=center]6410.223[/align] [/td][td] [align=center]6275.230[/align] [/td][td] [align=center]7204.751[/align] [/td][/tr][tr][td] [align=center]6344.655[/align] [/td][td] [align=center]6325.371[/align] [/td][td] [align=center]6298.372[/align] [/td][td] [align=center]6271.374[/align] [/td][td] [align=center]6433.365[/align] [/td][/tr][/table][b]4.2.2 同常规波段选择方法的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模比较[/b]为考察“吸光度-浓度变化率”方法的预测能力高低,将其同其他常规变量选择方法 (FiPLS, BiPLS, CC, UVE) 对相同光谱数据进行处理,建立的近红外模型结果对比如图4-5所示。从图4-5中可明显看出,同其他变量选择方法相比,RATC得到了最小的RMSEP值(RMSEP=0.495g/L)。综上所述,对于原料人血浆样品的总蛋白定量来说,RATC方法减少了参与[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模的变量数,提高了血浆蛋白含量建模的预测能力,是一种有效的变量选择方法。[align=center][img=,622,370]https://ng1.17img.cn/bbsfiles/images/2019/08/201908161626000014_401_3237657_3.png!w622x370.jpg[/img][/align][align=center]图4-5 不同血浆蛋白含量的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模结果比较[/align][align=center][b] [/b][/align][b]5小结[/b]本文基于吸光度浓度变化率来对校正样品集中所有样品进行波段选择;其过程为:预先设定校正样品集中共有n个样品,每个样品光谱中共有N个变量,对于校正样品集所有样品来说,每个变量则有n个吸光值和n个浓度值;其中,N和n均为大于1的正整数;依次计算每个变量下相邻样品的吸光值差值和浓度差值的比值V,最终在每个变量下得到(n-1)个比值V,再计算所有比值V的平均值V[sub]mean[/sub];对于校正样品集中样品光谱的N个变量,得到N个V[sub]mean[/sub]值,将N个变量按照其V[sub]mean[/sub]值进行排序;按照V[sub]mean[/sub]值由大变小的顺序依次选择出相应变量,直至所有变量全部选完,停止建模,记录所有情况的建模结果。同常规波段选择方法比较,该方法从三个方面进行了改进,不仅减少了参与[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]建模变量的数目,提高了[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型的预测能力。丰富了[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型的波段选择方法,给[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]模型使用者提供“吸光度-浓度变化”波段选择方法。同时由于是根据物质的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]吸光度和浓度的关系建立的波段选择方法,某种程度上,该方法更能够反应物质的化学信息,即吸光度随着浓度变化率,使得该波段选择方法具有广泛的可行性和通用性。
[b][b][color=#008000]设计原理[/color][color=#008000]:[/color][/b][/b]紫外可见分光光度计是基于紫外可见分光光度法原理,利用物质分子对紫外可见光谱区的辐射吸收来进行分析的一种分析仪器。主要由光源、单色器、吸收池、检测器和信号处理器等部件组成。光源的功能是提供足够强度的、稳定的连续光谱。紫外光区通常用氢灯或氘灯。见光区通常用钨灯或卤钨灯。单色器的功能是将光源发出的复合光分解并从中分出所需波长的单色光。色散元件有棱镜和光栅两种。可见光区的测量用玻璃吸收池,紫外光区的测量须用石英吸收池。检测器的功能是通过光电转换元件检测透过光的强度,将光信号转变成电信号。常用的光电转换元件有光电管、光电倍增管及光二极管阵列检测器。分光光度计的分类方法有多种:按光路系统可分为单光束和双光束分光光度计;按测量方式可分为单波长和双波长分光光度计;按绘制光谱图的检测方式分为分光扫描检测与二极管阵列全谱检测。[align=left]可见分光光度计(又名可见光度计、分光光度计)是可见光分光光度法是采用新型单片机技术,开发出能够进行定量测量(标准曲线测量,可对物质进行浓度直读);OD值直接测量(吸光度、透过率和能量等直读);动力学测试(测出物质浓度随时间变化OD值的变化);光谱扫描(可以对某一种物质进行全波段扫描,分析物质的特征波长,判断实验过程的误差);多波长测试(可以对物质同时进行多个波长的测试,分析物质的相关特性);还有可以进行DNA蛋白质测试、总磷总氮测试、重金属测试、农药残留测试、食品安全检测、热力发电金属离子测试等。[/align] [b][color=#008000]波长范围[/color][/b]可见分光光度计的波长适用范围一般从350nm左右开始到1100nm左右,紫外可见分光光度计的波长适用范围一般从190nm到1100nm。从这点区别上看就是波长的适用范围不一样,紫外可见分光光度计多了从190到350nm左右这段波长。[b][color=#008000]光源不同[/color][/b]可见分光光度计的光源一般只用钨灯,而紫外可见分光光度计是用钨灯 氘灯两个光源,同时还多了这两个光源灯的切换部件。这是因为钨灯的光谱范围主要在可见到近红外这段,氘灯主要在紫外端。也正是因为光源的不一样,紫外可见分光光度计也多了一个专门提供氘灯工作的氘灯电源了。[b][b][color=#008000]光学器件不同[/color][/b][/b]由于玻璃能吸收紫外波,而对可见到近红外端有比较好的透过性,所以可见分光光度计的一些光学部件可以使用玻璃,而紫外可见分光光度计就不能使用玻璃部件,一般使用石英光学部件。同时由于这个原因,在比色皿的选择上也就有不同了,可见分光光度计可以使用玻璃制的比色皿,而紫外可见分光光度计一般使用石英制的比色皿了。 [b][color=#008000]接收器不同[/color][/b]由于紫外可见分光光度计多了紫外波,所以在接收器的选择上也就不一样了。多了对紫外波的灵敏响应功能,这类接收器的价格就比可见分光光度计的接收器贵了很多了。
本人对紫外可见分光光度计测试薄膜材料的透过率有问题请教:用分光光度计测液体的浓度时要有空白样品进行标定,如果测在某个波段的薄膜样品的透过率,是否也需要标准样品进行标定阿?如果需要那一般采用什么样品?如果不需要那原因是什么?非常感谢!
本人需要一台只需要可见光部分的能全波段扫描的分光光度计,不知道各位大侠有没有这规格的仪器推荐?
[font=微软雅黑]可见分光光度计(又名可见光度计、分光光度计)是可见光分光光度法是采用新型单片机技术,开发出能够进行定量测量(标准曲线测量,可对物质进行浓度直读);OD值直接测量(吸光度、透过率和能量等直读);动力学测试(测出物质浓度随时间变化OD值的变化);光谱扫描(可以对某一种物质进行全波段扫描,分析物质的特征波长,判断实验过程的误差);多波长测试(可以对物质同时进行多个波长的测试,分析物质的相关特性);还有可以进行DNA蛋白质测试、总磷总氮测试、重金属测试、农药残留测试、食品安全检测、热力发电金属离子测试等。[/font][font=微软雅黑][/font][b][b][font=微软雅黑][color=#008000]波长范围[/color][/font][/b][/b][font=微软雅黑]可见分光光度计的波长适用范围一般从350nm左右开始到1100nm左右,紫外可见分光光度计的波长适用范围一般从190nm到1100nm。从这点区别上看就是波长的适用范围不一样,紫外可见分光光度计多了从190到350nm左右这段波长。[/font][font=微软雅黑][/font][b][b][font=微软雅黑][color=#008000]光源不同[/color][/font][/b][/b][font=微软雅黑]可见分光光度计的光源一般只用钨灯,而紫外可见分光光度计是用钨灯 氘灯两个光源,同时还多了这两个光源灯的切换部件。这是因为钨灯的光谱范围主要在可见到近红外这段,氘灯主要在紫外端。也正是因为光源的不一样,紫外可见分光光度计也多了一个专门提供氘灯工作的氘灯电源了。[/font][b][b][font=微软雅黑][color=#008000]光学器件不同[/color][/font][/b][/b][font=微软雅黑]由于玻璃能吸收紫外波,而对可见到近红外端有比较好的透过性,所以可见分光光度计的一些光学部件可以使用玻璃,而紫外可见分光光度计就不能使用玻璃部件,一般使用石英光学部件。同时由于这个原因,在比色皿的选择上也就有不同了,可见分光光度计可以使用玻璃制的比色皿,而紫外可见分光光度计一般使用石英制的比色皿了。[/font][font=微软雅黑][/font][b][b][font=微软雅黑][color=#008000]接收器不同[/color][/font][/b][/b][font=微软雅黑]由于紫外可见分光光度计多了紫外波,所以在接收器的选择上也就不一样了。多了对紫外波的灵敏响应功能,这类接收器的价格就比可见分光光度计的接收器贵了很多了。[/font]
请问一下论坛的大神:我用紫外分光光度计测医疗器械在波段250nm-320nm以及230nm-360nm两个波段内,测量的主要是什么物质?谢谢!
请问一下论坛的大神:我用紫外分光光度计测医疗器械在波段250nm-320nm以及230nm-360nm两个波段内,测量的主要是什么物质?谢谢!
我们想要购买一台分光光度计,要求:进口,波段范围约200nm~1000nm,我们主要测试溶液,请加大推荐一款,在此感谢~
今天对淀粉样进行400-900nm光谱扫描,所得结果和文献上基本一致,但在波长为530左右时吸光度骤然下降,一直持续到423nm之后又升高。换了多个样品都是一样的趋势,让后自己在可见光分光度计上重复测了这一段波长的吸光度发现紫外可见光分光光度计比可见光光度计在这一波段的吸光值低了0.035左右。个人觉得是紫外可见分光光度计没调试好,或者是仪器有问题,但不知道该如何处理。。。。。
用tu-1901紫外分光光度计在空白校准的时候发现在423-530nm波段出现整体下滑的现象,试过定波长在546nm处,有清晰的绿光斑,样品支架没有挡光;试过在800-360nm做钨灯能量曲线,发现在这个波段就出现明显的整体下滑现象。这是不是说明钨灯光源出现问题?还是仪器的其他问题?请指教!
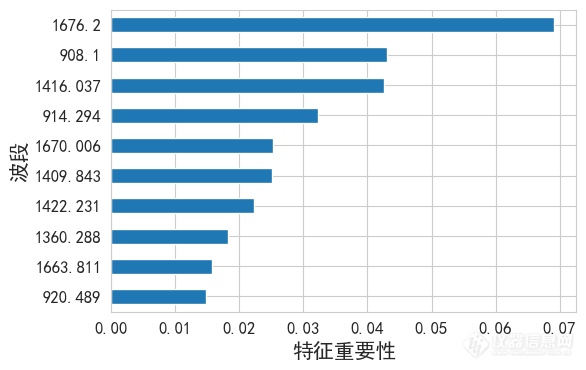
[font='times new roman'][size=16px][b]几种[/b][/size][/font][font='times new roman'][size=16px][b]波段选择[/b][/size][/font][font='times new roman'][size=16px][b]方法原理及应用[/b][/size][/font][size=14px][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据的波段数有[/size][size=14px]多[/size][size=14px]个,特征维度较多,数据量较大,不同波段之间的信息冗余度高,具有一定的重叠性。本实验所用的试验样品是由多个成分组成的混合物,这样采集的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]就会由于没有混合均匀等原因常常掺杂着一些对非目标组分的吸收,导致光谱数据中的某些波段与样品的性质之间是比较差的关联关系,甚至是有一些关联关系是错误的,这就容易出现部分波段信息冗余的现象。同时,也会有其他一些因素对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的准确性产生不利影响。[/size][size=14px]因此,为了得到更加有利于建立模型的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据,需要对一些无用的噪声波段进行剔除,找出那些含有较高信息量、容易分离、彼此相关度较低的波段,这就需要对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]进行波段选择。通过波段选择从原始[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]中选择包含大量有效信息的波段子集,这些波段在建模中起主要作用,这样不但可以大大降低[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的维度,提高模型建立的速度,而且可以将光谱中存在的噪声信息剔除掉,只保留对提升模型准确性有利的信息。本文使用的波段选择方法使皮尔森相关系数法和随机森林法。[/size][font='times new roman'][size=16px][b]皮尔森相关系数法[/b][/size][/font][size=14px]相关系数法[/size][font='times new roman'][size=14px][54][/size][/font][size=14px]是将采集光谱的所有波段与颗粒的实际水分含量进行相关性计算,得到光谱每个波段与水分含量的相关系数。确定一定的阈值,将波段按照相关系数绝对值的大小进行排序,相关系数的绝对值超过阈值大小的波段保留下来,用这部分波段进行建模。[/size][size=14px]两个变量之间相关系数的大小在[/size][size=14px]-1~1[/size][size=14px]之间变化,当其中一个变量增大而另一个变量减小时,说明两个变量是负相关的,其相关系数为负数,并且相关系数越小,说明两个变量的负相关性越大;当其中一个变量增大,另一个变量也随之增大时,说明两个变量是正相关的,相关系数为正数,并且相关系数越大,说明两个变量间的正相关性越大。为了了解两个变量间的相关程度,以相关系数的绝对值[/size][size=14px]|R|[/size][size=14px]为标准判断两个变量的线性相关性大小,如下表所示。[/size][align=center][font='times new roman'][size=16px]表两个变量的相关性大小[/size][/font][/align][table][tr][td][align=center][font='times new roman'][size=16px]相关系数绝对值[/size][/font][font='times new roman'][size=16px]|R|[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]相关性程度[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]≥[/size][/font][font='times new roman'][size=16px]0.95[/size][/font][/align][/td][td][align=center][size=13px]显著性相关[/size][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]≥[/size][/font][font='times new roman'][size=16px]0.8[/size][/font][/align][/td][td][align=center][size=13px]高度相关[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.5[/size][font='宋体'][size=13px]≤|[/size][/font][font='宋体'][size=13px]R[/size][/font][size=13px]|0.35[/size][/font][font='times new roman'][size=16px]光谱波段[/size][/font][/align][size=14px] [/size][size=14px] [/size][size=14px]图中,绿色方格线覆盖的波段为相关系数绝对值[/size][size=14px]|R|[/size][size=14px]0.35[/size][size=14px]的波段。图中可以看出,与水分相关系数比较高的地方都在波段[/size][size=14px]908.1nm~1400nm[/size][size=14px]之间,将全光谱的[/size][size=14px]125[/size][size=14px]个波段降低到了[/size][size=14px]80[/size][size=14px]个。[/size][font='times new roman'][size=16px][b] [/b][/size][/font][font='times new roman'][size=16px][b]随机森林法[/b][/size][/font][size=14px]随机森林[/size][font='times new roman'][size=14px][55][/size][/font][size=14px]是一种并行的[/size][size=14px]bagging[/size][font='times new roman'][size=14px][56][/size][/font][size=14px]集成学习算法。随机森林使用的数据采集方法为“自助采样法”,自主采样法在数据集较小的情况下会有较好的训练结果。从一个包含[/size][size=14px][i]n[/i][/size][size=14px]个[/size][size=14px]样本的数据集[/size][size=14px][i]M[/i][/size][size=14px]中每次随机取出一个样本,对样本进行记录后把该样本重新放回[/size][size=14px][i]M[/i][/size][size=14px]中再进行随机取样,即有放回的随机取样,这样取出来的所有样本组成数据集[/size][size=14px][i]D[/i][/size][size=14px]。重复采样[/size][size=14px][i]n[/i][/size][size=14px]次,[/size][size=14px][i]M[/i][/size][size=14px]中有一部分数据在[/size][size=14px][i]D[/i][/size][size=14px]中重复出现多次,有一部分数据从来没有在[/size][size=14px][i]D[/i][/size][size=14px]中出现过,一个样本被取到的概率为[/size][size=14px]1/[/size][size=14px][i]n[/i][/size][size=14px],那么在[/size][size=14px][i]n[/i][/size][size=14px]次采样过程中样本一直不被取到的概率为([/size][size=14px]1-1/[/size][size=14px][i]n[/i][/size][size=14px])[/size][font='times new roman'][size=14px]1/[/size][/font][font='times new roman'][size=14px][i]n[/i][/size][/font][size=14px],通过求极限可以得到[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]以采集的样本[/size][size=14px][i]D[/i][/size][size=14px]作为训练集,以未采集的样本数据集[/size][size=14px][i]P[/i][/size][size=14px]作为测试集。对数据集[/size][size=14px][i]D[/i][/size][size=14px]进行训练,并在训练过程中加入随机属性选择,这样就得到了一个决策树算法的[/size][size=14px]基学习器[/size][size=14px],然后把所有的[/size][size=14px]基学习器[/size][size=14px]组合起来,得到输出结果。在分类任务中,对每个[/size][size=14px]基学习器[/size][size=14px]对预测结果进行投票得到输出结果;在回归任务中,将每个[/size][size=14px]基学习器[/size][size=14px]的预测结果进行简单平均,求得的平均数作为最终的结果。[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]水分预测是一个回归任务,因此选择随机森林回归法,[/size][size=14px]基学习器[/size][size=14px]的决策树为回归树,训练样本过将多个[/size][size=14px]基学习器回归[/size][size=14px]树进行训练,使用简单平均法获得预测结果,获得比单一回归树模型具有更高的预测准确率[/size][font='times new roman'][size=14px][57][/size][/font][size=14px]。随机森林回归的示意图如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林回归示意图[/size][/font][/align][size=14px]随机森林回归算法中使用的基模型为[/size][size=14px]CART[/size][size=14px]回归树[/size][font='times new roman'][size=14px][58][/size][/font][size=14px],特征空间的划分和每个单元的输出值由这些回归树来决定。在回归树中,选择最佳的划分点需要对每个特征的所有值进行遍历,直到取得某个特征的某个值,使得损失函数最小,这就是最佳的划分点。假设有[/size][size=14px][i]n[/i][/size][size=14px]个[/size][size=14px]特征,每个特征有[/size][size=14px]个[/size][size=14px]取值,将特征空间划分为[/size][size=14px][i]M[/i][/size][size=14px]个[/size][size=14px]单元[/size][size=14px],[/size][size=14px]为[/size][size=14px]上输入[/size][size=14px]对应[/size][size=14px]的平均值,[/size][size=14px]则该过程的公式如下:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]选择最佳的划分点后,回归树的方程为:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]式中,[/size][size=14px][i]I([/i][/size][size=14px][i]x)[/i][/size][size=14px]为指示函数。[/size][size=14px]通过随机森林计算特征集中某一特征重要程度的过程如下:[/size][size=14px]([/size][size=14px]1[/size][size=14px])从数据集[/size][size=14px][i]M[/i][/size][size=14px]中通过随机自采样的方法获得数据集[/size][size=14px][i]D[/i][/size][size=14px],用数据集[/size][size=14px][i]D[/i][/size][size=14px]作为训练集进行建模,用没采集到的数据集[/size][size=14px][i]P[/i][/size][size=14px]进行验证,得到数据集[/size][size=14px][i]P[/i][/size][size=14px]的误差,记作[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]。[/size][size=14px]([/size][size=14px]2[/size][size=14px])生成一组随机噪声数据,将随机噪声干扰数据加入到数据集[/size][size=14px][i]P[/i][/size][size=14px]的某一特征中,使得该特征对预测结果产生干扰,然后再次对数据集[/size][size=14px][i]P[/i][/size][size=14px]的误差进行计算,记作[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]。[/size][size=14px]([/size][size=14px]3[/size][size=14px])计算[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]与[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]的差值。如果该特征是对预测结果起正向作用,则加入噪声数据后[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]与[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]的差值一定大于[/size][size=14px]0[/size][size=14px],反之则小于零。差值与这个特征对该模型预测精度的影响程度成正比。[/size][size=14px]([/size][size=14px]4[/size][size=14px])如果随机森林中有[/size][size=14px][i]N[/i][/size][size=14px]棵树,计算[/size][size=14px][i]N[/i][/size][size=14px]棵树对该特征[/size][size=14px][i]error2[/i][/size][size=14px]与[/size][size=14px][i]error1[/i][/size][size=14px]的差值的平均值,即[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]([/size][size=14px]5[/size][size=14px])遍历数据集[/size][size=14px][i]P[/i][/size][size=14px]中的所有特征,求出每个特征的重要性。[/size][size=14px]用随机森林回归法对光谱数据与水分含量进行建模,得到数据[/size][size=14px]中特征[/size][size=14px]重要性排名,其中排名前十的特征如图[/size][size=14px]3-9[/size][size=14px]所示。[/size][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031753099412_7932_3890113_3.png[/img][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林特征选择排名前十的特征[/size][/font][/align][size=14px]特征重要性值的数据分布如下表所示。[/size][align=center][font='times new roman'][size=16px]表[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林特征重要性分布[/size][/font][/align][table][tr][td][align=center][font='times new roman'][size=16px]数值分布[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]特征重要性[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]最小值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0022[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]1/4[/size][/font][font='times new roman'][size=16px]分位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0041[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]中位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0060[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]3/4[/size][/font][font='times new roman'][size=16px]分位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0081[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]最大值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0692[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]平均值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0080[/size][/font][/align][/td][/tr][/table][size=14px]分别以随机森林特征重要性数值分布的[/size][size=14px]1/4[/size][size=14px]分位数、中位数、[/size][size=14px]3/4[/size][size=14px]分位数和平均值为选择标准,以大于这个标准的特征重要性组合成的特征波段进行[/size][size=14px]PLS[/size][size=14px]建模,选择最佳的波段组合。建模的结果如下表所示。[/size][align=center][font='times new roman'][size=16px]表[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]不同特征重要性的波段模型评价[/size][/font][/align][table][tr][td][align=center][size=13px] [/size][size=13px] [/size][size=13px]评价参数[/size][/align][size=13px]特征重要性[/size][/td][td][align=center][size=13px]R[/size][size=13px]MSECV[/size][/align][/td][td][align=center][size=13px]R[/size][size=13px]MSEP[/size][/align][/td][td][align=center][size=14px]R[/size][font='times new roman'][size=14px]p[/size][/font][/align][/td][/tr][tr][td][align=center][size=13px]全波段[/size][/align][/td][td][align=center][size=13px]0.242[/size][/align][/td][td][align=center][size=13px]0.221[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]60[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0041[/size][/align][/td][td][align=center][size=13px]0.222[/size][/align][/td][td][align=center][size=13px]0.214[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]80[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0060[/size][/align][/td][td][align=center][size=13px]0.216[/size][/align][/td][td][align=center][size=13px]0.209[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].[/size][size=13px]983[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0080[/size][/align][/td][td][align=center][size=13px]0.228[/size][/align][/td][td][align=center][size=13px]0.225[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]75[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0081[/size][/align][/td][td][align=center][size=13px]0.2[/size][size=13px]3[/size][size=13px]2[/size][/align][/td][td][align=center][size=13px]0.230[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]6[/size][/align][/td][/tr][/table][size=14px]很明显,通过随机森林方法计算出各个特征的重要性,以[/size][size=14px]0.0060[/size][size=14px]作为最低标准选择的波段用来建立[/size][size=14px]PLS[/size][size=14px]模型的效果最好。选择的波段如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林波段选择[/size][/font][/align][size=14px] [/size][size=14px] [/size][size=14px]图中绿色背景的是通过随机森林选择的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]波段,其波段主要分布在[/size][size=14px]908.1nm~1150nm[/size][size=14px]和[/size][size=14px]1350nm~1500nm[/size][size=14px]之间,将[/size][size=14px]125[/size][size=14px]个光谱波段降低到了[/size][size=14px]60[/size][size=14px]个,[/size][size=14px]降维效果[/size][size=14px]和模型评价效果均优于相关系数法。因此在流化床制粒过程[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的建模中应用随机森林法进行波段选择。[/size]
有没有好用的国产紫外/可见/近红外分光光度计可以推荐的啊? 200 nm - 2500 nm 或者 更长波段的。
实验室想买一台紫外可见光度计,主要用于中药成分的定性定量检测,仪器具备全波段扫描功能,双波长、二阶导数检测。能与电脑联机,带功能强大的分析软件最好。
中国科技网讯 据物理学家组织网日前报道,美国能源部斯坦福直线加速器中心国家加速器实验室的研究人员,采用金刚石细薄片把直线加速器的相干光源转化为手术刀般更精确的工具,以探测纳米世界。改进后的激光脉冲可在X射线波长更窄频带高强度聚焦,开展以前所不能为的实验。该研究结果刊登在《自然·光子学》杂志上。 这个过程被称为“自激注入”,金刚石将激光束过滤为单一的X射线颜色,然后将其放大。研究人员可以在原子水平研究和操纵物质上有更强的能力,传送更为清晰的物质、分子和化学反应的影像。 人们谈论“自激注入”已经近15年,直到2010年斯坦福线性加速器中心成立时,才由欧洲自由电子激光器和德国电子加速器研究中心的研究人员提出,并由来自斯坦福线性加速器中心和阿贡国家实验室的工程队伍将其建立。“自激注入”可潜在地产生更高强度的X射线脉冲,显著高于目前直线加速器相干光源的性能。每个脉冲增加的强度可以用来深入探测复杂的材料,以帮助解答诸如高温超导体等特殊物质或拓扑绝缘体中复杂电子态等问题。 直线加速器相干光源通过接近光速的电子群加速激光束,用一系列磁体将其设定为“之”字路径。这将迫使电子发射X射线,聚集成亮度超过之前10亿倍的激光脉冲。如果没有“自激注入”,这些X射线激光脉冲包含的波长(或颜色)范围比较宽,无法被所有的实验使用。之前在直线加速器相干光源创造更窄波段(即更精确波段)的方法则会导致大量的强度损失。 研究人员在可产生X射线的130米长磁体的中间段安装了一片金刚石晶体,由此创建了一个精确的X射线波段,并且使直线加速器相干光源更像是“激光”。该中心物理学家黄志荣(音译)说:“如果我们完成系统的优化,并添加更多的波荡,所产生的脉冲集中的强度将达10倍之多。”目前世界各地的相关实验室已经趋之若鹜,计划将这一重要进展与自身的X射线激光设施相结合。(记者 华凌) 《科技日报》(2012-09-17 二版)
近期一个朋友问了一个问题,为何大多数的紫外-可见分光光度计在做波长扫描时,是由长波向短波方向扫描?因为红外及荧光是从短波向长波方向扫描。不知是否所有厂家的紫外-可见分光光度计均是如此扫描?
分光光度计是利用物质对光的选择性吸收的特性,以较纯的单色光作为入射光,测定物质对光的吸收,从而对物质进行定性或定量分析的仪器。在使用过程中常常会出现测量误差,这些误差又是如何产生的呢?一、仪器本身性能带来的误差1、复色光对比耳定律的偏离比耳定律成立的前提条件是入射光是单色光,但是精度再高的仪器,即使是双单色器的分光光度计,也只能获得近乎单色的光,无法获得纯单色光,它仍然含有狭窄光通带,具有复色光的性质。而复色光会导致比耳定律的正或负偏离。固定狭缝的紫外分光光度计光谱带宽一般为1nm或2nm,可调狭缝的可以做到0.1nm;可见分光光度计带宽6nm、snm,甚至十几纳米。光谱带宽应该是越小越好,但是随着光谱分辨率的提高,仪器的灵敏度降低,所以选择仪器时要综合考虑各种条件的影响。当溶液浓度较小且单色光较纯时,可近似认为符合比耳定律。2、杂散光的影响杂散光是指进入检测器的处于待测波长光谱带宽范围外的其他波长组分,它是光谱测量中误差的主要来源。产生原因有:分光光度计的色散元件、反射镜、透镜及单色器内壁灰尘等。在分光光度计工作波段边缘波长处,由于单色器透光率、光源辐射强度、检测器灵敏度都较低,杂散光的影响更为显著。杂散光限制仪器的分析上限可引起严重的测量误差,实际工作中,在定量分析时,一般在吸收峰或其附近处测量样品吸光度,如果在分析波长处含有杂散光,这时样品的透光率较小,而杂散光大部分透过,使测量吸光度低于真实吸光度。3、仪器噪声对测t的影响仪器噪声也是仪器的一个重要指标,它表征仪器做稀溶液的能力。是叠加在待测量的分析信号中的不需要的信号,扫描100%T和0%T线,可观察到分光光度计的绝对噪声水平,如果仪器噪声较大,会掩盖较小的测量信号,一般用噪音的二倍来表示仪器的灵敏度。4、波长和吸光度准确度样品的每一个值都是在一定的波长下测得的,如果波长误差很大,测出的值肯定不准。吸光度准确度也是用户对仪器的直接要求,更应引起足够的重视。国家计量检定规程规定双光束紫外可见分光光度计透射比准确度为A级士0.6%, B级土1.0%。二、测量条件的选择1 参比溶液和溶剂的选择分光光度计的测量实际上是以通过参比池的光强度作为入射光强度来测定试样的吸光度,先调节仪器使透过参比池溶液的吸光度为零,然后让同一束光通过样品,使得吸光度比较真实地反映待测物质的浓度,所以参比溶液的选择非常重要。如果仅有待测物质与显色剂的反应产物有吸收,可用纯溶剂或蒸馏水作参比溶液。如果显色剂有颜色,并在测定波长下有吸收,则用显色剂溶液作参比溶液,所加人显色剂及其它试剂的量,与试样中的加入量应一致。如果样品中其它组分本身的颜色对测定有干扰,而所用显色剂没颜色,则用不加显色剂的样品溶液作参比液。正确选择合适的溶剂,对提高分析的准确度起重要作用。为减小溶剂中杂质的影响,应选择高纯度的溶剂;溶剂应不与待测物质发生化学反应;待测物在溶剂中要有一定的溶解度;在测定的波长范围内,溶剂本身没有吸收,注意常用溶剂的最短可用波长;当用挥发性大的溶剂时,测量过程中吸收池应加盖。2 测试波长的选择当用分光光度计对溶液进行测定时,首先需要选择合适的测量波长。选择的依据是该被测溶液的吸收曲线。在一般情况下,我们总是选择最大吸收波长作为测量波长,这样可以提高灵敏度。而在有些情况下最大吸收峰很尖锐、吸收过大或附近有干扰存在,就不能选最大吸收波长,而必须在保证有一定灵敏度的情况下,选择吸收曲线中的其它波长进行测定(曲线较平坦处对应的波长),以消除干扰。绘制吸收曲线是正确选择波长的有效手段和方法。
1.2杂散光的影响杂散光是指进人检测器的处于待测波长光谱带宽范围外的其他波长组分,它是光谱测量中误差的主要来源。产生原因有:分光光度计的色散元件、反射镜、透镜及单色器内壁灰尘等。在分光光度计工作波段边缘波长处,由于单色器透光率、光源辐射强度、检测器灵敏度都较低,杂散光的影响更为显著。杂散光限制仪器的分析上限可引起严重的测量误差,实际工作中,在定量分析时,一般在吸收峰或其附近处测量样品吸光度,如果在分析波长处含有杂散光,这时样品的透光率较小,而杂散光大部分透过,使测量吸光度低于真实吸光度。







 我要推广仪器
我要推广仪器
 下载APP
下载APP