[font=&]【题名】: 一种多波段紫外消色差光学系统[font=Arial, Helvetica, sans-serif, ????][size=12px][/size][/font][/font][font=&]【链接】: https://xueshu.baidu.com/usercenter/paper/show?paperid=1v560tb01a2h02a0h96s0270us666620[/font]
哪些波段的波属于噪声?
在直读光谱仪的实际应用中,如C、P、S、As等元素的最优光谱线均在真空紫外波段,而空气中的氧气及水蒸气等会对这些谱线产生强烈的吸收,使光谱强度急剧减弱,影响元素测量,所以应当将光室中的空气除去。 目前主流市场上主要有两种方式可以实现真空紫外波段元素的测量,光室抽真空或充惰性气体(如氩气、氦气等)。 抽真空型的直读光谱仪需要用额外的真空泵,存在油蒸汽污染严重、噪音大等环境问题。同时,功耗高、真空稳定速度慢,仪器需长期开机,浪费严重。 光室充惰性气体能实现真空紫外探测能力的同时,还具有稳定时间短,无噪音等优点,且能避免由于真空系统造成的光室变形、仪器漂移和环境污染等问题,目前,市场主流光谱仪多采用CCD传感器作为检测装置,光室体积可做到很小,更有利于惰性气体环境建立,从而得到更好的紫外元素分析效果,且该项技术已经过十多年市场验证,稳定可靠。
紫外消毒灯 是检测那个波段的紫外线波长呢?
如题,哪位大大知道气体分子 在红外(8-14um波段),谁不同波长变化的 摩尔吸收系数啊,我用omnic能够查到归一化之后的吸收,我想知道具体的摩尔吸收系数怎么查啊,要对应多波段你的,不要某些波段的,比如说NH3,在8-14um之前对应的几百个波长与之对应的摩尔吸收系数怎么查,我觉得应该有这样的数据库吧,不知道怎么查,有知道的告诉一下,不胜感激
请问,在NIR中,全波段翻译成英语的地道说法应该怎么翻译:有道翻译结果:full-wave bandall bandfull range感觉不太准确和专业
对于 400~30cm-1 波段,该怎么指认图谱?各位大虾有没有什么好的建议啊?中文文献都没怎么看到相关的内容,还能像中红外波段那样考虑原子基团或者特别的骨架震动之类的原因吗?另外,这一波段内哪些波数是对应 1~3THz 的啊?
做[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]霉变检测,运用特征提取方法获取了一些波段,如1172nm,1902nm等,看文献中都有对波段的分析,比如该波段是由哪个基团的什么运动引起的,对应于什么物质(碳水化合物,水分,油),想请教下这些东西是怎么分析出来的,或者有大牛能否帮忙分析下我的特征波段,万分感谢!
想测试一个UV光源的波段是多少,需要用什么仪器?
[font=宋体]可以采用波长选择方法选择光谱中与目标组分相关的变量。目前,发展了很多波长选择方法,概括起来它们可以分为三大类:波长点选择、波段选择和变量加权的方法。波长点选择方法包括基于单一指标的方法、基于统计学的方法和基于智能优化算法的方法等;波段选择方法主要包括间隔偏最小二乘法、移动窗口偏最小二乘法及它们的衍生化方法;变量加权的方法是波长选择方法的发展与[/font][font=宋体][font=宋体]扩充,它使用全部的波长点,但是给每个变量赋予不同的权重,有变量加权的[/font][font=Times New Roman]PLS[/font][font=宋体]和变量加权的[/font][font=Times New Roman]SVR[/font][font=宋体]等方法。具体方法参考本章第[/font][font=Times New Roman]5[/font][font=宋体]节。[/font][/font]
领导想要买一个光谱仪 测试远红外灯发出的红外线波段 哪位大神可以推荐下吗?
如题, 最近看了近红外的应用, 对于不同的测量对象,利用的近红外的波段也不同? 那么选取波段上依据什么进行?另外有人知道怎么从OPUS 中得到具体的化学成分的含量?大牛指导下,谢谢了
本人现在做近红外光谱,正在学习用MATLAB对光谱数据进行特征波段的选取,哪位大侠教下我啊?有酬谢!有意的加我Q1355008248!
现在做实验,老板让我查一下以下气体在可见光波段的吸收谱,二氧化碳,二氧化硫,臭氧,甲烷等。我在网上找了狠多,都没有发现结果,那位大哥帮帮忙给弄一下啊,谢谢了另外,那个附图是我用NIST MS Search查到的光谱图,但是横坐标为什么没有光谱单位呢??
听说dad检测器可以进行全波段检测,我设定了光谱范围为“ALL”,测定波长为275nm,那么,在agilent 1100 chemsation中,别的波段的色谱图怎么调出来,请指点,急用!!!!
请问哪里可以做2-5μm波段的荧光光谱?激发光源1550nm或者OPO光源1800nm,联系了很多地方都做不了,要是有大神知道希望告知一下,感激不尽!
光谱的全波段波长指的是什么?包含哪些波长的光?
紫外线传感器是传感器的一种,可以利用光敏元件通过光伏模式和光导模式将紫外线信号转换为可测量的电信号,目前紫外线传感器材料主要是GaN和SiC这两大类。GaN材质的传感器目前知名度比较高的是韩国Genicom的紫外线传感器,传感器的波段从200-510nm均有相对应的传感器来检测。针对UVA波段,主要有IIC、电流、电压输出方式的传感器。在智能穿戴以及一些要求传感器体积尽可能小或者对PCB尺寸要求比较小的场所可以使用GUVA-C32SM或者GUVA-S12SD(SMD3528封装)。针对一些要求温度稳定性比较高的场所,还有金属TO-46(GUVA-T11GD-L)、TO-39(GUVA-T21GD-U)、TO-5(GUVA-T21GH)封装产品。TO-5封装的产品里面都集成了运算放大电路,0-5V模拟量输出。方便使用。主要运用于UVA灯的检测,UV固化等。UVB传感器主要是用于检测B波段的LED灯、皮肤光疗仪以及UVI检测。UVI指数指标主要是针对B波段的紫外线而言的。主要运用到的型号有GUVB-C31SM(IIC输出)、GUVB-T11GD-L(电流输出)、GUVB-T21GH(0-5V输出)。UVC传感器由于具有日盲特性,除了用于紫外线消毒监测上,还可以用于火焰探测。火焰探测的前提条件是传感器能够检测极低辐射强度的紫外线,同时传感器的暗电流必须非常低,这样SiC材质的传感器就能满足需求目前知名度比较高的是德国Sglux的SiC紫外线传感器。该类型传感器能够耐高温以及强紫外线辐射。该厂商的传感器代表型号有SG01D,该传感器TO-5封装,带有聚光镜,在10uw/cm2辐射强度下可以输出350nA的电流。感光芯片面积可以从0.06mm2~36mm2。同时该产商TOCON-ABC系列可以在1.8pw/cm2~18w/cm2的范围内都有相对应的传感器来监测,能应对各种各样的需求。
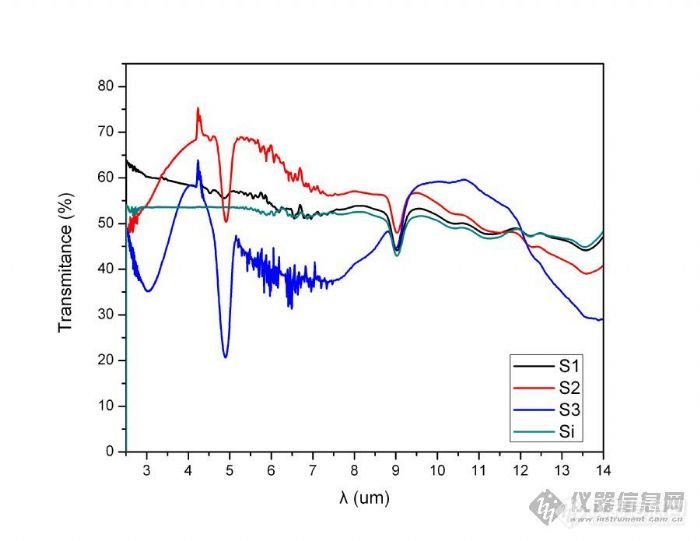
最近做的红外透过光谱,样品是沉积了一层薄膜(约800nm)的双抛的单晶硅片,结果一看样品的透过率比硅片的透过率还高(样品的谱线没有扣除衬底硅的影响),这种现象是不是说明薄膜有增透的作用,还有其他原因会产生这种现象吗?还有,样品35~8um波段的谱线波动的这么厉害是什么原因造成的?[img]http://ng1.17img.cn/bbsfiles/images/2009/09/200909061311_169972_1855701_3.jpg[/img]
怎样获取叶片的最佳波段?
请那位老师告诉我,甲醇在紫外上有吸收波段吗???[em53]
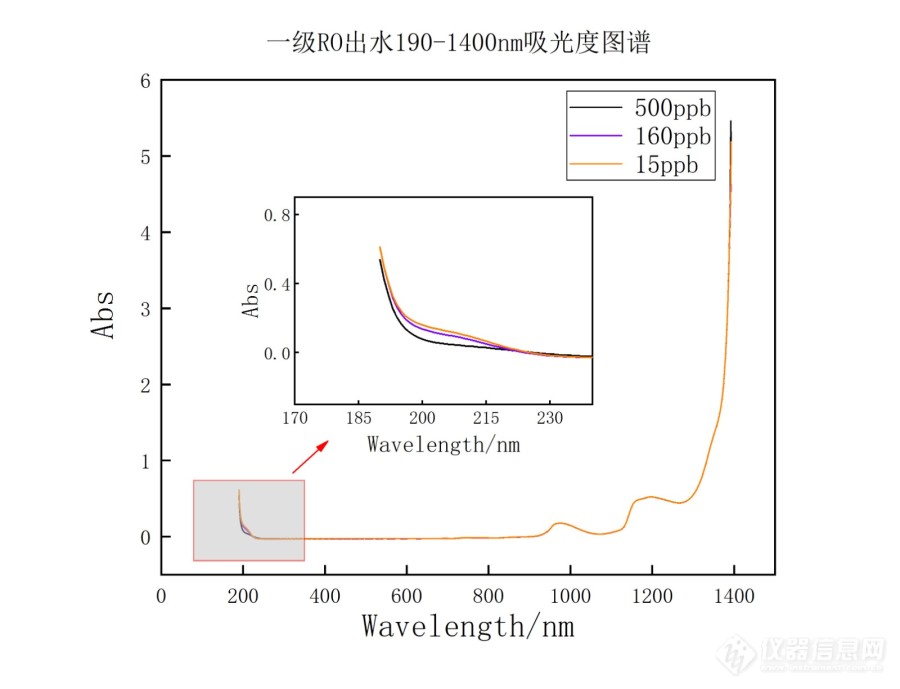
[size=24px]电子级水/超纯水 远紫外波段吸光度检测[/size]请教各位大神,对于类似超纯水、半导体行业用水这种水质指标极高的水,远紫外波段(<200nm)吸光度应该如何检测?有几个疑问,请论坛大神解答;1.远紫外波段真空紫外光易被空气吸收,且光程短,如何适配比色皿,排除空气干扰?2.类似安捷伦、lambda这些仪器为什么标称170nm-3300nm都可以检测,但是实际应用中最低只能检测到190nm处?3.为获得特定波长处(如185nm,超纯水TOC降解波段)吸光度,该如何实现?[img=,690,528]https://ng1.17img.cn/bbsfiles/images/2023/03/202303291111198785_2326_5961157_3.jpg!w690x528.jpg[/img]
请问红外1726的波段属于什么基团吸收?样品是混合物,不确定呢!我没图,但急着要.小女子提前谢谢大虾们啦!!!
各位高工!光谱仪的波段范围 190-500nm是什么意思啊!它起什么作用,要怎么选择啊!!!
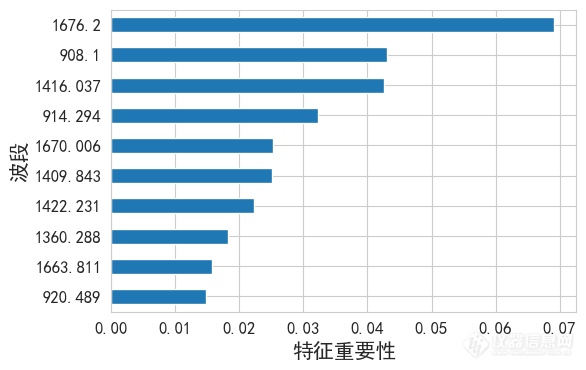
[font='times new roman'][size=16px][b]几种[/b][/size][/font][font='times new roman'][size=16px][b]波段选择[/b][/size][/font][font='times new roman'][size=16px][b]方法原理及应用[/b][/size][/font][size=14px][url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据的波段数有[/size][size=14px]多[/size][size=14px]个,特征维度较多,数据量较大,不同波段之间的信息冗余度高,具有一定的重叠性。本实验所用的试验样品是由多个成分组成的混合物,这样采集的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]就会由于没有混合均匀等原因常常掺杂着一些对非目标组分的吸收,导致光谱数据中的某些波段与样品的性质之间是比较差的关联关系,甚至是有一些关联关系是错误的,这就容易出现部分波段信息冗余的现象。同时,也会有其他一些因素对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的准确性产生不利影响。[/size][size=14px]因此,为了得到更加有利于建立模型的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]数据,需要对一些无用的噪声波段进行剔除,找出那些含有较高信息量、容易分离、彼此相关度较低的波段,这就需要对[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]进行波段选择。通过波段选择从原始[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]中选择包含大量有效信息的波段子集,这些波段在建模中起主要作用,这样不但可以大大降低[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的维度,提高模型建立的速度,而且可以将光谱中存在的噪声信息剔除掉,只保留对提升模型准确性有利的信息。本文使用的波段选择方法使皮尔森相关系数法和随机森林法。[/size][font='times new roman'][size=16px][b]皮尔森相关系数法[/b][/size][/font][size=14px]相关系数法[/size][font='times new roman'][size=14px][54][/size][/font][size=14px]是将采集光谱的所有波段与颗粒的实际水分含量进行相关性计算,得到光谱每个波段与水分含量的相关系数。确定一定的阈值,将波段按照相关系数绝对值的大小进行排序,相关系数的绝对值超过阈值大小的波段保留下来,用这部分波段进行建模。[/size][size=14px]两个变量之间相关系数的大小在[/size][size=14px]-1~1[/size][size=14px]之间变化,当其中一个变量增大而另一个变量减小时,说明两个变量是负相关的,其相关系数为负数,并且相关系数越小,说明两个变量的负相关性越大;当其中一个变量增大,另一个变量也随之增大时,说明两个变量是正相关的,相关系数为正数,并且相关系数越大,说明两个变量间的正相关性越大。为了了解两个变量间的相关程度,以相关系数的绝对值[/size][size=14px]|R|[/size][size=14px]为标准判断两个变量的线性相关性大小,如下表所示。[/size][align=center][font='times new roman'][size=16px]表两个变量的相关性大小[/size][/font][/align][table][tr][td][align=center][font='times new roman'][size=16px]相关系数绝对值[/size][/font][font='times new roman'][size=16px]|R|[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]相关性程度[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]≥[/size][/font][font='times new roman'][size=16px]0.95[/size][/font][/align][/td][td][align=center][size=13px]显著性相关[/size][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]≥[/size][/font][font='times new roman'][size=16px]0.8[/size][/font][/align][/td][td][align=center][size=13px]高度相关[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.5[/size][font='宋体'][size=13px]≤|[/size][/font][font='宋体'][size=13px]R[/size][/font][size=13px]|0.35[/size][/font][font='times new roman'][size=16px]光谱波段[/size][/font][/align][size=14px] [/size][size=14px] [/size][size=14px]图中,绿色方格线覆盖的波段为相关系数绝对值[/size][size=14px]|R|[/size][size=14px]0.35[/size][size=14px]的波段。图中可以看出,与水分相关系数比较高的地方都在波段[/size][size=14px]908.1nm~1400nm[/size][size=14px]之间,将全光谱的[/size][size=14px]125[/size][size=14px]个波段降低到了[/size][size=14px]80[/size][size=14px]个。[/size][font='times new roman'][size=16px][b] [/b][/size][/font][font='times new roman'][size=16px][b]随机森林法[/b][/size][/font][size=14px]随机森林[/size][font='times new roman'][size=14px][55][/size][/font][size=14px]是一种并行的[/size][size=14px]bagging[/size][font='times new roman'][size=14px][56][/size][/font][size=14px]集成学习算法。随机森林使用的数据采集方法为“自助采样法”,自主采样法在数据集较小的情况下会有较好的训练结果。从一个包含[/size][size=14px][i]n[/i][/size][size=14px]个[/size][size=14px]样本的数据集[/size][size=14px][i]M[/i][/size][size=14px]中每次随机取出一个样本,对样本进行记录后把该样本重新放回[/size][size=14px][i]M[/i][/size][size=14px]中再进行随机取样,即有放回的随机取样,这样取出来的所有样本组成数据集[/size][size=14px][i]D[/i][/size][size=14px]。重复采样[/size][size=14px][i]n[/i][/size][size=14px]次,[/size][size=14px][i]M[/i][/size][size=14px]中有一部分数据在[/size][size=14px][i]D[/i][/size][size=14px]中重复出现多次,有一部分数据从来没有在[/size][size=14px][i]D[/i][/size][size=14px]中出现过,一个样本被取到的概率为[/size][size=14px]1/[/size][size=14px][i]n[/i][/size][size=14px],那么在[/size][size=14px][i]n[/i][/size][size=14px]次采样过程中样本一直不被取到的概率为([/size][size=14px]1-1/[/size][size=14px][i]n[/i][/size][size=14px])[/size][font='times new roman'][size=14px]1/[/size][/font][font='times new roman'][size=14px][i]n[/i][/size][/font][size=14px],通过求极限可以得到[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]以采集的样本[/size][size=14px][i]D[/i][/size][size=14px]作为训练集,以未采集的样本数据集[/size][size=14px][i]P[/i][/size][size=14px]作为测试集。对数据集[/size][size=14px][i]D[/i][/size][size=14px]进行训练,并在训练过程中加入随机属性选择,这样就得到了一个决策树算法的[/size][size=14px]基学习器[/size][size=14px],然后把所有的[/size][size=14px]基学习器[/size][size=14px]组合起来,得到输出结果。在分类任务中,对每个[/size][size=14px]基学习器[/size][size=14px]对预测结果进行投票得到输出结果;在回归任务中,将每个[/size][size=14px]基学习器[/size][size=14px]的预测结果进行简单平均,求得的平均数作为最终的结果。[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]水分预测是一个回归任务,因此选择随机森林回归法,[/size][size=14px]基学习器[/size][size=14px]的决策树为回归树,训练样本过将多个[/size][size=14px]基学习器回归[/size][size=14px]树进行训练,使用简单平均法获得预测结果,获得比单一回归树模型具有更高的预测准确率[/size][font='times new roman'][size=14px][57][/size][/font][size=14px]。随机森林回归的示意图如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林回归示意图[/size][/font][/align][size=14px]随机森林回归算法中使用的基模型为[/size][size=14px]CART[/size][size=14px]回归树[/size][font='times new roman'][size=14px][58][/size][/font][size=14px],特征空间的划分和每个单元的输出值由这些回归树来决定。在回归树中,选择最佳的划分点需要对每个特征的所有值进行遍历,直到取得某个特征的某个值,使得损失函数最小,这就是最佳的划分点。假设有[/size][size=14px][i]n[/i][/size][size=14px]个[/size][size=14px]特征,每个特征有[/size][size=14px]个[/size][size=14px]取值,将特征空间划分为[/size][size=14px][i]M[/i][/size][size=14px]个[/size][size=14px]单元[/size][size=14px],[/size][size=14px]为[/size][size=14px]上输入[/size][size=14px]对应[/size][size=14px]的平均值,[/size][size=14px]则该过程的公式如下:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]选择最佳的划分点后,回归树的方程为:[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]式中,[/size][size=14px][i]I([/i][/size][size=14px][i]x)[/i][/size][size=14px]为指示函数。[/size][size=14px]通过随机森林计算特征集中某一特征重要程度的过程如下:[/size][size=14px]([/size][size=14px]1[/size][size=14px])从数据集[/size][size=14px][i]M[/i][/size][size=14px]中通过随机自采样的方法获得数据集[/size][size=14px][i]D[/i][/size][size=14px],用数据集[/size][size=14px][i]D[/i][/size][size=14px]作为训练集进行建模,用没采集到的数据集[/size][size=14px][i]P[/i][/size][size=14px]进行验证,得到数据集[/size][size=14px][i]P[/i][/size][size=14px]的误差,记作[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]。[/size][size=14px]([/size][size=14px]2[/size][size=14px])生成一组随机噪声数据,将随机噪声干扰数据加入到数据集[/size][size=14px][i]P[/i][/size][size=14px]的某一特征中,使得该特征对预测结果产生干扰,然后再次对数据集[/size][size=14px][i]P[/i][/size][size=14px]的误差进行计算,记作[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]。[/size][size=14px]([/size][size=14px]3[/size][size=14px])计算[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]与[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]的差值。如果该特征是对预测结果起正向作用,则加入噪声数据后[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]2[/i][/size][/font][size=14px]与[/size][size=14px][i]error[/i][/size][font='times new roman'][size=14px][i]1[/i][/size][/font][size=14px]的差值一定大于[/size][size=14px]0[/size][size=14px],反之则小于零。差值与这个特征对该模型预测精度的影响程度成正比。[/size][size=14px]([/size][size=14px]4[/size][size=14px])如果随机森林中有[/size][size=14px][i]N[/i][/size][size=14px]棵树,计算[/size][size=14px][i]N[/i][/size][size=14px]棵树对该特征[/size][size=14px][i]error2[/i][/size][size=14px]与[/size][size=14px][i]error1[/i][/size][size=14px]的差值的平均值,即[/size][align=right][size=14px] [/size][size=14px] [/size][/align][size=14px]([/size][size=14px]5[/size][size=14px])遍历数据集[/size][size=14px][i]P[/i][/size][size=14px]中的所有特征,求出每个特征的重要性。[/size][size=14px]用随机森林回归法对光谱数据与水分含量进行建模,得到数据[/size][size=14px]中特征[/size][size=14px]重要性排名,其中排名前十的特征如图[/size][size=14px]3-9[/size][size=14px]所示。[/size][align=center][img]https://ng1.17img.cn/bbsfiles/images/2020/09/202009031753099412_7932_3890113_3.png[/img][/align][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林特征选择排名前十的特征[/size][/font][/align][size=14px]特征重要性值的数据分布如下表所示。[/size][align=center][font='times new roman'][size=16px]表[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林特征重要性分布[/size][/font][/align][table][tr][td][align=center][font='times new roman'][size=16px]数值分布[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]特征重要性[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]最小值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0022[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]1/4[/size][/font][font='times new roman'][size=16px]分位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0041[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]中位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0060[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]3/4[/size][/font][font='times new roman'][size=16px]分位数[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0081[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]最大值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0692[/size][/font][/align][/td][/tr][tr][td][align=center][font='times new roman'][size=16px]平均值[/size][/font][/align][/td][td][align=center][font='times new roman'][size=16px]0.0080[/size][/font][/align][/td][/tr][/table][size=14px]分别以随机森林特征重要性数值分布的[/size][size=14px]1/4[/size][size=14px]分位数、中位数、[/size][size=14px]3/4[/size][size=14px]分位数和平均值为选择标准,以大于这个标准的特征重要性组合成的特征波段进行[/size][size=14px]PLS[/size][size=14px]建模,选择最佳的波段组合。建模的结果如下表所示。[/size][align=center][font='times new roman'][size=16px]表[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]不同特征重要性的波段模型评价[/size][/font][/align][table][tr][td][align=center][size=13px] [/size][size=13px] [/size][size=13px]评价参数[/size][/align][size=13px]特征重要性[/size][/td][td][align=center][size=13px]R[/size][size=13px]MSECV[/size][/align][/td][td][align=center][size=13px]R[/size][size=13px]MSEP[/size][/align][/td][td][align=center][size=14px]R[/size][font='times new roman'][size=14px]p[/size][/font][/align][/td][/tr][tr][td][align=center][size=13px]全波段[/size][/align][/td][td][align=center][size=13px]0.242[/size][/align][/td][td][align=center][size=13px]0.221[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]60[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0041[/size][/align][/td][td][align=center][size=13px]0.222[/size][/align][/td][td][align=center][size=13px]0.214[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]80[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0060[/size][/align][/td][td][align=center][size=13px]0.216[/size][/align][/td][td][align=center][size=13px]0.209[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].[/size][size=13px]983[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0080[/size][/align][/td][td][align=center][size=13px]0.228[/size][/align][/td][td][align=center][size=13px]0.225[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]75[/size][/align][/td][/tr][tr][td][align=center][size=13px]0.0081[/size][/align][/td][td][align=center][size=13px]0.2[/size][size=13px]3[/size][size=13px]2[/size][/align][/td][td][align=center][size=13px]0.230[/size][/align][/td][td][align=center][size=13px]0[/size][size=13px].9[/size][size=13px]6[/size][/align][/td][/tr][/table][size=14px]很明显,通过随机森林方法计算出各个特征的重要性,以[/size][size=14px]0.0060[/size][size=14px]作为最低标准选择的波段用来建立[/size][size=14px]PLS[/size][size=14px]模型的效果最好。选择的波段如下图所示。[/size][align=center][font='times new roman'][size=16px]图[/size][/font][font='times new roman'][size=16px] [/size][/font][font='times new roman'][size=16px]随机森林波段选择[/size][/font][/align][size=14px] [/size][size=14px] [/size][size=14px]图中绿色背景的是通过随机森林选择的[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]波段,其波段主要分布在[/size][size=14px]908.1nm~1150nm[/size][size=14px]和[/size][size=14px]1350nm~1500nm[/size][size=14px]之间,将[/size][size=14px]125[/size][size=14px]个光谱波段降低到了[/size][size=14px]60[/size][size=14px]个,[/size][size=14px]降维效果[/size][size=14px]和模型评价效果均优于相关系数法。因此在流化床制粒过程[url=https://insevent.instrument.com.cn/t/1p][color=#3333ff]近红外光谱[/color][/url]的建模中应用随机森林法进行波段选择。[/size]
没有紫外仪器,据说可见光波段也有人做过。比色法的。
如题,在近红外定量的建模过程中,是先固定一个波段,然后在确定预处理方法,还是先确定预处理方法在选择优化波段呢?因为不同的预处理方法,软件推荐的 波段是不同的。我用的是TQ软件。大家一起交流啊。这个在写的时候又该怎么写呢。比如说我要优选预处理方法,是先按全波段优选好预处理方法,然后在优化波段吗?
替代钴源辐照 无损伤 无残毒 低能耗 操作简便2013年07月11日 来源: 中国科技网 作者: 过国忠 陆文晓 中国科技网江苏无锡7月10日电 我国科研人员历时5年多,研制出国内首台L波段10MeV/40kW工业辐照电子加速器。今天,这项由无锡爱邦辐射技术有限公司、中国科学院高能物理研究所联合承担的重大科研成果,顺利通过专家鉴定。 据了解,大功率工业辐照电子直线加速器是一类适用于综合辐照加工的当代最先进的高技术设备。用电子加速器产生的高能电子束照射可使一些物质产生物理、化学和生物学效应,并能有效地杀灭病菌、病毒和害虫,可广泛应用于工业生产中的材料改性、新材料制作、环境保护、加工生产、医疗卫生用品灭菌消毒和食品灭菌保鲜等领域。它同钴源辐照一样,具有常温、无损伤、无残毒、环保、低能耗、运行操作简便、自动化程度高、适宜于大规模工业化生产等特点。“与钴源相比,其最大优点是辐照束流集中定向,能源利用充分,辐照效率高,不产生放射性废物,具有明显的社会经济效益和不可估量的潜在价值,是目前国际上备受关注的高科技领域之一。”无锡爱邦辐射技术有限公司总经理张祥华说。 据中国科学院高能物理研究所有关科研人员透露,开发L波段10MeV/40kW工业辐照电子加速器,涉及高气压、高电压、高真空、电子学、计算机、微波技术、电气控制技术、机械设计与加工、样品机械传输装置、辐射剂量学等多学科。从2008年开始,无锡爱邦辐射技术有限公司、中国科学院高能物理研究所联合组成攻关组,在三极电子枪、L波段聚束段加速结构、恒流充电式脉冲调制器、大功率水冷系统和大功率扫描系统等关键技术获得突破,成功研制出国内首台L波段10MeV/40kW工业辐照电子加速器。经国家有关部门检测显示,束流平均功率大于45kW,微波功率到束流功率的转换效率大于75%。(记者 过国忠 通讯员 陆文晓) 《科技日报》(2013-7-11 一版)
紫外分光光度计有一项功能叫光谱波长扫描,请问是什么意思,全波段扫描和分波段扫描又是什么意思?谢谢
[font=楷体_GB2312][size=4][求助]本人因实验需要求购可见光波段的光源!(卤钨灯)具体参数如下:光源长20cm左右,直径2cm左右,功率10w左右,灯源外面套防水石英玻璃套(因为,实验中要将灯管浸泡与废水中,所以需要防水)。如有提供者,可以联系我,谢谢!本人联系方式:QQ:397122690,手机:15927320665.现就读与中国地质大学(武汉)环境学院,因实验需要,求购可见光波段灯管。如有提供不胜感激。[/size][/font]







 我要推广仪器
我要推广仪器
 下载APP
下载APP